

Fairness in AI begins with unbiased, consistent data annotation, as poor labeling can introduce bias and unreliable predictions. Using structured annotation practices, regular audits, and strong quality control helps reduce bias, improve reliability, and ensure more equitable AI outcomes.
Introduction
AI model fairness is the concept of an AI model providing people with similar results regardless of their group affiliation. The term “bias” describes the issue that occurs when the output of a model produces a result that favors one group over another based on characteristics such as gender, age, skin color, accent, location, etc.
In most instances, the initial focus is placed upon either the design of the model architecture or adjusting parameters to make the model perform better. However, in many instances, the primary factor is located further upstream in the process: the quality of the data being processed through the model.
Therefore, this article will address how implementing good data annotation practices can reduce bias and showcase techniques to improve AI model fairness ensuring reliable and equitable results.
Understanding AI Bias and Fairness in Data Annotation
AI model fairness begins with the method of labeling a model and how it learns from that labeling method; therefore, both data quality and labeling impact fairness directly. This is where data annotation services play a critical role in ensuring consistent and unbiased labeling practices.
Bias occurs in several manners:
- Bias indata-sets: the data-set lacks adequate representation of all demographic segments or scenarios and thus creates an unfair “norm”.
- Bias in labeling:inconsistencies in the labeling process due to unclear/ambiguous guidelines for labeling, and social bias.
- Bias in algorithms:the learning process exacerbates the pre-existing imbalance within the data-set and/or labeling method.
These types of bias can be extremely detrimental.
For example,
- In healthcare, a model may fail to diagnose conditions at a higher rate in one demographic segment than another if that demographic has inadequate representation within the training dataset and the labelling process is inconsistent.
- In finance, a credit scoring model may provide disparate treatment of similarly risked consumers based solely on the inequitable representation of those consumers in historic data.
- In eCommerce, a classifier may interpret products from a given geographic region as being mislabeled (or misinterpreted) simply due to differences in image content, text-based descriptions and/or categorizations used to train the model.
In reference to the term “Ethical AI”, most often referred to herein is a model that does not quietly replicate unfair patterns. More ethical models, therefore, will be developed using fairly labeled data since a model learns what we teach it.
The Role of Data Annotation in AI Model Fairness
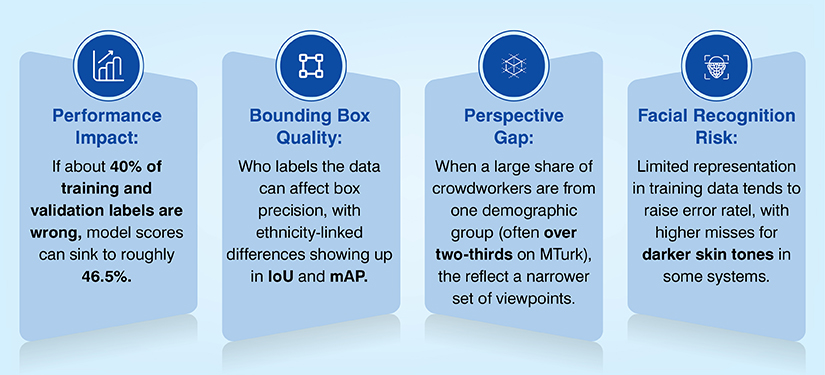
Data annotation plays a decisive role in shaping how fairly an AI system treats different groups and scenarios. When labels accurately reflect real-world diversity and complexity, models learn balanced patterns. But when annotation flaws exist, they quietly encode inequality into algorithms that appear objective.
- Mislabeling: a minority class gets tagged incorrectly more often, so the model learns the wrong signal.
- Low diversity in samples: a face model trained mostly on one skin tone performs poorly on others.
- Missing edge-case annotation: uncommon, but important, cases go untagged (night scenes, heavy accents, rare medical presentations).
Annotated datasets are the ground truth for every trained model. If they carry blind spots, then the model inherits them automatically. Addressing mislabeling, limited diversity, and missing edge cases through rigorous annotation ensures AI systems deliver equitable, dependable outcomes across all users and real-world situations.
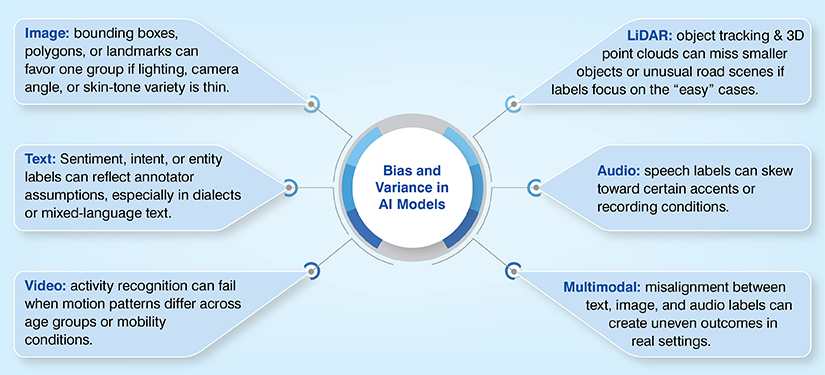
How Bias Can Slip in Across Modalities?
Best Data Annotation Practices to Reduce Bias
To avoid any bias in labeling methods you need to follow the best data annotation practices as recommended by experts. This helps you provide a well-balanced dataset to the model.
1. Comprehensive Data Coverage
Data coverage is the fundamental aspect of fairness. Different demographics, environments, devices, and edge-cases should be included in coverage. Retail examples would include product images with varying lighting, angles, background, and cultural context. If coverage is not provided, then a model may relate “quality” with a certain style of photography, or misclassify items based on their visual presentation in varying environments.
2. Annotation Consistency and Standardization
Bias is generated when two individuals interpreting the same scenario arrive at different conclusions. Guidelines for consistency and standardization are important, however, just as important are the checks that detect divergence.
Examples of practical checks used by teams to assess bias
- A shared labeling guide including both examples and counterexamples
- Random spot-checks on each batch of labels
- Measures of inter-annotator agreement (toidentify where discrepancies tend to cluster)
- Review loops forfrequently disputed labels
3. Multi-layered Annotation
There are some tasks that require more than one label to effectively capture the nuances of a task. By using multiple label types for a given task, a model can be trained to recognize subtleties rather than simply recognizing shortcuts. For example, in medical imaging, a model may require the precise boundaries of organs to be identified through landmark points or finer segmentation rather than a simple bounding box. This handles false positives and improves reliability of the model’s predictions for patients across diverse demographics.
4. Audit and Validation Processes
Two potential sources of bias that hide in plain sight are label distribution and long tail errors. These are addressed using a combination of automation and manual review. Using automated data annotation for fairness helps because automated systems can flag duplicates, outliers, and unbalanced labels that downstream reviewers can verify and correct.
Here’s a simple way to think about audits:

When working in specialized domains you need annotators who know the field-specific rules and constraints. Medical annotators can minimize misinterpretations of scans and notes in the health care field, while individuals familiar with loan documents and terminology related to transactions can provide more accurate labeling in the financial sector.
- Domain-SpecificExpertise
When working in specialized domains you need annotators who know the field-specific rules and constraints. Medical annotators can minimize misinterpretations of scans and notes in the health care field, while individuals familiar with loan documents and terminology related to transactions can provide more accurate labeling in the financial sector.
This is one reason why many organizations choose to utilize data annotation services for Ethical AI when the stakes are high: the organizations want reliable processes, domain-specific training, and quality governance.
Each of the above five categories share the common goal of providing data labeling to minimize bias by minimizing ambiguity, increasing coverage, and identifying divergence in the labeling process as soon as possible.
Industry-Specific Data Annotation Use Cases

Measuring Annotation Impact on AI Fairness
You cannot enhance fairness without measuring it. Most teams measure fairness using metrics such as Demographic Parity (do groups receive similar results?) and Equal Opportunity (do groups achieve similar true positive rates for a relevant outcome?).
If either of these metrics change after labeling has been revised, additional coverage has been added, or guidelines have become stricter, there is evidence that the method of annotating data was effective. This process runs continually.
As new data arrives, the team audits the data, updates labels and reviews fairness metrics. Over time, this sequence of tasks becomes one of the most practical strategies for ensuring fairness of the AI models.
Conclusion
The truth is that poor labeling can introduce bias and unreliable predictions. Your AI model learns from more clearly defined, more representative, and thus more reliable, ground truths.
High-quality data annotation cannot be achieved by a magical tweak to the AI model. Disciplined data annotation best practices like broad coverage, strict standards for labeling, layering of labels, regular audits, and sufficient subject matter expertise will make your model less bias and with greater accuracy.




