Imagine handing a chef spoiled ingredients and expecting a great meal. It doesn’t matter how skilled they are — the outcome is already compromised before they touch the stove.
That’s exactly what’s happening in most AI projects right now. Teams are spending real money on models, agents, and infrastructure, but they’re skipping the one thing that determines whether any of it works: the quality of the data underneath it.
The numbers back this up. According to Gartner, 85% of AI projects fail due to poor data quality or lack of relevant data. Informatica’s CDO Insights 2025 survey puts data quality and readiness at the top of the obstacle list, cited by 43% of respondents and ranking it above lack of technical maturity and shortage of skills. Yet most teams are still treating data as an afterthought.
The assumption nobody’s questioning
When AI starts producing bad answers, the instinct is usually to blame the model. Teams go looking for something smarter, something newer, something with a better benchmark score. But that’s almost never the actual problem.
What’s actually happening is that companies are wiring together every data source they have — CRMs, call transcripts, Google Drive, product telemetry — dumping it all into a storage bucket, indexing it into a knowledge base, layering on vector search, and expecting accurate answers to come out the other side. On paper it looks powerful. In practice, it produces results that are confidently, fluently wrong.
When “more data” makes things worse
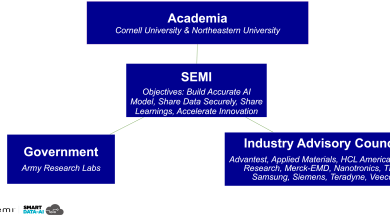
Here’s a pattern that plays out constantly. A team builds an internal AI assistant by pulling from multiple systems. But each system is telling a different story. The CRM reflects what should be true. Call transcripts reflect what was said. Documents reflect what was true at some point. Telemetry reflects what actually happened. There’s no shared schema, no hierarchy, no agreed-upon source of truth.
So when a user asks a question, the AI does the only thing it can. It guesses. Not randomly, but probabilistically. It selects the most plausible answer based on conflicting signals. And that’s where things quietly fall apart.
This isn’t hypothetical. MIT research identifies what they call “the 80/20 problem” in enterprise AI: corporate databases capture roughly 20% of business-critical information in structured formats — the neat rows and columns AI systems process easily. The remaining 80% lives in unstructured data: email threads, call transcripts, meeting notes, contracts. That’s usually where the most decision-critical intelligence sits, and most AI systems never reconcile it. The fragmentation runs deeper than you’d expect. The same customer might appear as “Acme Corp” in the CRM, “Acme Corporation” in email, “ACME Inc.” in contracts, and just “Acme” in call transcripts. Without explicit entity resolution, the AI treats these as different entities entirely.
A mid-market software company went through exactly this. They had comprehensive data coverage across every customer touchpoint, more context than most teams dream of, and their AI assistant still managed to contradict itself depending on which documents happened to rank highest in retrieval. Their sales team stopped trusting it within six weeks. All that infrastructure, and the bottleneck was the data going in.
You can’t prompt your way out of this
When the answers start going sideways, the next instinct is to fix the prompts. So teams start layering in instructions: prefer CRM data unless it conflicts with the transcript, ignore documents older than 90 days unless they’re still relevant, weight telemetry more heavily for product questions. At some point the prompt becomes a fragile rules engine, and even then it still fails.
The reason is structural. Current AI models determine likelihood, not truth. They’re pattern matchers operating over whatever you’ve given them. A better prompt can adjust which patterns get weighted, but it can’t resolve genuine conflicts in the underlying data. It just masks them, adds complexity, and introduces new failure modes. In this case, prompting can act as a multiplier that makes good data better and bad data worse.
What you’re actually asking your AI to do
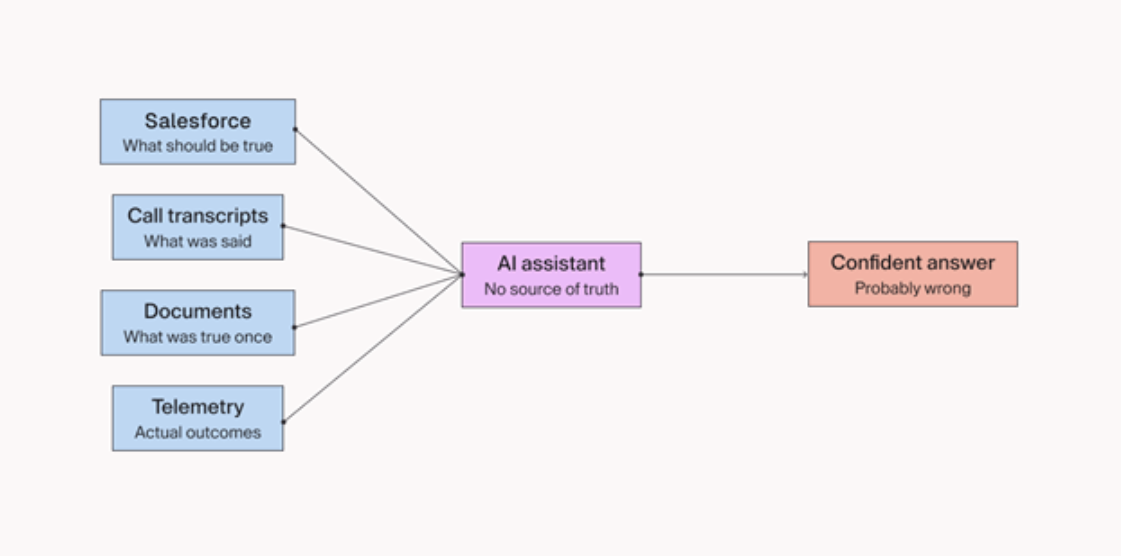
Think about being dropped into a massive storage unit filled with hundreds of unlabeled boxes. Some are labeled correctly. Some are mislabeled. Some just say “documents” or “misc.” Many contain duplicates, outdated versions, things that were true once but aren’t anymore. Someone tells you to find a specific book — you don’t know the exact title, you only know roughly what it’s about, and you’re not even sure it exists in there. So you start opening boxes, one by one, hoping you’ll recognize it when you see it.
That’s your retrieval pipeline. Vector search doesn’t organize the boxes, it just lets you search through the same mess faster. If the content is poorly labeled, inconsistently structured, and full of contradictions, retrieval becomes a guessing game. The AI finds the most likely match, returns it with full confidence, and moves on. Whether it’s actually the right answer is a separate question entirely.
Informatica frames this well: data quality management and governance for RAG systems must be built into the foundation of AI projects. Even a single erroneous or incomplete entry can produce misleading responses that erode user trust.
What a different approach looks like
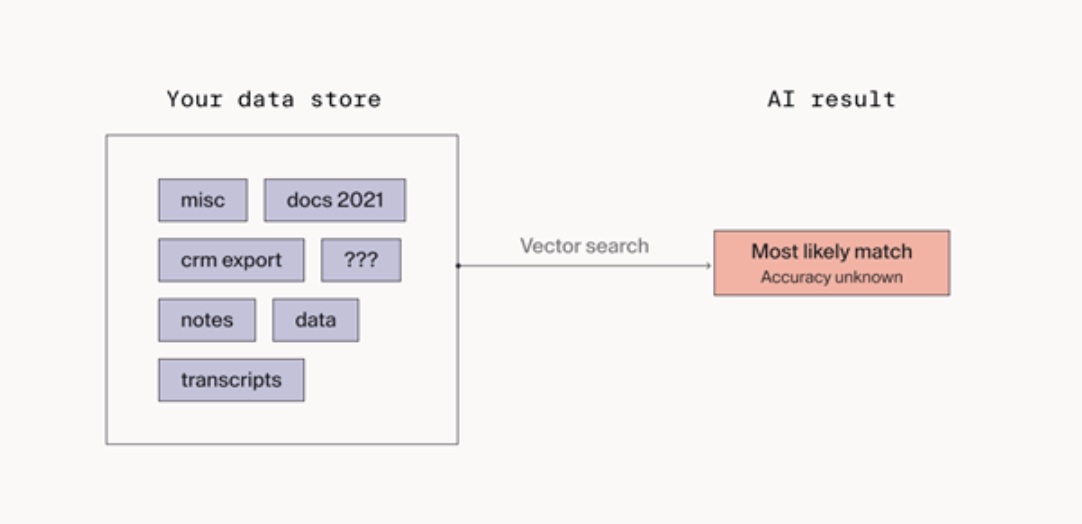
The teams getting reliable results from AI aren’t necessarily using better models. They’re doing something less glamorous: they’re treating data quality as a core product requirement before they write a single line of AI code.
That means defining clear schemas upfront. It means tagging and categorizing content so that context is explicit rather than inferred. It means deciding, deliberately, which source wins when two sources conflict — and encoding that decision somewhere the AI can actually use it. It means deduplicating, normalizing, and auditing what’s in the system before trusting the system to answer questions about it.
One team that did this found something counterintuitive: they indexed significantly less data than they had available, and their results got dramatically better. They stopped treating comprehensiveness as a virtue and started treating curation as one. The AI wasn’t guessing anymore. It was referencing intentional knowledge rather than accidental accumulation.
McKinsey’s 2025 AI survey confirms this pattern at scale: organizations reporting significant financial returns are twice as likely to have redesigned end-to-end workflows before selecting modeling techniques — and the winning programs earmark 50–70% of their timeline and budget for data readiness, not model selection.
The question worth asking before you go further
There’s a step most teams skip entirely: pausing to audit what you have before ingesting more of it. Nobody talks about this because it’s not exciting. But sometimes the right move is to stop adding data sources and spend two weeks understanding what’s actually in the ones you already have. Which records are stale? Which systems contradict each other? Which source is authoritative when they disagree? Answering those questions before building is almost always faster than debugging the answers after.
Early in my career as an automation consultant, the first thing I’d ask a client wasn’t “what do you want to automate?” It was, “what are you actually trying to solve?” We didn’t touch a keyboard until we had a real answer. The same discipline applies here. The teams that skip this step pay for it later.
A useful diagnostic: ask your team “what’s the source of truth for customer health data?” If three people give three different answers, your AI will too.
Gartner puts a number on the cost of skipping this step: through 2026, they predict organizations will abandon 60% of AI projects that are unsupported by AI-ready data.
The honest takeaway
We’re in a moment where building with AI is the easy part. The tooling is mature, the APIs are accessible, and you can have something running in an afternoon. The hard part most teams get stuck on is getting the data right.
AI doesn’t create truth. It reflects whatever you give it. If your data is messy, fragmented, and inconsistent, your AI will be too. Only faster and more confident about it. And a system that’s wrong with confidence is considerably more dangerous than one that’s quietly uncertain.
The companies winning with AI aren’t the ones with the most data or the best models. They’re the ones who decided, early, that data quality wasn’t someone else’s problem.
Gartner (2025) — AI-ready data & abandonment predictions https://www.gartner.com/en/newsroom/press-releases/2025-02-26-lack-of-ai-ready-data-puts-ai-projects-at-risk
Informatica CDO Insights 2025 — Data quality as top obstacle https://www.informatica.com/blogs/the-surprising-reason-most-ai-projects-fail-and-how-to-avoid-it-at-your-enterprise.html
MIT Project NANDA — The GenAI Divide report https://mlq.ai/media/quarterly_decks/v0.1_State_of_AI_in_Business_2025_Report.pdf (PDF of the full report — the MIT NANDA homepage is at https://nanda.media.mit.edu)
McKinsey Global AI Survey 2025 — Workflow redesign & data readiness https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
Capital One AI Readiness Survey 2024 — Data quality as primary barrier https://www.capitalone.com/tech/ai/ai-readiness-survey/