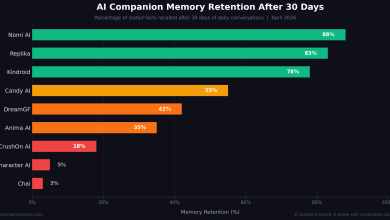
Most coverage of AI in video focuses on generation. Tools that turn a prompt into a clip, an avatar into a presenter, a stock library into a montage. It is the visible, demo-friendly half of the story, and it dominates conference stages and product launches. The half that nobody films is what happens after the record button stops.
That second half is where most teams actually spend their time. A recording is not a deliverable. It is raw material that has to be turned into something a customer, employee, or learner can use. And the workflow between “we have a video” and “the video is doing its job” is where the real cost of video content lives.
This is the post-recording workflow gap. It is unglamorous, fragmented, and almost invisible in the AI conversation. It is also where AI is quietly producing the biggest gains.
What the post-recording workflow actually looks like
If you have ever tried to ship a single product walkthrough to a global audience, you already know the shape of the problem. A five-minute screen recording becomes a multi-day project the moment anyone needs more than the raw file. There is transcription to clean up, captions to time, translations to commission, voiceovers to record, screenshots to extract, and a written version to draft for the people who would rather skim than watch.
Each of these steps used to be a separate tool, a separate vendor, and often a separate person. Captions came from one service, translation from another, voiceover from a third, documentation from a writer who was not in the original meeting. The handoffs added cost, but they also added something worse: drift. By the time the written guide existed, the product had moved on, and the version in the video no longer matched the version in the docs.
For a long time this was just the price of doing video. Teams accepted it because the alternative was not making the video at all.
Why generation got the spotlight
It is easy to see why generative video grabbed the attention. A single prompt producing a usable clip is a magic trick. It photographs well in a keynote, it lends itself to viral demos, and it lines up with a familiar narrative about creative work being automated.
Post-recording work is the opposite. It is plumbing. Nobody wants to watch a demo of caption timing, translation memory, or screenshot extraction. There is no twenty-second clip that captures the relief of not having to coordinate four vendors to ship one tutorial in three languages.
But the economics tell a different story than the demo reels. For most teams that depend on video, generation is not the bottleneck. They already have plenty of source material. What they lack is a way to turn it into the ten or fifteen artifacts a single recording could become if the workflow did not collapse under its own weight.
What is actually changing
The shift that matters is not that one task in the chain got automated. It is that the chain itself is being collapsed into a single pass.
A modern post-recording workflow can take an uploaded video and produce, from one source, a transcript, accurate captions, translated subtitles in a dozen languages, a voiceover in a different voice or language, a written article, a step by step guide with extracted screenshots, and a knowledge base entry. The old workflow ran these steps in sequence with a human handoff at each transition. The new one runs them in parallel, from the same source of truth, with the human stepping in only to review.
This is the gap my own company, Vidocu.ai, was built to close. We started from the observation that the teams making the most video had the least time to do anything with it, and that almost every tool on the market automated one slice of the chain while leaving the others untouched. The interesting engineering problem was not any single transformation. It was treating the recording as a single source and producing every downstream artifact from it without losing fidelity between steps.
This sounds like a small process improvement. In practice it changes the unit economics of video content. When one recording can become fifteen artifacts at near zero marginal cost, video stops being a thing you make and starts being a thing you mine. The recording is no longer the deliverable. It is the source.
The implications for teams that depend on video
The teams feeling this shift first are not the ones you might expect. Hollywood is not the early adopter here. The early adopters are customer support teams that need to localize a help center, training teams that need to onboard remote employees in five languages, product marketers who need to repurpose a single demo into a webinar, a tutorial, a blog post, and a knowledge base article.
For these teams, the post-recording gap was the limiting factor on how much video they could justify making. If a single recording cost a week of post-production work, you only made the videos that absolutely could not be written. Once that cost approaches zero, the calculus inverts. Video becomes the cheapest, fastest way to produce content, because the recording is the only part that requires a human to be in the loop.
The downstream effect is a quiet expansion of what counts as documentation, training, and marketing material. Internal Looms become onboarding guides. Sales calls become case studies. Webinars become evergreen knowledge base entries. None of this requires a generative model. All of it requires the workflow gap to close.
The mindset shift
The harder part of this transition is not technical. It is conceptual. Teams that have spent years thinking of video as a finished artifact have to learn to think of it as raw material. The recording is not the end of the project. It is the beginning of a fan-out into a dozen formats, each tuned to a different audience, channel, and language.
This sounds obvious in the abstract. It is much harder in practice, because most organizations are structured around the old model. The video team makes videos. The docs team writes docs. The localization team handles translation. Each owns one slice of the chain, each has its own tools, and each measures success against its own slice.
When the workflow collapses, those boundaries become a liability. The team that figures out how to treat one recording as the input to a unified output stream produces more, faster, in more languages, than the team that still has four vendors and a hand-off doc. The org chart becomes the bottleneck, not the technology.
What to watch for
If you are evaluating AI tools for your video workflow, the question worth asking is not which step in your current process can be automated. It is whether the steps still need to be separate at all. The most useful AI in video right now is not the kind that generates a clip from a prompt. It is the kind that quietly removes the seams between the things you already do after recording.
The signs of a real shift, as opposed to a marketing one, are practical. Does the tool work from your real source material, not a curated demo file. Does it handle the messy parts: long recordings, multiple speakers, accents, technical vocabulary, screenshots that need to be extracted at the right moment. Does it produce outputs your team can actually ship without a second round of cleanup. Does it close the gap between the recording and the final artifact, or does it just automate one slice and leave the rest of the chain intact.
The teams that get this right will not have a flashier video output. They will have a quieter operation, a smaller stack, and a much larger library of usable content from the same number of recordings.
The story worth covering
The AI video story most worth telling right now is not about generation. It is about the unglamorous, expensive, fragmented work that happens after the camera stops, and how that work is finally being treated as one problem instead of seven.
It will not produce the demo reels. It will produce something more interesting: a generation of teams that can ship video at the speed they currently ship text, in any language, without hiring a post-production department to do it.
That is the part of the AI video revolution that is actually arriving. It just does not photograph well.
About the author
Daniel Sternlicht is the founder of Vidocu.ai and Common Ninja. He writes about AI workflows, video, and bootstrapped SaaS.