
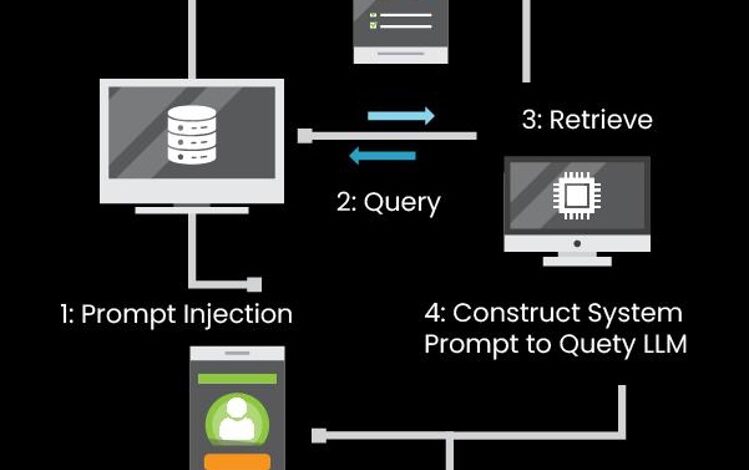
Among all the potential threats to the structure and functioning of large language models (LLMs), the most concerning threat would be prompt injection attacks. These are the types of attacks where control is gained over the large models by modifying instructions and input by the users, leading to abnormal operations or the disclosure of confidential information from the disallowed databases.
The NIST Institute in the year 2024, judging from its statements, indicates, “The principal threat to the security of generative AI is believed to be indirect prompt injection, which can be the focus of endurance and broad-based detection, but not recovery, practices” has made it evident that measures should be put in place to minimize LLMs from such attacks.
What Is a Prompt Injection Attack?
Linguistic components of computers have many talents; however, prompt injection attacks exist that modulate natural language processing initiation devices for undesirable outputs. These attacks arise when an attacker intentionally designs a deceptive prompt to manipulate the language model.
This technique uses the model’s inability to comprehend the negative intent intended to inflame harm or create faults within the model.
One potential concern is the exposure of systems that link language models with critical programs or data manipulation pipelines to such attacks.
If not controlled, they could allow unauthorized persons to access the restricted functions, adversely affect the outputs, or misrepresent information, threatening the systems’ security and the data’s integrity.
How do these Attacks Exploit Vulnerabilities in LLMs?
These attacks use inherent vulnerabilities in LLMs, which are supposed to follow highly accurate human language commands. Attackers use this feature to circumvent security measures by hiding malicious instructions within natural language.
Because LLMs rely on patterns learned from large volumes of text data, they can occasionally misread prompts or fail to identify carefully veiled commands, emphasizing the importance of effective defenses to detect and mitigate these attacks.
Types of Prompt Injection Attacks
Prompt injection attack is a term that has different subcategories, some of which include prompt injection attack.
1. Direct Prompt Injection Attacks
For direct prompt injection to the language model, customized prompts sent from outside the model are forcibly delivered in a direct prompt injection attack. The attackers don’t produce input that does not contain any profit directly; rather, they exploit inputs containing bad or tricking instructions for diverse results.
This kind of attack changes how the model is expected to respond by making the model’s core functioning mentality turn toward the given input.
Direct attacks are a prime example of what focusing means. Many things in computers sometimes get lost or buried under the doesn’t matter to do a single task, and that’s where the force and the language model are directed. These attacks necessitate strict input checks and security measures to thwart the manipulation attempts.
2. Using Indirect Prompt Injection Attacks to Mount an Attack on the System
Contrary to the provided example of creating a direct prompt injection attack, the external context or the environment is targeted in indirect prompt injection attacks. This is because an attacker intervenes by explaining how the model interacts with surrounding information, which is a part of the model itself.
The occurrence of these changes is also frequent in dynamic systems where there are external data sources on which the models rely.
If the compromise, as in the case of this attack, is not made to the prompt but occurs within its context, the method can be difficult to detect. Monitoring the network and protecting the data streams that are supplied to the model is paramount in the case of such attacks.
3. The Attacks Involving Stored Prompt Injection
In this type of attack, also called stored prompt injection, an attacker embeds instructions or bad words embedded in the stored language data, later sending it to the model. User profiles, past exchanges, and other resources that engage with the language model periodically can all be considered examples of this data.
Because the instructions are embedded, this approach is persistent and can be exploited repeatedly whenever the data is accessed. To counter such attacks, proper data curation and validation mechanisms must be employed in that the saved content cannot act as a channel for prompt injection attacks.
4. Prompt Leak Attacks
Prompt leaking attacks employ the twist of the reply to a language model prompt to extract information of a private and confidential nature embedded in the model. Such meaningful input might allow attackers to gather snippets of internal data or system configurations that the model operations had accidentally exposed.
These attacks utilize the predictive ability of the model to fetch some underlying system patents or a fraction of the training corpus. Such information leaks may be caused by limiting the model’s reach, employing anonymization features, and auditing response behaviors to uncover unauthorized information leaks.
Proven Strategies for Mitigating Prompt Injection Attacks
The employing setups should use technical measures and an appropriate course of action to shield large language models from prompt injection attacks. The main approaches include:
1. Input Sanitization and Filtering
To achieve the LLM malice prompt exploitation, which intends to compromise the underlying model, the steps taken to achieve this type of strong input include sanitization.
There are various ways capable of helping eliminate harmful data from the system, for example, by employing a whitelist, escaping metacharacters, especially in programming, and by employing regular expressions to screen patterns. For example, the input may be encoded, or some dangerous characters may be escaped to prevent code injection attacks.
2. User Authentication and Access Control
Access is not flexible because system access is available only to certain users that have access to the LLMs via strict user authentication. It’s best to use MFA, and role-based access control (RBAC) to prevent the illegal prompt injections.
Companies can mitigate the risk of rogue input from non-trusted parties by providing the appropriate permissions according to roles.
3. Implementing Contextual Awareness in LLMs
Improving contextual awareness lets LLMs know which requests are legitimate and which are not. For open security, trained models of the machine can be embedded into the system which will identify highly attacker-like features using prompt or prompt injection.
For example, it may be possible to build models to describe situations where users will likely guess, so this will help detect and prevent such prompt injection attacks.
4. Regular Audits and Monitoring
Constant monitoring and checking of the LLMs’ activities is critical in detecting and removing cases of attempts at prompt injection. Recording user input and model output makes checking for irregularities in real-time possible.
In addition, regular penetration testing may identify weaknesses that enable the timely deployment of software patches and improve the overall security posture of an organization.
Using these approaches in combination can help organizations mitigate the risk of their exposure to prompt injection attacks and not affect the reliability and stability of the LLMs.
Best Practices for Securing LLM Deployments
Numerous techniques must be incorporated into all the strategies for securing LLM installations. Such practices include:
1. Rate Limiting and Quotas
Regarding DoS, a rate limitation is quite useful since it stops a user or a system from sending more than allowed requests in a set time, thus enabling useful applications and averting excessive requests that would otherwise inundate the server.
Setting thresholds helps companies stop hostile actors from overwhelming the system. For example, installing application front-end hardware to evaluate incoming data packets and block suspicious flows can improve security.
2. Utilizing Red Teaming and Penetration Testing
Red teaming entails simulating adversarial assaults to identify vulnerabilities in LLM systems. This proactive technique enables firms to identify flaws that are not obvious through traditional testing. For example, red teaming exercises can uncover possible security flaws in LLM applications, allowing for rapid correction.
3. Layered Defense Models
A defense-in-depth technique entails deploying numerous security measures to safeguard LLM deployments. The approach allows one to fail; as he does, other security layers will be available to protect and seal the system.
For example, building a strong security culture is possible by policymaking firewall I.D.S. and conducting regular security checks.
By applying these policies, enterprises secure their LLM deployments and effectively alleviate risk-related concerns while ensuring dependable performance.
Conclusion
Reducing prompt injection attacks on large language models requires an approach that integrates several elements, including cleaning the input, verifying users, having some context awareness, and continual supervision. Applying rate limiting, penetration testing, and layered defensive models enhances these defenses and lowers the model’s vulnerabilities, thus improving its security.
As LLMs are taken into more sensitive tasks, security standards must be standardized across the industry. Businesses can mitigate the increasing menace to LLMs by adopting best practices across the industry and, therefore, make it safe for AI-based applications.


