
The Human Capital Question
Joshua Rothman’s recent New Yorker essay poses a deceptively simple question about artificial intelligence: Is it a bubble, or is it genuinely transformative? His answer threads a sophisticated needle. AI isn’t primarily about worker replacement, he argues, it’s about human capital multiplication. The technology accelerates learning, increases capability, and enables people to accomplish tasks they previously couldn’t. Companies that recognize this will thrive; those that focus narrowly on headcount reduction will miss the real value.
This framework is both analytically powerful and empirically grounded. Rothman demonstrates it through his seven-year-old son learning to code increasingly sophisticated games with AI assistance, from Pong to Tron to Asteroids, in a timeline that would have been impossible a few years ago. The child didn’t replace a game developer. He became one, faster.
The framework is correct. It’s also architecturally incomplete.
Rothman treats “AI” as a unified technology with consistent properties and predictable limitations. But recent evidence from high-stakes domains, particularly healthcare, reveals that architectural choices determine whether AI multiplies human capital or amplifies risk. The same systems that enable rapid learning in low-stakes contexts produce catastrophic failures in high-stakes ones, not because of insufficient capability but because of fundamental architectural mismatch.
This paper examines why Rothman’s human capital framework requires an architectural layer he doesn’t address, what that architecture looks like in practice, and why current investment patterns are systematically misaligned with sustainable value creation.
Stakes-Dependent Architecture Requirements
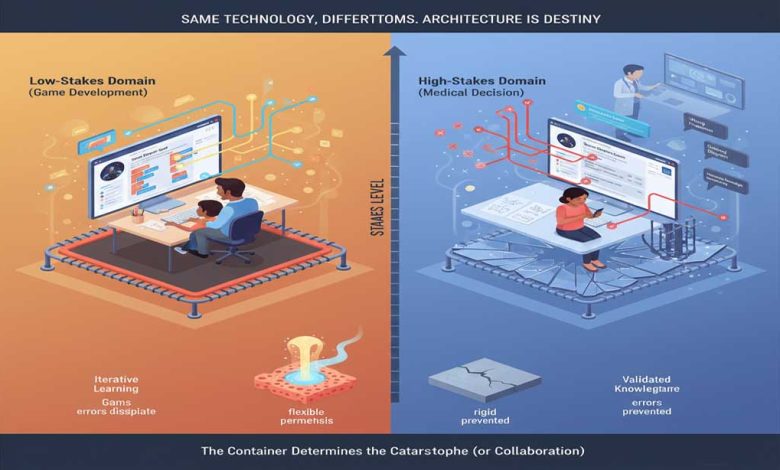
Consider two scenarios involving the same technology. In the first, a child uses ChatGPT to learn game development, progressing from simple projects to complex ones over several weeks. When the AI suggests incorrect code, the game doesn’t work. The child iterates. Learning accelerates. Human capital multiplies.
In the second scenario, a patient uses ChatGPT to interpret medical test results, receiving a confident diagnosis of a pituitary tumor. An MRI reveals no tumor. The AI was wrong. The patient experienced unnecessary anxiety, medical procedures, and time wasted pursuing incorrect diagnoses.
Same underlying technology. Radically different outcomes. The difference isn’t capability, it’s stakes.
The New York Times recently documented patients uploading medical records to ChatGPT at scale, obtaining diagnoses with documented accuracy rates below fifty percent, and proceeding with medical decisions based on these outputs anyway. This isn’t an edge case. It’s a systematic architectural failure enabled by economic incentives that optimize for market capture rather than domain-appropriate reliability.
The distinction Rothman’s framework misses is this: human capital multiplication requires tools that reliably enhance capability. In high-stakes domains, unreliable tools don’t multiply capability, they amplify risk.
The Epistemological Structure of Stakes
Low-stakes and high-stakes domains differ not just in the severity of consequences but also in their epistemological requirements. Low-stakes domains like game development, creative writing, and initial research exploration tolerate iterative error correction through rapid feedback. They allow learning through failure without severe consequences. They accept synthesis from diverse, unvalidated sources. They work with confident generation even when the system is uncertain. They rely on user-driven verification of outputs.
High-stakes domains like medical diagnosis, structural engineering, legal compliance, and financial regulation demand something fundamentally different. They require error prevention rather than correction. They need validation before deployment. They must synthesize only from verified, authoritative sources. They demand explicit uncertainty quantification. They need traceable accountability for decisions.
Current large language models are architecturally optimized for low-stakes domains. They generate plausible responses from statistical patterns in training data. They synthesize information from uncontrolled, mixed-quality sources. They produce confident outputs regardless of underlying uncertainty. They lack mechanisms for tracing outputs to validated sources. They cannot distinguish between authoritative and unreliable information.
This architecture succeeds in low-stakes contexts because rapid iteration and user verification provide feedback loops that catch errors. The child coding games quickly discovers when AI suggestions don’t work. The feedback is immediate, the consequences are bounded, and learning accelerates.
In high-stakes contexts, these feedback loops fail catastrophically. Medical errors don’t announce themselves immediately. A patient receiving incorrect diagnostic advice may not discover the error for months, or until permanent harm has occurred. Structural engineering calculations that look plausible may fail only when the bridge collapses. Legal advice that sounds authoritative may be revealed as incorrect only when litigation fails.
The epistemological mismatch is fundamental: systems designed for rapid iteration in low-stakes environments are being deployed in high-stakes environments that require validation before consequences.
The Accountability Gap
Rothman correctly identifies that AI “cannot be held accountable and cannot learn on the job.” This observation points toward the architectural requirements that he doesn’t fully develop.
I pay malpractice insurance for my clinical decisions. OpenAI does not. This accountability asymmetry shapes system design in ways that go beyond liability protection; it reveals fundamentally different design philosophies.
When you build systems knowing that wrong answers carry consequences you personally bear, you design differently. Systems built with accountability operate only on validated knowledge sources. They make uncertainty explicit rather than generating confident synthesis. They refuse to answer rather than guess outside validated domains. They trace all outputs to specific authoritative sources. They fail safely by acknowledging knowledge gaps.
Systems built without accountability generate responses based on whatever patterns emerged during training. They optimize for appearing helpful over being correct. They synthesize plausible-sounding answers when actual knowledge is absent. They externalize verification responsibility to users. They fail dangerously by confidently generating incorrect information.
The distinction isn’t about model capability; it’s about architectural philosophy driven by who bears consequences when systems fail.
Constrained Competence as Architectural Alternative
The alternative architecture I’ve previously termed “constrained competence” addresses the epistemological requirements of high-stakes domains through three structural principles that work together as a coherent system.
The first principle is control of the knowledge source. Rather than training on uncontrolled corpora, you limit input sources to validated, authoritative content within specific domains. For medical AI, this means clinical guidelines, peer-reviewed research, evidence-graded recommendations, and systematically curated knowledge bases. Critically, the system cannot, by architecture, generate responses outside its validated knowledge domain. This isn’t a limitation to be overcome; it’s a design requirement that prevents the synthesis of plausible-sounding misinformation.
The second principle builds explicit uncertainty into the architecture itself. Rather than computing confidence scores from model internals, you build uncertainty quantification into the knowledge representation. The system distinguishes between high-quality evidence from systematic reviews and randomized trials; moderate evidence from observational studies and case series; expert consensus without substantial evidence; and known knowledge gaps where current evidence is insufficient. Uncertainty isn’t failure, it’s honest communication about the state of domain knowledge.
The third principle embraces modular specialization with standardized interfaces. Rather than a single massive model attempting all tasks, you build specialized components that excel in specific domains and connect via standardized interfaces. For example, mental health resource navigation might consist of separate specialized models for different regions, such as Chicago, Detroit, rural Montana, and tribal lands, each with validated local information, all connecting through universal crisis resources like the 988 hotline and national suicide prevention resources.
This modular architecture enables domain-specific validation of each component, independent updates as information changes, thorough testing within bounded domains, clear accountability for each component’s outputs, and infinite assembly configurations while maintaining reliability. The architectural metaphor is Lego blocks rather than a monolithic structure. Each block has defined capabilities and standard connectors. Complex systems assemble from validated components rather than emerging from uncontrolled synthesis.
Why Investment Patterns Are Misaligned
Rothman asks whether AI represents a bubble. The answer depends on which architecture we’re discussing.
Current venture capital overwhelmingly funds general-purpose models optimized for market capture: one model for everything, maximum user base, monopoly positioning. This follows a Walmart strategy, serving everyone mediocrely through scale rather than excellence through specialization. The economic logic is clear. A company building “the AI that does everything” can pursue monopoly returns. A company building “excellent mental health resource navigation for Chicago” cannot scale to trillion-dollar valuations.
But in high-stakes domains, the Walmart approach fails structurally, not just on quality metrics. You cannot build a reliable medical AI by training on random internet text and adding governance layers. The architectural foundation, synthesized from uncontrolled sources, is incompatible with the epistemological requirements of high-stakes medical decisions.
This creates a fundamental misalignment: investment flows toward architectures optimized for market capture, which are structurally unsuited for the high-stakes domains where AI could make the most value. The bubble is in general-purpose models trying to do everything. The sustainable value is in specialized architectures designed for specific stakes levels.
Human Capital Multiplication Requires Appropriate Architecture
Returning to Rothman’s framework: AI as human capital multiplier is analytically correct but architecturally underspecified.
In low-stakes domains, general-purpose AI successfully multiplies human capital because rapid feedback catches errors quickly, consequences of mistakes are bounded, learning accelerates through iteration, and users can verify outputs directly. The child learns to code faster. The writer drafts more efficiently. The researcher explores topics more quickly. Human capital multiplies because the architecture matches the epistemological requirements of the domain.
In high-stakes domains, only appropriately architected AI multiplies human capital because feedback on errors may come too late to prevent harm, consequences of mistakes can be catastrophic, validation must precede deployment, and users often cannot verify outputs independently. A physician using content-controlled AI that operates within validated clinical guidelines becomes genuinely more capable. Access to evidence-based recommendations accelerates decision-making. Explicit uncertainty improves clinical judgment. Traceable sources enable verification.
A physician using general-purpose AI trained on uncontrolled internet text doesn’t multiply capability; they outsource judgment to a system that guesses confidently. This doesn’t enhance human capital. It substitutes unreliable automation for professional expertise.
The same framework, human capital multiplication, requires radically different implementations depending on the stakes.
The Scientific Incompleteness Rothman Identifies
Rothman observes that AI differs from previous technological disruptions in its scientific incompleteness. We don’t yet understand how to build generally intelligent systems. We don’t know whether scaling the current architecture will produce substantially greater capability. We disagree on fundamental questions about what intelligence means.
This observation points toward a crucial implication he doesn’t fully develop precisely because AI is scientifically incomplete; we should build architectures that acknowledge and work within current limitations rather than assuming future breakthroughs will solve fundamental problems.
Constrained competence accepts current limitations as design parameters. Systems can’t truly reason, so they operate only on validated knowledge. Models can’t assess their own reliability, so you build uncertainty into knowledge representation. General intelligence isn’t achieved, so you specialize rather than generalize. Accountability can’t be algorithmic, so you maintain human responsibility.
This isn’t pessimism about AI’s future. It’s engineering discipline about AI’s present.
The alternative, deploying systems in high-stakes domains while assuming future improvements will fix current inadequacies, is the actual bubble. It’s venture capital funding based on speculation about capabilities that don’t yet exist, applied to architectures fundamentally unsuited for the domains they’re entering.
What This Means for Research Priorities
If human capital multiplication is the actual value proposition for AI, and if appropriate architecture depends on domain stakes, then research priorities should shift from pursuing ever-larger general-purpose models toward building specialized systems with controlled knowledge domains. Instead of optimizing for appearing helpful over being correct, we need architectural mechanisms for honest uncertainty. Rather than creating synthetic benchmarks disconnected from real-world stakes, we should develop validation frameworks appropriate to stakes levels. Instead of building architectures that externalize accountability to users, we need systems that trace outputs to authoritative sources.
The emphasis should move toward modular components with standardized interfaces, toward safe failure modes that acknowledge knowledge gaps, toward systems designed not for maximum capability but for appropriate capability within defined boundaries. The research agenda shouldn’t be “build AGI” or even “build more capable models.” It should be “build architectures appropriate to the stakes of their deployment domains.”
Conclusion: The Stakes Determine the Architecture
Rothman’s human capital framework is correct: AI’s value lies primarily in enhancing workers rather than replacing them. Companies that recognize this will outperform those focused narrowly on headcount reduction.
But this framework is incomplete without an architectural layer that accounts for stakes-dependent requirements. The same technology that successfully multiplies human capital in game development fails catastrophically in medical diagnosis, not because of insufficient capability but because of architectural mismatch with epistemological requirements.
Current investment overwhelmingly funds general-purpose architectures optimized for market capture through scale. These architectures succeed in low-stakes domains where rapid iteration and user verification provide feedback loops that catch errors.
In high-stakes domains, these same architectures produce systematic failures. Medical patients receive incorrect diagnoses. Engineering calculations appear correct until structures fail. Legal advice sounds authoritative until litigation reveals errors.
The sustainable path forward requires matching architecture to stakes. For low-stakes exploration, general-purpose models enable rapid learning. For high-stakes decisions, specialized, validated, content-controlled systems ensure reliability. The distinction isn’t about limiting AI’s potential; it’s about building systems whose architecture matches the epistemological requirements of their deployment domains.
The AI bubble is in trillion-dollar investments in architecture unsuited for high-stakes domains. The AI value lies in specialized systems designed to meet domain requirements.
Rothman asks whether AI will transform the world. The answer depends on whether we build architectures that reliably multiply human capital or confidently amplify errors. For coding games, the difference is pedagogical. For healthcare, the difference is life and death. For the AI industry, the difference determines which investments create sustainable value and which evaporate when hype meets reality.
The stakes determine the architecture. And architecture determines whether we multiply capability or amplify risk.



