
The Unravelling of the Subscription Model
In a span of weeks in early 2026, the AI industry unwound the flat-rate subscription model that had made experimentation feel safe. Per-message billing became per-token billing [1]. Always-on coding assistants stopped being bundled amenities and turned into metered consumption [2]. Enterprise contracts shifted from predictable annual fees to dynamic usage-based models that reset at renewal. The convergence was not coordinated, but the message was uniform: every token now carries a price, and the era of subsidized curiosity is over.
The industry narrative has focused on falling unit costs. Per-token inference prices have dropped sharply year-over-year, a genuine and significant decline. Yet organisations are watching their total AI bills climb. A single multi-agent workflow can consume 50,000 to 500,000 tokens before producing output, and always-on assistants process millions of tokens per developer per day [3]. Hidden retrieval, embedding, and retry costs add 40 to 60 per cent on top of the raw inference bill. This is the “token cost illusion”, declining unit economics disguising runaway total consumption [3].
A meter does more than measure. It reshapes behaviour. When every speculative prompt, every alternate reasoning path, and every abandoned experiment appears as a line item, engineering teams self-censor [4]. They trim reasoning steps not because those steps lack value, but because the dashboard brands them as waste. The token economy becomes a tax on the habits that produce genuine breakthroughs.
The Compliance Liability No One Is Tracking
The toll does not end with the invoice. Cloud-hosted models are moving targets. The same endpoint that returned flawless structured output last month may shift behaviour without warning, research has documented flagship APIs losing over 80% accuracy on specific reasoning tasks in mere months [5]. Every API call also ships proprietary data across a network boundary that the developer does not control. Major providers reserve the right to train on API traffic unless explicitly opted out, turning compliance with GDPR, HIPAA, or internal security policies into a daily gamble.
Submitting patient health records, unreleased source code, or confidential legal strategy to a third-party server is not a convenience, it is an abdication of professional responsibility. When developers use their own API keys to access third-party AI services on behalf of an organisation, they create a chain of legal and privacy exposure that most procurement processes have not mapped. Self-hosting eliminates this exposure at the architectural level. Data stays within the organisational perimeter, subject only to the access controls, audit logs, and retention policies that the organization itself defines.
The Myth of the Single Giant
Relying on a single, gargantuan model, a 400-billion-parameter generalist, is not a strategy, it is an architectural weakness. These titans are trained to be adequate across every domain and excellent at none, forcing product logic to contort around a vendor’s prompt-compliance peculiarities. The resulting lock-in is structural, not contractual. A recent survey found that nearly 90 per cent of executives believed they could switch AI vendors within four weeks. Among those who actually attempted migration, 58 per cent reported that the process either failed outright or required far more effort than anticipated [6].
Model drift compounds the fragility. When a model’s behaviour changes without notice, downstream pipelines break, and reproducibility, the foundation of scientific engineering, becomes impossible. A 400-billion-parameter model is also wastefully overpowered for narrow tasks. Extracting a purchase-order date, classifying a support ticket, or translating a fixed set of legal terms does not require trillions of tokens. Compound AI Systems invert this inefficiency by decomposing intelligence into specialised, composable components: small language models, classifiers, retrieval modules, and deterministic rules, each optimised for a single job and running on hardware the organization controls.
The performance gap between open-weight specialist models and proprietary generalists has effectively closed. Analysis of 94 leading large language models shows open-source models now within 0.3 percentage points of proprietary systems on key benchmarks, down from a 17.5-point gap just one year ago [7]. A sweeping empirical study of over 100 trillion tokens of real-world LLM usage confirmed that open-weight models now account for roughly one-third of all inference volume, sustained well beyond launch spikes [8]. Models that rival the most capable proprietary systems are available for full self-hosting at a fraction of the cost.
The Architecture of Independence
True AI independence rests on open-source pillars that are mature and battle-tested. The inference engine landscape has consolidated around clear leaders: vLLM for high-throughput production serving with continuous batching, llama.cpp for universal hardware compatibility with best-in-class quantisation, and Ollama for rapid development with one-command model deployment [9][10]. These are complemented by LM Studio for desktop experimentation and Text Generation Inference for Hugging Face-native ecosystems [11]. The common denominator is that each engine accepts declarative configuration, model hash, temperature, top-k, top-p, and seed, locked into version control and producing identical output years from now. You no longer hope an API endpoint has not changed. You pin the inference probability distribution as a deterministic build artefact.
Local deployment unlocks a dimension of control that cloud APIs simply do not expose. Temperature sets how creative or focused the model is – low values produce consistent, deterministic answers ideal for data extraction, while higher values encourage variety suited for brainstorming. Top-k narrows the model’s choices to only the most likely words, filtering out low-confidence guesses. Top-p does the same but adapts dynamically to the model’s confidence at each step [12]. Cloud endpoints expose few, if any, of these controls, and those that are exposed can shift with each silent model update. On a local engine, you tune these parameters to the exact reliability profile your use case demands, a level of precision no third-party API grants.
Structural guarantees go further. Grammar-constrained decoding, implemented by libraries such as llguidance, restricts the model to only tokens that would produce valid output, ensuring, for example, perfectly formed JSON on every generation with approximately 50 microseconds of overhead per token [13]. This capability is now production-grade: it ships in the vLLM and llama.cpp engines, and NVIDIA NIM exposes a guided_json parameter that enforces JSON Schema compliance across its model catalogue [14].
Fine-tuning remains accessible without a data-centre budget. QLoRA combines 4-bit quantisation with low-rank adaptation, shrinking a seven-billion-parameter model’s training footprint below 6 GB of VRAM, viable on a single consumer GPU [15]. Rank-Stabilised LoRA preserves gradient flow when scaling up for complex reasoning, preventing the model from forgetting its original capabilities. The outcome is a deterministic, auditable artefact fine-tuned on proprietary data that never leaves the building.
Agentic routing completes the stack. A lightweight classifier model inspects incoming prompts and dispatches them to the correct specialised small language model. Data extraction hits the constrained-decoding expert. Complex reasoning reaches the larger model reserved for high-cognition tasks. The routing decision adds negligible latency, and every inference decision remains inside the firewall, subject only to the organization’s rules.
Hardware Strategy for Self-Hosted AI
Running models locally requires a deliberate hardware strategy matched to the workload tier. A single NVIDIA RTX 5090 with 32 GB of VRAM delivers approximately 6,000 tokens per second on quantised seven-billion-parameter models and comfortably handles models up to thirty billion parameters for development and light production use [16][17]. For the professional tier, a Mac Studio with M4 Ultra and 128 GB or more of unified memory loads quantised seventy-billion-parameter models and excels where large context windows matter more than raw throughput [18]. The enterprise tier, running multiple concurrent 70B+ models or serving customer-facing inference demands, multi-GPU configurations with tensor parallelism, typically deployed behind vLLM on Kubernetes for autoscaling.
Internal use cases, where a handful of engineers and analysts query models throughout the day, are comfortably served by a single workstation. Customer-facing deployments, where inference requests arrive concurrently, and latency budgets are measured in milliseconds, require the orchestration layer that production inference engines provide. The architectural pattern is the same in both cases, only the hardware scale changes.
A Blueprint for Modular Deployment
Consider an API endpoint that receives user queries tagged with role and sensitivity flags. An intent router, a locally hosted small model, classifies each request as public_fact, sensitive_extraction, or complex_reasoning. The routing decision adds less than fifty milliseconds and never leaves the host.
Public-fact requests are dispatched to a low-cost cloud model, transmitting no personally identifiable information and storing no session history. Sensitive queries containing PII, PHI, or proprietary code stay entirely on-premises, processed by a fine-tuned small model with constrained decoding enabled and temperature set to deterministic output. Complex reasoning tasks go to a local large model, when the on-premises GPU cluster is saturated, a cloud fallback triggers only after the sensitivity trade-off is logged and flagged for audit.
Every model in this pipeline is referenced by its immutable hash, every instantiation is wrapped in a container, and the entire topology is version-controlled. The pipeline separates concerns by sensitivity and cost: public traffic stays fast and affordable, regulated data remains inside the perimeter processed by audited specialists, and complex tasks receive the compute they need with an explicit audit trail for any external fallback.
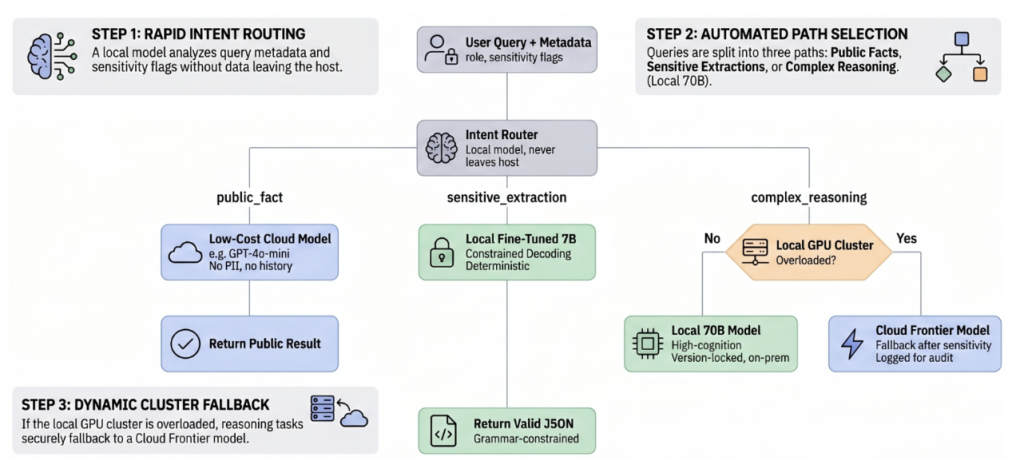
A Blueprint for Modular Deployment: Privacy-First LLM Orchestration
Architecture as Strategic Asset
In the API economy, you rent a polished experience and pay a premium for integration. When you run models locally, you invert that equation, you supply the architecture, own the decision logic, and keep the margin. Every deleted retry loop, every mathematically guaranteed JSON output, and every verifiable version-locked inference step is a compounding asset on the balance sheet. Stop renting someone else’s architecture. Become the architect. The tools, vLLM, llama.cpp, Ollama, llguidance, Docker, and Python are already on your desk.
References
[1] RealClearMarkets. (2026, April 30). AI’s ‘Horrible Economics’ Aren’t the Problem, But the Plumbing Might Be. https://www.realclearmarkets.com/articles/2026/04/30/ais_horrible_economics_arent_the_problem_but_the_plumbing_might_be_1179715.html
[2] Visual Studio Magazine. (2026, April 27). Devs Sound Off on Usage-Based Copilot Pricing Change. https://visualstudiomagazine.com/articles/2026/04/27/devs-sound-off-on-usage-based-copilot-pricing-change-you-will-get-less-but-pay-the-same-price.aspx
[3] Artefact. (2026, April). Is AI Really Getting Cheaper? The Token Cost Illusion. https://www.artefact.com/blog/is-ai-really-getting-cheaper-the-token-cost-illusion/
[4] Zhong, W. (2026, April). Token Is All You Price: Screening Urgency via Information Design. https://arxiv.org/abs/2510.09859
[5] Chen, L., Zaharia, M., & Zou, J. (2023). How Is ChatGPT’s Behaviour Changing Over Time? arXiv:2307.09009. https://arxiv.org/abs/2307.09009
[6] The Register. (2026, April 28). Locked, Stocked, and Losing Budget: AI Vendor Lock-in Bites. https://www.theregister.com/2026/04/28/locked_stocked_and_losing_budget/
[7] Introl. (2025, December 18). Open Source AI Models Close the Gap. https://introl.com/blog/best-open-source-ai-models-december-2025
[8] Aubakirova, M., et al. (2026, January 15). State of AI: An Empirical 100 Trillion Token Study with OpenRouter. arXiv:2601.10088. https://arxiv.org/abs/2601.10088
[9] EVAL: The AI Tooling Intelligence Report, Issue #001. (2026, March). The Great LLM Inference Engine Showdown. https://buttondown.com/ultradune/archive/eval-001-the-great-llm-inference-engine-showdown
[10] Berton, L. (2026, February 26). vLLM vs TGI vs Ollama: Choosing Your LLM Serving Stack. https://lucaberton.com/blog/vllm-vs-tgi-vs-ollama-2026/
[11] GigaGPU. (2026, April). Best LLM Inference Engines in 2026. https://gigagpu.com/best-llm-inference-engines-2026/
[12] GigaGPU. (2026, April). LLM Temperature & Sampling Config Guide. https://gigagpu.com/llm-temperature-sampling-configuration/
[13] guidance-ai/llguidance. (2026). Super-fast Structured Outputs. GitHub. https://github.com/guidance-ai/llguidance
[14] NVIDIA. (2026, April). Structured Generation with NVIDIA NIM for LLMs. https://docs.nvidia.com/nim/large-language-models/1.15.0/structured-generation.html
[15] Dettmers, T., et al. (2023). QLoRA: Efficient Finetuning of Quantised LLMs. arXiv:2305.14314. https://arxiv.org/abs/2305.14314
[16] RunPod Blog. (2025, April 17). RTX 5090 LLM Benchmarks: Is It the Best GPU for AI? https://www.runpod.io/blog/rtx-5090-llm-benchmarks
[17] GigaGPU. (2026, April 23). RTX 3090 vs RTX 5090 for LLM Inference: Ampere vs Blackwell in 2026. https://gigagpu.com/rtx-3090-vs-5090-llm-inference/
[18] MindStudio. (2026, May). Mac Mini M4 Pro vs Mac Studio vs RTX 5090 vs DGX Spark. https://www.mindstudio.ai/blog/mac-mini-m4-pro-vs-mac-studio-vs-rtx-5090-vs-dgx-spark-local-ai



