Drug development isn’t just expensive, it’s unpredictable in ways that keep even the most seasoned pharmaceutical professionals awake at night.
While every drug development program starts with a lot of promise – solid biology, encouraging preclinical data, a clinical study design that looks bulletproof on paper – reality intervenes quickly. Patients enroll more slowly than planned, measures of success don’t unfold as they did in animal models, or side effects emerge that nobody had expected.
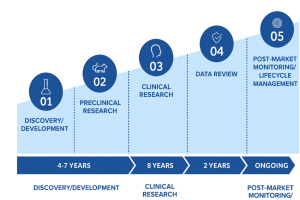
On average, only about 10% of drugs cross the clinical development finish line, and only about 90% of the successful ones receive regulatory approval; thus, only approximately 9% of drugs ever reach the market. Drug developers, therefore, find themselves in a tough spot: very high sunk costs, extremely long timelines and a low probability of success. The impact of these inefficiencies directly impacts patients’ lives and health: potentially life-saving drugs never make it to the market or are long delayed, while resources are wasted on drugs that ultimately aren’t approved.
Over the last decade, scientists have made significant progress in developing new methods to support drug discovery, including next-generation sequencing, high-throughput screening, and CRISPR. Additionally, approaches such as adaptive trial designs and improved real-world data infrastructure have enhanced the planning and implementation of clinical trials. However, despite these advances, drug development timelines have stayed long at a decade plus, costs have been trending up, and fewer drugs are being approved.
The situation is so dire that a special “law” was coined for it: Eroom’s Law – the counterpoint to Moore’s Law and the name Moore read backward. It states that the cost of drug development has been exponentially increasing while the number of new drugs approved per R&D dollar has been steadily decreasing, halving approximately every nine years.
With timelines and costs stubbornly long and high, improving the likelihood of a drug’s success remains the single promising lever. If we could consistently identify promising drug candidates early in development and focus investment on these candidates, costs would decrease and more drugs would reach patients in need.
The Promise (and Limits) of AI in De-Risking Clinical Development
In clinical development, we are already seeing artificial intelligence moving from hype to reality. Today’s algorithms can efficiently synthesize mountains of data, such as clinical trial data, patient registries and real-world evidence, to reveal patterns that would take humans or traditional analysis methods weeks or months to find. AI, if trained correctly, also provides objective analyses without the biases even the most seasoned experts aren’t entirely free of.
Over the past few years, AI has evolved into a powerful tool for assessing the probability of technical and regulatory success (PTRS), thereby helping drug makers better understand a drug’s chances of reaching the market. Robust PTRS assessments are the foundation of many critical, high-stakes decisions, ranging from selecting the best drug to advance to the next stage of development to identifying the best external asset or company to acquire. Millions of dollars and years of development efforts rest on these decisions, and every improvement in predicting success can mean the difference between failure and success.
Regulators are also paying attention. The FDA has acknowledged the growing role of AI and is developing a formal credibility framework that emphasizes traceability, transparency, and fit-for-purpose validation.
However, AI is not a silver bullet: models are only as good as the data used to train them, and the old adage “garbage in – garbage out” holds true for AI.
Not surprisingly, most clinical data is messy, incomplete and inconsistent. Without cleansing and expert curation, AI risks amplifying bias or producing outputs that mislead rather than inform. For data to be fit to train AI models, it needs to meet quality standards, that is, it needs to be AI-ready.
Explainability is another key requirement: AI cannot function as a black box where data goes in and results come out without anyone understanding how the input led to the output. To build trust in AI, decision-makers need transparency into the factors that drove a model to assign a certain probability of success to a drug. Without this clarity, credibility is undermined.
High-quality, expertly curated data and explainability are not “nice-to-haves” but prerequisites for generating accurate and robust results. When using AI for de-risking drug development, three critical ground rules apply.
Ground Rule #1 — Good Data Beats Clever Algorithms
AI cannot compensate for poor data. In clinical development, the difference between a useful and a flawed model is rarely the algorithm itself, but rather the quality and fitness of the underlying data.
Decision-grade data shares six key attributes:
- Completeness: Good data captures the full picture, including all relevant variables (e.g., trial design, endpoint, regulatory status). Missing even a few parameters can skew predictions. Completeness is required to ensure that decision-making isn’t built on partial or biased inputs.
- Granularity: Details and context are crucial in drug development, which means capturing information not only at the trial level but also at the level of individual cohorts, endpoints, and patient subgroups – information that can significantly impact risk assessment and decision-making.
- Traceability: Every data point should be traceable back to its source. While traceability is always essential, it is particularly critical in drug development where it’s needed for both regulatory compliance and internal validation.
- Timeliness: Outdated data can be worse than no data. New results from clinical trials are constantly generated, and to produce accurate and current risk assessments, good data needs to be updated continuously.
- Consistency: Consistency makes data usable. It means using the same terms and categories across sources—whether for products, conditions, or formats— so information can be combined and compared without confusion or duplication. It ensures uniform terminology (e.g., drug names, indications), harmonized ontologies (e.g., MeSH), and standard data formats and taxonomies, allowing different data sources to be combined and compared without introducing ambiguity or duplication.
- Contextual richness: Metadata, such as trial design, control type, and biomarker enrichment, provides algorithms with the necessary context to accurately interpret results.
These six principles also align closely with FAIR principles—findable, accessible, interoperable, and reusable—the global standard for scientific data management.
Ground Rule #2 — Public Data Doesn’t Mean AI-Ready: Why Expert Curation Is Non-Negotiable
Open data sources like ClinicalTrials.gov, FDA.gov, and ChEMBL are treasure troves and a great starting point, but aren’t decision-grade out of the box. These repositories were developed with regulatory visibility and transparency in mind, rather than analytics and AI.
These public databases mix formats, vocabularies and update cadences. For example, the same indication can appear under multiple names; endpoints are described differently across records, key fields may be missing, version histories can be ambiguous, and trial status updates can be noisy or contradictory. If fed straight into a model, these shortcomings result in unreliable predictions.
Data curation addresses this problem at its root by resolving issues such as data heterogeneity, ambiguity, and noise, and ensuring that missing or outdated information is identified and corrected. Data curation ensures, for example, that terms like “breast cancer” and “mammary carcinoma” are considered a single indication and that NSCLC is understood to mean the same as “non-small cell lung cancer.”
While more and more of the curation is now being done by large language models (LLMs), keeping humans, especially biological and medical experts, in the loop is a non-negotiable. Humans are needed to oversee generative AI, which is still prone to hallucinations, and to address edge cases that automation misses or cannot resolve.
So, while the methods are evolving and LLMs speed up the work, curation remains a critical step. Human experts provide the necessary judgment, guardrails, and context, especially where terminology evolves and outcomes are nuanced.
The output of diligent curation isn’t just a cleaner dataset; it is decision-ready, characterized by consistency, version control, and audit trails, and is now fit for analytics and machine learning.
Ground Rule #3 — Transparency and Explainability Are Necessary for Trust
Explainability is not a nice-to-have, but a critical component in the context of clinical development, where decisions are audited, revisited, and defended—often months after they were made. To be credible, decision-makers need to understand why a model produced a particular number, such as a PTRS assessment, and how confident they can be in that number.
A helpful way to think about explainability is in two complementary layers. The first is a portfolio-level view that illustrates how the model prioritizes different types of information across programs. Recognizing that robust endpoints, for instance, consistently contribute more than preclinical data helps reviewers calibrate their expectations before examining any single program.
The second layer focuses on a decision related to a specific drug. Here, explanations clarify which inputs drove the prediction up or down and how sensitive the result is to potential changes (such as enrollment rates or new cohort data). Providing this level of context enables reviewers to engage with the output rather than simply accepting or rejecting it.
Only if stakeholders understand the factors that drove a prediction will they develop trust in the predictions and accept them as sources of actionable, defensible decisions rather than mysterious black boxes.
The Expensive Ripple Effects of Poor Inputs
One of the most pervasive and underestimated consequences of poor data is its broad impact on risk assessment across the entire organization. When risk assessments are based on incomplete, inconsistent, or subjective data, the results can lead to very real and expensive consequences. The four most frequent ones are:
- Misallocation of R&D spend. When data inputs are stale or biased, investment can flow toward the wrong programs, even in the early stages of drug development, such as in R&D. An example is a trial that was quietly terminated months ago but remains in a competitive landscape model, skewing prioritization decisions. Studies highlight how cognitive biases such as overconfidence, anchoring, and availability bias can systematically distort R&D prioritization.
- Investing in the wrong clinical development program. A drug’s PTRS is a critical decision-making metric during clinical development. Inconsistent benchmarks can push PTRS too high – advancing clinical trials/drugs that should have been abandoned – or too low, causing promising candidates to be shelved. Either way, limited money, time and attention are invested in the wrong drug candidate.
- Costly late-stage failures. The most visible and costly failures occur when drugs are advanced to Phase 3 based on incomplete or biased Phase 2 data. These drugs subsequently fail to demonstrate efficacy, raise safety concerns, or suffer from shortcomings such as insufficient statistical power. The cost of a failed Phase 3 clinical trial can be in the hundreds of millions of dollars.
- Flawed Drug Acquisition and Licensing. The negative consequences of poor-quality data extend beyond R&D and clinical development into business decisions. Poor data can skew net present value (NPV) calculations, impact partnering strategies, and mislead business development and licensing (BD&L) decisions.
These are all variations of the same theme: garbage in, failure out. Without complete, curated, and timely data, AI magnifies noise and accelerates bad decisions, making drug development more, not less, costly.
However, when fed good, curated data, AI models will generate trustworthy, robust, objective and explainable results that support better decision-making.
Summary
Drug makers are already in a tough spot: timelines are similar to building a nuclear power plant, costs are comparable to developing a new electric vehicle platform, and success rates are akin to drilling exploratory oil wells. Despite decades of work, no promising approaches have been developed that significantly reduce costs or timelines, leaving de-risking the drug development process as the sole possible lever for improvement.
AI, when trained with clean, expertly curated data, has emerged as a powerful tool for providing better, objective, and robust assessments of a drug’s probability of advancing not just to the next level of development but all the way to the market.
The process is not simple, and success is not guaranteed. Biology is unpredictable and can derail the best-planned program, but even small improvements in accuracy can have a sizable overall impact on the robustness of a prediction.
The better the prediction, the more reliably promising drug candidates can be identified, and just as importantly, the more quickly problematic ones can be spotted and discontinued. This means patients are less likely to wait years for ineffective treatments, and promising therapies can reach those in need faster. Together, these improvements not only lower the infamously long timelines and high costs but also bring real hope and tangible benefits to patients.