AI is empowering companies to drive new efficiencies, move faster and grow revenues.
But despite its rapid implementation, data quality, or the lack thereof, stands in the way of progress.
Data quality is the top hurdle for businesses working to move AI from pilot to production – an even bigger barrier than skills shortages and budget limitations, S&P Global Market Intelligence says. The research firm adds that more than half (51%) of AI projects at the average organization are not being delivered at scale, and limiting the potential to achieve AI ROI.
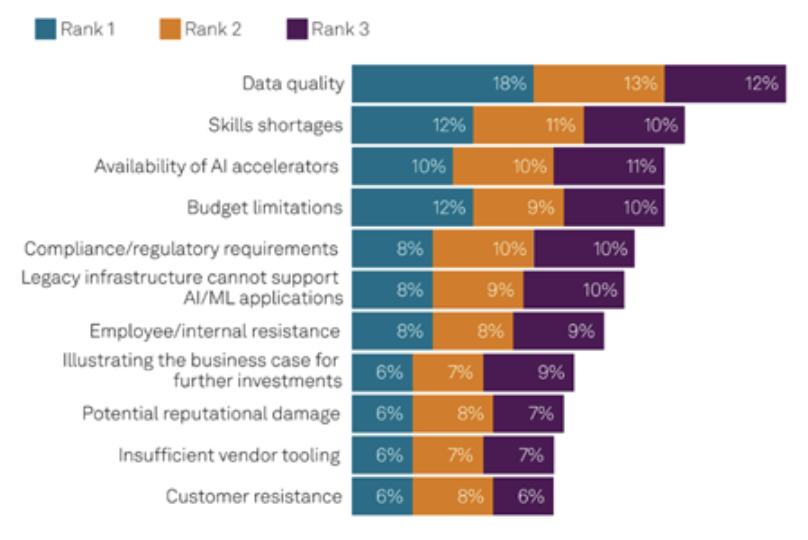
Source: S&P Global, 2024 Global Trends in AI
Why is data quality an issue? And what can businesses do to address it to reach AI ROI?
Let’s dig in.
The Data Deluge Created Opportunity and Risk
Organizations have been deluged by data, which has been multiplying by leaps and bounds, with an estimated 100-fold data growth in the past 15 years. Total global data storage is forecast to exceed 200 zettabytes by this year, driven in large part by the rapidly expanding internet of things (IoT) and AI. Data is being generated so rapidly that people have invented the ronna and quetta – new units of measurement for data.
But while data can create new opportunities for organizations, it can also introduce complexity, cost and risk. Estimates suggest that of the 200 zettabytes of data generated this year, just 37% of that data is useful. That’s in large part because data is often buried – the so-called “dark data” problem. Also, when organizations dump their data into a data lake or other repository without trying to make sense of it, they are taking massive risks with the AI outputs based on that data.
AI models today are linked to large volumes of data – and they’re scaling. But feeding AI massive data volumes doesn’t necessarily solve the data quality problem or translate into trustworthy AI outputs. In fact, using even a small amount of bad data can result in more than one bad output. If fed back into the system, such data can lead to much bigger and more problematic outcomes.
Why AI Can Fail Before It Starts – Bad Data Damages Trust
AI relies on the data on which it was trained. So, data quality is foundational.
When companies fail to design AI models with known, precise and representative training data, effective AI performance isn’t assured. In fact, it’s often a recipe for disaster – leading to the well-known ”garbage in, garbage” out scenario.
AI models trained on low-quality data can make inaccurate predictions, produce biased results and even hallucinations. In “AI Is Getting More Powerful, but Its Hallucinations Are Getting Worse,” The New York Times noted hallucination rates on one test of newer AI systems were as high as 79%.
That can lead to a breakdown in trust because early experiences inform people’s views, and trust is hard to win back once lost. If people’s early experiences are tainted, they are less likely to go back for more. When people can’t trust AI outputs, it compromises AI adoption and ROI.
On the flip side, using quality data to deliver trusted AI results helps to win hearts and minds – and accelerates adoption and time-to-value in the process.
It’s like Yuval Noah Harari said: “In a world deluged by irrelevant information, clarity is power.”
Synthetic Data Surge – More Data Quality Concerns
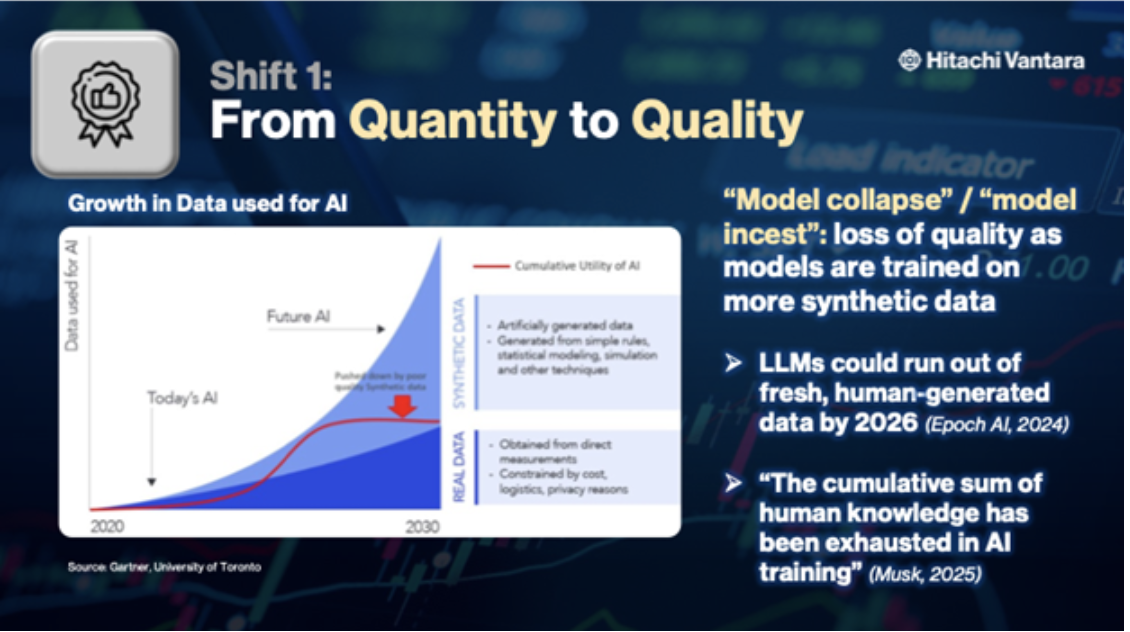
The world is now hitting the limits of large language model (LLM) scaling based on human-generated data. AI research institute Epoch AI estimates that LLMs could run out of fresh, human-generated data between 2026 and 2032 – or even earlier. Elon Musk, who founded the company that developed Grok AI, succinctly summarized the situation, explaining that: “The cumulative sum of human knowledge has been exhausted in AI training.”
What can we do? For some use cases, we can train AI models on AI-generated data. In fact, this is already happening today. Machine-generated data is growing at 50 times the rate of other business data. By 2030, synthetic data could completely overshadow real data in AI models.
Synthetic data has its upsides. It can be helpful in training autonomous vehicles to simulate every known driving scenario, for example. But AI-generated data also introduces challenges, such as exacerbating data quality issues and creating the potential for AI model collapse, which happens when a generative AI model trained mostly on its own past outputs produces increasingly low-quality, homogenized and inaccurate results over time. Unless organizations move fast to ensure high-quality data, we may see these issues growing in the next few years.
That makes addressing data quality more important than ever.
Build Your AI Strategy on Quality from Day One
So, what does data quality look like? And what strategies can organizations use to get there?
To begin your journey to data quality, consider these 10 data quality dimensions in the Hitachi Vantara framework detailed in our recent State of Data Infrastructure Global Report:
- Accurate: Does the data reflect reality?
- Ensure data accuracy by verifying sources, cross-checking against independent datasets and applying consistent quality controls. Regular audits, automated validation rules and stakeholder reviews help confirm that data reflects reality.
- Complete: Is any crucial data missing?
- Establish data requirements upfront, then use data profiling, gap analysis and completeness checks to identify missing or incomplete fields. Review against source systems and business needs to ensure critical information is captured.
- Consistent: Is the data uniform in formats, units and naming conventions?
- Define and enforce clear data standards for formats, units and naming conventions. Then apply automated validation rules to flag deviations.
- Unique: Is there duplicate data?
- Use deduplication tools and matching algorithms to identify records with overlapping or identical values, even if they different slightly in format or spelling. Also establish unique identifiers and enforce them at data entry.
- Reliable: Is the data based on typical scenarios?
- Validate data against trusted sources and historical patterns to confirm it aligns with expected ranges and behaviors. Use scenario testing and anomaly detection to flag values that deviate from typical conditions, ensuring reliability over time.
- Accessible: Is the data accessible to models as needed?
- Store data in well-organized, machine-readable formats within secure, high-availability systems. Implement proper indexing, permissions and API or pipeline access so models can retrieve the required data quickly and reliably.
- Timely: Is the data current and relevant?
- Create update schedules and real-time feeds that match the needs of your use cases, ensuring data reflects the most current conditions. Regularly review and retire outdated records so only relevant, up-to-date information is used.
- Traceable: Can the data’s origins and processing be tracked?
- Implement robust data lineage tools and documentation to capture each dataset’s source, transformations and usage. Maintain audit trails so origins and processing steps can be verified at any point in the data lifecycle.
- Tagged: Is metadata available to add context and meaning?
- Develop a clear metadata schema and apply consistent tagging at the point of data creation or ingestion. Use automated tools and periodic reviews to ensure tags remain accurate, complete and aligned with business and analytical needs.
- Clean: Does data contain personal, sensitive or proprietary information?
- Employ automated data cleansing and classification tools to detect and remove personal, sensitive or proprietary data. Apply strict governance policies and periodic audits to ensure only compliant, non-sensitive data is retained and used.
Too often, organizations treat data quality as an afterthought, creating the model and using it to generate output first and then trying to fix data after the fact. But data quality must be the foundation of any data strategy – driving design, architecture and digital transformation. It is also critical that organizations address data quality at every point in the data life cycle.
Don’t let toxic data kill your AI ROI. Take control now to start building a data quality foundation. The sooner you tackle data quality, the faster your organization will unlock real AI results.