Abstract
Every major AI-biology project today is a perception model. It reads one modality, predicts one output, and does not take actions. Autonomous driving solved a structurally identical problem a decade ago by abandoning single-sensor pipelines and building sensor-fused, action-conditional world models that roll out the future given a proposed intervention. Biomedicine has not made that transition, and until it does, AI will keep producing impressive benchmarks that do not translate into therapeutic decisions.
Introduction
Imagine trying to drive a car by reading only the fuel gauge. You would surely recognize a few failure modes like an empty tank or a leak, but you would never plan a turn, avoid a pedestrian, or merge onto a highway. This is how AI-driven biomedicine operates today.
Each sensor of the human body, such as ultrasound, MRI, or a blood panel is read in isolation by a specialist model trained on a specialist dataset. None of these models share a coordinate system. None of them take action. The autonomous driving community confronted exactly this problem, solved it, and the solution has a name: world models.
Background: A World Model Is Not a Bigger Perception Model
In 2018, Ha and Schmidhuber formalized the idea of a learned world model: a compressed, predictive representation of an environment that supports policy learning through imagined rollouts [1]. The key word is predictive. A world model does not just describe the present, but it tells you what happens next if the agent takes action a.
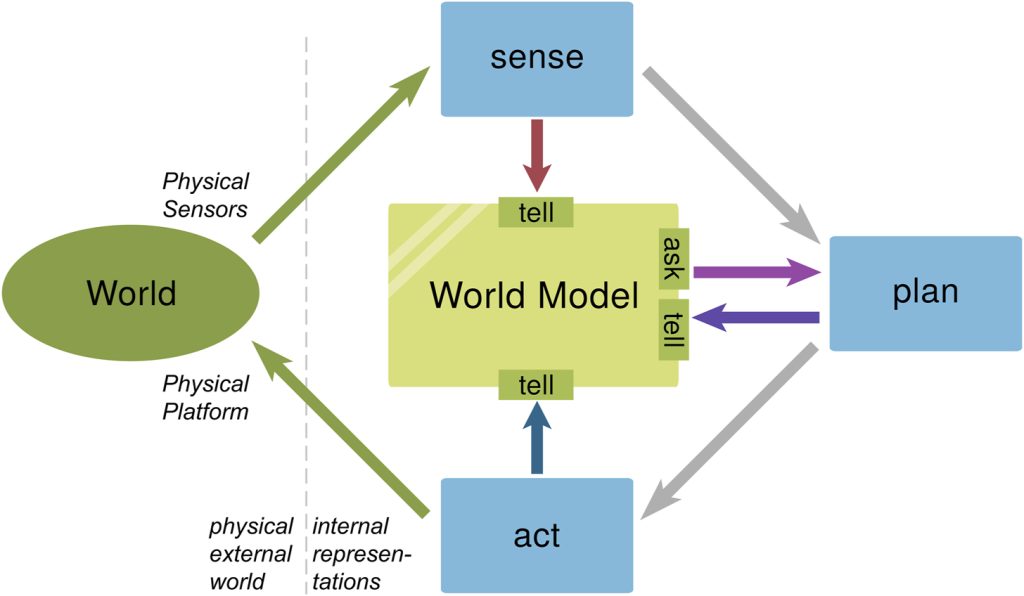
Figure 1. A World Model is an internal representation that reflects relevant parts of the physical world in which a system operates. It is shared by multiple sensors, planners, and actors [2].
For instance, Wayve’s GAIA-1 and GAIA-2 apply this directly to driving [3,4]. They ingest multi-camera video, text, and ego-vehicle actions, and they generate spatiotemporally consistent future scenes conditioned on what the car does next. This is what lets a self-driving stack simulate a lane change before committing to it.
 Figure 2. GAIA-2 synthesizes diverse scenes from specified speed and curvature profiles. Each scenario is contextually plausible, despite the original video inputs being dropped out [4].
Figure 2. GAIA-2 synthesizes diverse scenes from specified speed and curvature profiles. Each scenario is contextually plausible, despite the original video inputs being dropped out [4].
Biology has Perception Models, Not World Models
AlphaFold tells you what a protein looks like. An MRI classifier tells you whether a scan shows a tumor. A virtual-cell model predicts how a cell will react to a drug. Each of these is a specialist perception model.
None of them accept an intervention as an action. None of them simulate how the body would respond to a treatment over time. None of them share latent representations with each other. Calling the current paradigm “foundation models for biology” overstates what they actually do.
Technical Analysis: Why the Transfer Has Not Happened
The self-driving stack works because every sensor reading (every camera pixel, every LIDAR return, every radar Doppler bin, every IMU sample) is registered to the same ego-vehicle frame at the same timestamp. A world model trained on this data learns cross-modal correlations for free, because the modalities describe the same scene.
Fleets supply the temporal axis. The same intersection, recorded millions of times under different actions, gives the model the counterfactual structure it needs to become action-conditional. You cannot do this with a single car, and you cannot do it with static snapshots.
Biology’s Modalities Are Unfusable by Design
A biopsy removes the tissue you wanted to study. Looking at cells under a microscope kills them first. An MRI can watch a living patient but only at coarse resolution, and a blood panel tells you nothing about where in the body a signal came from. No two of these readouts can be taken on the same patient at meaningfully overlapping scales in space and time.
This is the reason current models cannot be stitched into a world model after the fact. The data were never generated in a form that permits fusion. You cannot register maps that were never drawn on the same grid.
No Action, No Policy
Driving has a small, well-defined action space: steering, throttle, brake. The biomedical action space is enormous and heterogeneous with drugs, biologics, gene edits, electrical stimulation, surgery. Almost no biological dataset links a specific intervention to the measurements that came after it with spatial and temporal resolution.
Researchers acknowledge that “predictive modeling and experimental design” remain disconnected in the field [5]. This is a direct consequence of looking at biology as a catalog of states, and not trajectories.
Future Directions: What a Biological World Model Would Require
A biological world model needs four things the field does not yet have. First, a set of sensors that can record the same living tissue in parallel and over time. Second, a shared spatiotemporal coordinate system registering every sensor to the same tissue and timeline. Third, an action space of interventions delivered at known coordinates. Fourth, a training objective that predicts future multimodal readings given present readings and a proposed action.
None of these are individually infeasible. We have fragmented research working on genetic sensors and organ-on-chip hardware, but no integrated platform where all four are built in from day one.
The Infrastructure Bet
Wayve and Waymo understood something most AI-bio companies still miss: the fleet came before the model. The reason GAIA-2 exists and a biological analog does not is not because biology is harder to model. It is because no one has built the equivalent of a sensor-equipped fleet for living tissue.
Conclusion
The final vision is a closed loop that looks familiar to anyone in the autonomous systems world. A clinician specifies a desired tissue state. The world model rolls out candidate intervention trajectories. The most promising candidate is applied, and the resulting sensor reading updates the model of your body.
We have seen this architecture work before. It does not need another foundation model trained on existing atlases. It needs a fleet.
References
[1] Ha, D., & Schmidhuber, J. (2018). World Models. arXiv:1803.10122. https://arxiv.org/abs/1803.10122
[2] Sakagami R, Lay FS, Dömel A, Schuster MJ, Albu-Schäffer A and Stulp F (2023) Robotic world models—conceptualization, review, and engineering best practices. Front. Robot. AI 10:1253049. doi: 10.3389/frobt.2023.1253049
[3] Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., & Corrado, G. (2023). GAIA-1: A Generative World Model for Autonomous Driving. arXiv:2309.17080. https://arxiv.org/abs/2309.17080
[4] Russell, L., Hu, A., Bertoni, L., Fedoseev, G., Shotton, J., Arani, E., & Corrado, G. (2025). GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving. arXiv:2503.20523. https://arxiv.org/abs/2503.20523
[5] Rood, J. E., Hupalowska, A., & Regev, A. (2025). Virtual Cell Challenge: Toward a Turing Test for the Virtual Cell. Cell. https://www.cell.com/cell/fulltext/S0092-8674(25)00675-0