Agentic AI is frequently named as the most transformative technological breakthrough in modern human history, but its impact and associated risks might be different from what most researchers, politicians, and business communities are debating. Many organizations have elected to adopt AI Agents without granting access to proprietary data. These AI Agents end up simply rephrasing publicly available information, adding to the noise rather than generating genuine insight—compounding the information overload that employees, customers, and partners are already struggling to manage. The content overload is not only reducing the ability to make intelligent decisions, but it’s also eliminating certain differentiated value propositions organizations have. AI Agents need to collaborate and access proprietary information in order to generate value-add differentiated content and actions, yet granting such access creates immense security and regulatory risks. The solution is Federated Computing—the architecture that lets AI Agents access proprietary data, collaborate across organizational boundaries, and generate truly differentiated intelligence, without ever exposing the sensitive information that makes it valuable.
Many organizations are rushing into Agentic AI by treating it like a standard IT project focused on a pipeline of use cases, often prioritized using an impact versus feasibility assessment. This approach is frequently promoted by people relying on patterns from past technological breakthroughs and targeting “quick win” projects, such as AI use cases on public data for isolated improvements.
While that mindset might have worked for traditional IT systems or early-stage predictive AI a decade ago, it ignores a crucial reality of today: your customers, partners, and competitors are also using AI Agents. This fundamentally changes how industry economics works and how decisions are made. Without accounting for the connected industry ecosystem and proprietary data as a differentiator, a strategy relying on AI only trained on public data becomes risky, expensive, and ultimately ineffective.
BasicAgents, AI Agents trained on and used with public data only, might not yield a competitive advantage or value proposition a customer would pay for, and the organization should not expect sustainable ROI from its basic AI Agents. Since competitors and customers have access to the same data and AI tools as the organization, the results won’t be unique or differentiated. Think about wealth management. Why would a customer pay commission to managers who use a basic LLM for investment advice? The customer has access to the same LLM models. The same goes for an insurance broker sending cross-sell messages generated by basic LLMs to prospects. The competing brokers are sending similar messages, and rational prospects, when overloaded with such cheap content, would prefer to avoid any purchases if possible. This same logic applies to internal productivity gains—if every competitor’s basic Agent delivers the improvements, those gains get competed away and never translate to sustainable profit.
Vanilla Agents might actually hurt your business in certain cases. Consider the productivity drain when employees use vanilla LLMs to generate high volumes of lengthy, low-quality emails, eroding the conciseness that makes internal communication effective (den Rooijen, 2025). The result is reduced productivity for top performers. Additionally, LLM models are known to be optimized for persuasion over accuracy (Randazzo et al, 2026, Korovamode, 2026). Vanilla LLM brings persuasion tricks, such as text length (Singhal et al, 2024), which might be already translating into sub-optimal decisions within your organization.
It’s no surprise to see MIT and other academia researchers reporting that “95% of organizations are getting zero return” on Agentic AI (Challapally et al, 2025), and consulting firms echo these results with independent studies stating that “only 5% of companies get substantial value from AI” (Apotheker et al, 2025). The same message dominated Davos, where “the business leaders were more focused than ever on how to drive business returns from their AI spending” (Kahn, 2026).
Organizations must move beyond treating AI as a series of incremental use cases powered by vanilla agents, and instead commit to a broader transformation grounded in Applied AI principles. The three principles—Business Domain, Transformation, and Technology—work in a continuous cycle under unified leadership. The AI journey starts with Business Domain—defining the organization’s new business model, including its value proposition and competitive advantage, in a world where every player in the industry has access to AI Agents. Transformation is the path to implementing that new model, with Technology serving as the enabler at each step along the way.
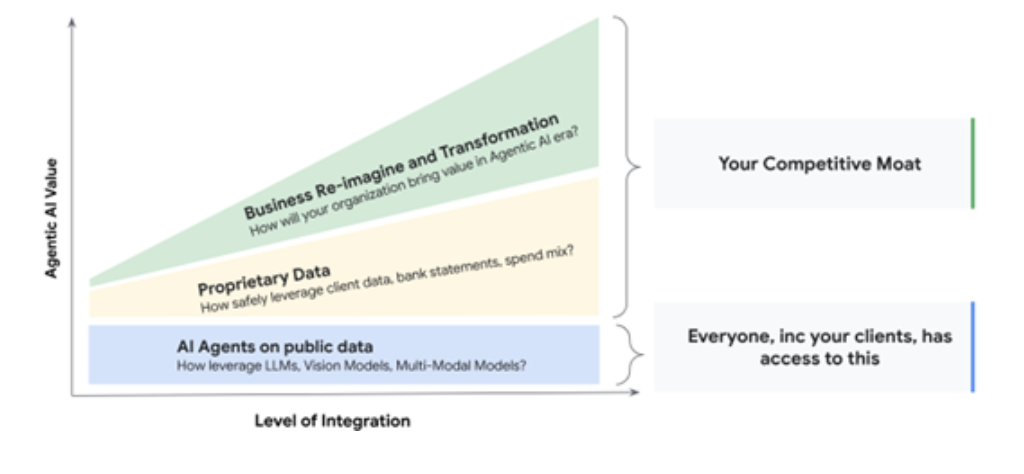
A common source of business differentiation is proprietary data which only the organization has access to. The organization has to reimagine its business model with AI Agents collaborating using such proprietary data. Other sources of differentiation—employees, proprietary technology, government relations, branding, etc—are also important components of the organization’s new business model. As integration of AI Agents with proprietary data improves and the new business model evolves, business differentiation increases and the organization realizes Agentic AI value. Transformation includes workflow redesigns and decision-making delegations needed for AI Agents to extract value from the proprietary data.
The Technology principle refers to the infrastructure piece that supports transformation. How can AI Agents compliantly access proprietary data and collaborate without revealing sensitive information? A structural shift from centralized data architectures to Federated Computing is needed. This “zero-movement” paradigm allows AI models to travel to where data resides—between sovereign boundaries, organizational firewalls, or departmental silos—rather than moving data to a central model. By decoupling code from data, organizations can finally unlock the full potential of Agentic AI without compromising privacy or security.
Traditional AI tools are passive, but Agentic AI is proactive. A customer service agent, for example, might autonomously resolve a billing dispute by accessing a customer’s payment history, support tickets, and internal pricing secrets. In a healthcare setting, a clinical agent might suggest treatments based on a patient’s unique genetic profile compared against global outcomes. Similarly, imagine a business interested in building an AI assistant that can answer employee questions like “What was our total customer acquisition cost across all regions last quarter?” The answer requires data from finance, marketing, sales, and operations—data that may live in six different systems across three continents, each with its own access controls and compliance requirements. With Federated Computing, these AI Agents become proactive.
For proactive AI Agents to bring a truly differentiated value proposition, they need access to sensitive PII (names, addresses, and financial records), proprietary IP (internal pricing models, margin data, or drug molecular structures), and internal data silos (datasets scattered across HR, finance, CRM, call centers, business service units, and regional systems). AI Agents also have to collaborate across organizations and sovereign boundaries to make business transactions, prevent fraud, or search for medicines.
AI Agents, either internal or external, with admin access to data is a non-starter. Such access turns every AI Agent into a potential breach vector and risks massive regulatory penalties, which for GDPR violations alone exceeded €6.5bn over the five-year period immediately preceding this article’s publication (April 2026). Consequently, many organizations face a “starvation for insights” because their most valuable data is locked in “data graveyards”—secure but inaccessible repositories.
Federated Computing dissolves this tension by inverting the standard AI development process. Instead of extracting, transforming, and loading (ETL) data into a central lake, the process follows a “zero-movement” workflow and its architecture includes five elements:
- Orchestration: A global model is distributed to various data sites.
- Local Learning: Each site trains the model on its own data behind its own firewall.
- Encrypted Updates: Only the “learnings”—mathematical gradients, not raw data—are sent back to a central server.
- Secure Aggregation: These insights are combined to improve the global model, which is then redistributed.
- Distribution & Iteration: The enhanced global model is redistributed to all participants, who can now deploy it for inference on their local data.
The five-element cycle then repeats, with each iteration improving model accuracy while maintaining zero data movement. The raw data—customer names, transaction details, patient diagnoses, and proprietary formulas—never moves. What moves are the insights: “We learned that transactions following pattern X are 40% more likely to be fraudulent” rather than “Customer John Smith at 123 Main Street made a $500 transaction to Account Y.” Federated Computing empowers AI adoption to shift from vanilla to proactive AI Agents.
Many organizations, including Swift and Eli Lilly, have adopted Federated Computing. Across these organizations, three common deployment patterns emerged:
- Cross-Organization Federated Learning: Multiple organizations collaborate on a shared AI model without exposing data to each other. Bank A, Bank B, and Bank C each train a fraud detection model locally, sharing only model improvements.
- Intra-Organization Federated RAG: A single organization deploys federated RAG to enable AI to query across internal silos without centralizing data. An AI assistant helps the Chief Strategy Officer of a global retailer based in its US HQ to answer “What was our customer churn rate in Europe last quarter?” by federating queries to the European CRM system, billing database, and support ticket system—without copying any of that data to a central location.
- Code-Data Separation: Developers and researchers build and test their models using synthetic or anonymized data. When deployed to production, the model runs in a secure enclave with access to real sensitive data, but model owners never see that data directly. The AI’s behavior is logged and auditable, but the data itself remains isolated.
The era of use case-focused adoption of vanilla AI Agents led by IT is ending. Forward-thinking leaders are moving to Applied AI principles, prioritizing the development of Agentic capabilities that bring value to customers using AI Agents and are hard for competitors to duplicate. In this new landscape, value is defined not by the technology itself, but by how Agents amplify an organization’s sources of differentiation, such as proprietary data. In this context, Federated Computing technology, complemented with other Privacy Enhancing Technologies (PET) such as Confidential Computing and trusted execution environments (TEEs) becomes foundational for AI Agents to collaborate and bring a differentiated value proposition grounded on proprietary data.
To learn how Federated Computing enables your organization to deploy truly differentiated agentic AI, download the full white paper: Beyond Data Silos: How Federated Computing Unlocks AI Without Compromising Privacy.