
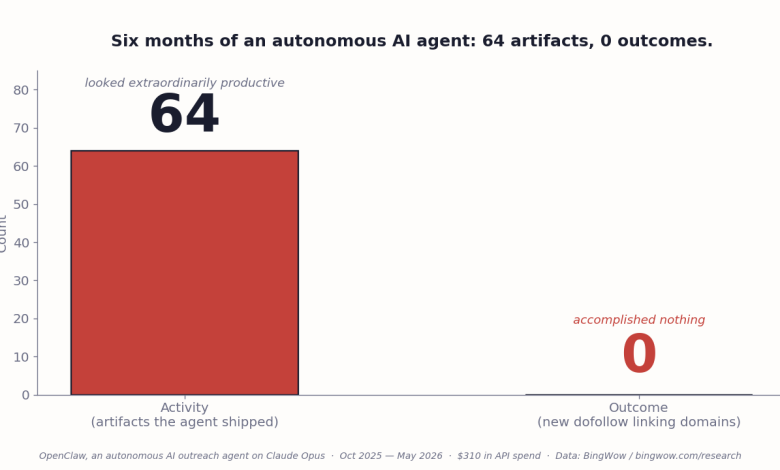
My AI agent ran for six months. It produced nothing.
We called it OpenClaw. It ran on Claude Opus, lived on a \$6 DigitalOcean droplet, and had permission to email journalists, post on Medium, and pitch on Reddit. Over 180 days the agent published 10 Medium articles, pinned 39 Pinterest boards, and sent 12 guest-post pitches. Our Reddit account got permanently banned from r/BabyBumps after the agent posted three promotional threads in one day.
Total bill: \$310 in API charges. Total result: zero new backlinks from any site that passes Domain Rating. The work the agent existed to do — earn editorial mentions on real publications — it never did, not once.
This is not a story about a buggy implementation. The agent worked exactly as designed. It is a story about the design.
What the data says about agents like mine
I am not the only one running this experiment. The Gartner 2026 Hype Cycle puts agentic AI at the Peak of Inflated Expectations and predicts that more than 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, and inadequate risk controls. McKinsey’s Global AI Survey 2026 finds that 73% of enterprise AI projects fail to deliver ROI. Writer’s enterprise adoption analysis reports that 88% of AI agent pilots never reach production.
Forrester broke down why. Of the failures they audit, 41% trace to unclear success criteria, 33% to insufficient tool or data access, and 26% to drift in evaluation coverage.
Every one of those three causes is what happens when an LLM is asked to do the job that traditional code does for free. Success criteria live in the prompt, not in a function signature. Tool access has to be negotiated by the model at runtime. Drift is what an unbounded LLM does over hundreds of invocations on the same workflow.
The agent is not failing because the model is dumb. The agent is failing because the architecture handed control flow to a model that was never supposed to own it.
The boring alternative has a name
Matei Zaharia and colleagues at Berkeley AI Research named it in February 2024. They called it the Compound AI System. The paper makes the design choice explicit: either the overall control logic is written in traditional code that calls LLMs at specific bounded steps, or the control logic is driven by an LLM that decides what to do next.
Compound systems pick the first. Agent vendors are selling the second. The Forrester failure breakdown is the data point that decides between them.
Today my company runs the compound version. Six AI components, four vendors, one orchestration layer made of TypeScript and SQL:
- Claude Sonnet 4.5 — content quality judgment, generation (`lib/claude.ts`)
- Claude Haiku 4.5 — classification: moderation, dedup, categorization (`lib/claude.ts`)
- Gemini 2.5 Flash — bingo-clue generation (`lib/gemini.ts`)
- Gemini 3 Flash Preview + Gemini 2.5 Pro fallback — themed-name generation (`lib/generate-themed-names.ts`)
- GPT-4o Vision — background image description (`app/api/cron/describe-backgrounds/route.ts`)
- Replicate Flux Schnell — background image generation (`lib/generate-background-image.ts`)
Each model does the one bounded thing it is good at. None of them decides what happens next. Code decides. SQL picks which card to surface to a visitor. A regex enforces the publishability rules. A cron job at 06:00 UTC runs the moderation sweep. The pipeline is auditable line by line because the pipeline is code.
After we moved classification off Opus 4.6 and onto Haiku in April, our Anthropic bill fell from \$560 a month to between \$170 and \$245. The system generates 30,000 AI bingo cards a month at that cost. Same Anthropic, same OpenAI, same Gemini, same Replicate. Same APIs the agent burned through \$310 chasing nothing in six months. Different architecture. Opposite outcome.
What changed between the agent and the compound system
The agent failed in five specific ways. The compound system does not fail in any of them.
The agent had a 26,000-character operating manual loaded into a 20,000-character context window. The bottom 25% — the publishing rules, the warm-lead state, the channel templates — got silently truncated for months. The agent kept drafting outreach because the part of the file that told it what to draft was inside the window. The part that told it how to follow through was not. The compound system has no operating manual, because code does not need one.
When the agent could not complete a task — could not access a journalist’s website, could not parse a recipient’s bio — it filled the gap with phrases that looked like personalization. The output passed eyeball review. The corpus did not. The compound system cannot do this because each model returns one specific output and the next code path validates it before moving on.
The agent confirmed success when its API call returned 200. Whether the email reached the inbox, whether the Medium post survived auto-moderation, whether the Reddit submission stayed up — the agent did not check. Three of nine pitches had silent delivery failures. The compound system checks every output against the receiving system before marking the work done, because checking is one line of code.
Every cron in the agent defaulted to Opus 4.6 at \$5 per million tokens. Classification work ran on the wrong model for half a year. The compound system routes classification to Haiku at \$1 per million tokens, generation to Sonnet at \$3 per million, and never touches Opus. The agent had no model-routing intelligence because routing is a code decision and the agent owned the decisions.
The agent’s Reddit account got banned because the agent could not see the public response to its own posts. A human marketer making the same mistake would have stopped after the first ban. The compound system has no Reddit account because we no longer let any LLM act unsupervised on outbound communication.
What to ask before you sign an agent vendor in 2026
Vendors pitching autonomous agents will tell you the model is the breakthrough. The model is not the breakthrough. The model has been the same for two years. The question is who owns the control flow. If the vendor’s answer is “the agent decides,” you are buying the architecture that Gartner is predicting will be canceled in 40% of cases by the end of 2027, McKinsey is finding fails ROI in 73% of cases, and Berkeley AI Research has been pointing at the alternative to for two years.
The boring alternative is not in any vendor’s pitch deck because there is no margin in selling code that calls Python functions. Compound AI systems are not a product category. They are an architectural choice. You make them by paying a senior engineer to glue together component AI calls with deterministic code. Then you watch the bill come in at a quarter of what the agent quoted, and you watch it actually ship.
The bet I am making with this article is that the next 24 months belong to the architecture nobody is marketing. The companies still buying agents in mid-2027 will be tomorrow’s negative-ROI case studies. The companies running compound systems will be the panels at the AI conferences explaining how they did it for \$200 a month.
I built one of each. The agent cost \$310 and earned zero. The compound system costs \$200 a month and runs the product 100,000 people use. Pick the architecture. Don’t pick the marketing label.
About the author and the receipts.
Forrest Miller graduated magna cum laude from Brown University, where he received the Library Undergraduate Research Award for exceptional research sophistication and originality. He held product leadership roles at R-Zero, SoFi, Blend, and Opower, and was recognized with Amplitude’s 2022 Pioneer Award for data-driven product innovation. He is the founder of BingWow, a free AI bingo platform used by classrooms and HR teams. The BingWow Research Portal hosts the open-licensed engagement research; the State of Team Building Games 2026 report is indexed on SSRN (Abstract 6632200) and EdArXiv (DOI 10.35542/osf.io/w6hzt_v1). The BingWow caller is the most-trafficked compound-AI surface in the product. Audit the receipts; the article is footnote-able to the line.
Sources
- Berkeley AI Research, “The Shift from Models to Compound AI Systems” (Zaharia, Khattab, Chen et al., February 2024)
- Gartner, Hype Cycle for Agentic AI 2026
- McKinsey Global AI Survey 2026
- Forrester enterprise-agent failure analysis (root cause split: 41% / 33% / 26%)
- Anthropic, model pricing (Haiku, Sonnet, Opus per-million-token rates)
