
Introduction
Modern data platforms must ingest and process data from a wide variety of sources ranging from SFTP servers and cloud object storage like S3 to structured files such as CSV. As organizations scale, managing these heterogeneous ingestion pipelines using hardcoded logic becomes brittle, difficult to maintain, and error-prone. A metadata-driven framework built with PySpark offers a scalable and flexible solution to this challenge.
This article presents a technical design for a metadata table-driven PySpark framework capable of handling multi-source data delivery at scale. It covers the problem, architectural solution, implementation approach, and concludes with benefits and extensibility.
Problem Statement
Organizations dealing with large-scale data ingestion face several recurring challenges:
- Heterogeneous Data Sources – Data arrives from SFTP servers, S3 buckets, APIs, and local file systems. Each source has unique connection, authentication, and file format requirements.
- Hardcoded Pipelines – Traditional ETL jobs often embed source-specific logic. Adding a new source requires code changes, testing, and redeployment.
- Lack of Scalability – Pipelines are not reusable. Operational overhead increases linearly with the number of sources.
- Poor Observability – Limited tracking of ingestion status, errors, and retries.Difficult to debug failures across distributed systems.
- Schema Variability – Different file formats (CSV, JSON, Parquet) and evolving schemas complicate ingestion.
Solution Overview
The proposed solution is a metadata-driven ingestion framework using PySpark. Instead of writing separate pipelines, we define ingestion behavior using metadata tables. Key principles followed were:
- Configuration over code
- Reusable ingestion engine
- Dynamic source handling
- Scalable and distributed processing
- Extensible architecture
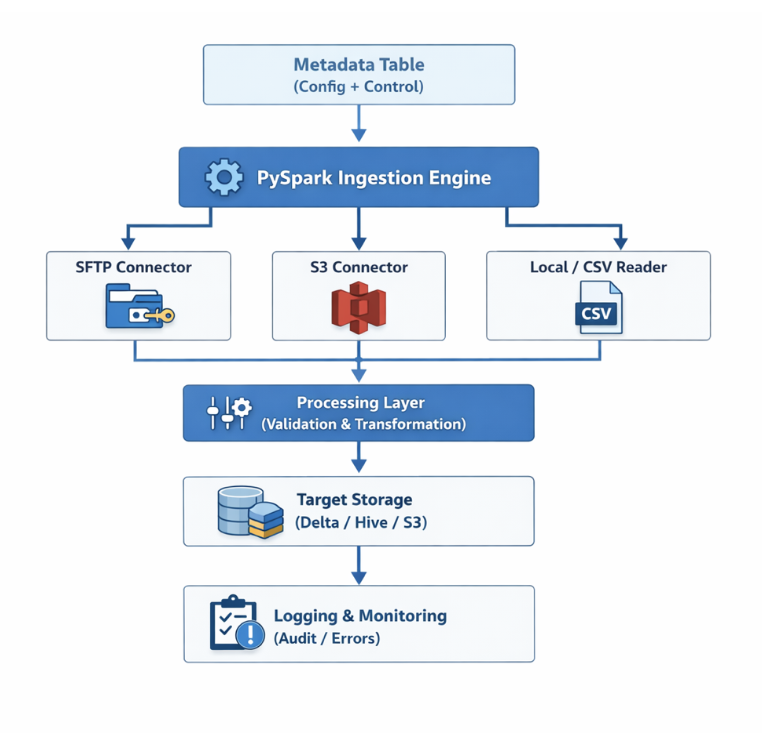
Architecture Components
1. Metadata Tables
Central to the framework are metadata tables stored in a relational database or Hive metastore.
Example: Source Metadata Table
| Column Name | Description |
| source_id | Unique identifier |
| source_type | SFTP / S3 / LOCAL |
| file_format | CSV / JSON / PARQUET |
| file_path | Source path |
| delimiter | For CSV |
| schema_location | Optional schema definition |
| target_table | Destination table |
| load_type | FULL / INCREMENTAL |
| active_flag | Enable/disable |
2. Ingestion Engine (PySpark) that dynamically executes logic based on metadata. The architecture includes:
- Source Connectors: For ingesting data from SFTP, S3 (native Spark), and Local/CSV files.
- Processing Layer: Responsible for schema enforcement, data validation, and transformation logic.
- Target Layer: Where processed data is stored, including a Data Lake (S3 / HDFS) and a Data Warehouse (Delta / Hive / Iceberg).
- Logging & Monitoring: Crucial for audit trails, error tracking, and managing retry mechanisms.
Implementation Details
Step 1: Load Metadata
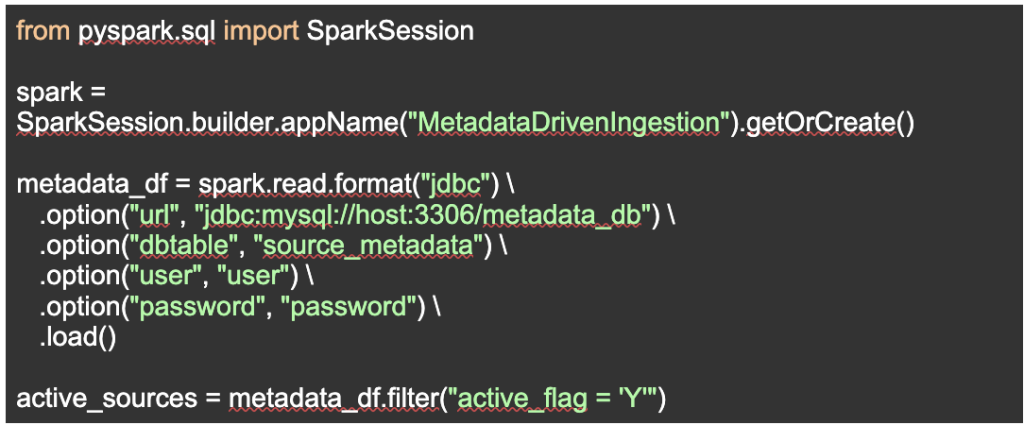
Step 2: Dynamic Source Handling

Step 3: SFTP Integration (Simplified)

Step 4: Processing and Writing

Step 5: Driver Logic

Data Ingestion Best Practices
1. Schema Management (Evolution)
- Store the schema within metadata or a dedicated schema registry.
- Apply the schema dynamically using spark.read.schema().
2. Incremental Data Loading
- Utilize watermark columns, such as a timestamp field.
- Maintain the last successfully processed value in an audit table for tracking.
3. Execution Parallelization
- Avoid the use of .collect() to prevent pulling all data onto a single node.
- Leverage Spark’s inherent RDD parallelism.
- Employ task orchestration tools (e.g., Airflow) for managing parallel workflows.
4. File Discovery & Matching
- Support pattern matching with wildcards (e.g., *.csv).
- Implement automatic detection for newly added files.
5. Data Quality Checks (Validation)
- Perform null value verification.
- Ensure schema conformity (Schema validation).
- Set and monitor row count thresholds.
Benefits of Metadata-Driven Design
New connectors (API, Kafka, etc.) can be added easily.The system offers several key benefits.
- Scalability is ensured as adding a new source only requires inserting a new metadata record without any code changes.
- Maintainability is enhanced through centralized logic, which reduces duplication and simplifies updates.
- Flexibility allows the system to support multiple formats and sources without requiring a redesign.
- Observability is built-in with logging and audit tables that provide visibility into the pipeline’s health.
- Finally, Extensibility allows for the easy addition of new connectors, such as API or Kafka.
Challenges and Considerations
- Metadata Quality: Incorrect metadata leads to failures.
- Security: Credentials for SFTP/S3 must be managed securely (e.g., secrets manager).
- Performance: Avoid driver bottlenecks when processing many sources.
- Error Isolation: One failed source should not block others.
Architecture Diagram
Conclusion
A metadata table-driven PySpark framework provides a powerful and scalable approach to handling multi-source data ingestion. By decoupling ingestion logic from configuration, organizations can dramatically reduce development time, improve maintainability, and scale effortlessly as new data sources are introduced.
This design is especially effective in modern data lake architectures where flexibility, performance, and extensibility are critical. With additional enhancements like schema evolution, orchestration, and real-time ingestion, this framework can serve as the backbone of a robust enterprise data platform.


