
Clickstream data is plentiful, cheap to emit, and deceptively difficult to trust. When a team attempts to respond to “What did this user do?” The presumptions manifest: a cookie that resets, a mobile device that’s shared, a browser that blocks cross-site tracking, a dynamic IP address, and a login that appears only some of the time. More recent privacy controls also reduce cross-site identifiers, and tracking surfaces—Safari’s tracking protections and third-party cookie blocking along with similar controls in Firefox change what you can reliably see across sites and at times across sessions.
For AI and analytics leaders, this problem is now sitting upstream of everything that pretends to be “customer intelligence.” If identity is wrong, the results from your “personalization” become mis-personalization, your measurement becomes misattribution, and your training data becomes mislabeled. The product is a silent failure mode: models that are fine in aggregate but fail in production in ways that are difficult to articulate.
The most pragmatic aim is not a perfect, singular “true user.” It’s a defensible identity layer that (a) makes inference conservatively; (b) can articulate why it inferred a link; and (c) can refuse to guess whenever there are evidence conflicts.
Why identity resolution is now an AI governance issue
The identity joins are not often considered high-risk decisions. They should be — because identity is decisional infrastructure. The same resolved ID drives experimentation, recommender systems, propensity models, fraud heuristics, and even compliance processes.
Two factors drive urgency higher than five years ago: On the one hand, the signal environment is noisier. Browsers and platform-based services are progressively gate-keeping or capping tracking primitives. For instance, Firefox currently defaults to disallowing cross-site tracking cookies, and Apple reports that App Tracking Transparency must first receive the user’s consent for an app to “track” other companies’ apps and websites. Second, the regulatory framework about “identifiers” is broad. Under the EU GDPR, “online identifiers” include things like IP addresses and cookie identifiers which it made explicitly clear, and they can (particularly in combination) be used to identify natural persons. Similarly, the UK regulator states that online identifiers (including IP addresses and cookie identifiers) are part of personal data under UK GDPR. So the identity layer isn’t simply an engineering convenience. It is a frontier where privacy risk, auditability, and business correctness meet.
Identity graphs treat identity as evidence, not a fact
The real thing to do is stop treating identity as a single column (“user_id”), and instead begin treating it as we would treat an evidence graph.
In record linkage research the traditional framing is probabilistic—two records either agree or disagree based on evidence and thresholds. The Fellegi–Sunter tradition makes explicit that you need a decision rule with thresholds — not an all-or-nothing guess. Industry practice usually discovers this hard: if you impose resolution on weak evidence, then false merges pile up and become very costly to unwind.
Because clickstream evidence is inherently relational, graph modeling is therefore useful. You don’t simply have “a device ID.” You have an event that worked using a device, occurred in a session, originated from an IP prefix and, sometimes, connected to an account log-in. That a graph makes those relationships first-class and inspectable.
Academic research on entity resolution has demonstrated time and again that relational structure can improve resolution — if more so than just attribute-based matching. “Collective entity resolution” where joint resolving of co-occurrence relationships happens and reports improvements against attribute-only baselines are described by Bhattacharya and Getoor. Other graph-based approaches explicitly model multiple types of graphs and learn which type of relationships would be more reliable for disambiguation in an ambiguous context.
That translates neatly to clickstream identity: not all edges are equal, and you want the system to realize this diversity.
A layered architecture that stays explainable in production
A useful identity graph is not “a graph database plus a matching job.” Consider a stack with explicit stop points, so that every downstream consumer recognizes what to see, what’s considered inferred and how conservative the system was.
Ingestion and normalization
Identity systems fail early before they “start” because identifiers come in erratic forms and the pipeline covertly modifies them. A methodical ingestion layer generally does four things:
- Keeps raw identifiers in immutable storage (for audit and replay)
- It formalizes representations at the outset (such as case, encoding, normalization rules).
- It limits precision when precise is not operationally warranted (e.g., IP prefixes versus full IPs, e.g., in situations where exact IP increases risk without much matching power)
- It records what identifiers are collected and why, since online identifiers can be personal data under GDPR/UK GDPR framing.
At that point the output should be “boring”: event rows with stable schema but no inferred user.
Graph construction
Graph construction is a mechanical process. For each event, you materialize nodes—like signals (device, session, IP prefix, coarse location, account where present) and edges that describe observed relationships.
Graph growth is the key production detail. Some signals are extreme fan-out (IP prefixes, popular locations). If you allow these to hold lasting connectors, they turn into noise magnets. A production-grade graph thus requires clear retention and pruning rules:
- Edges should expire based on time windows that are consistent with your business case.
- Noisy connectors should be trimmed down, or shielded (think down-weighted, or separated into “weak evidence” buckets).
- Event nodes commonly require TTL to maintain stability in traversal costs.
It’s less “graph theory” than it is “keeping the future compute bill predictable.”
Resolution as scoring, not merging
Resolution is where many teams become too involved. The goal with the profile to be merged is not to do everything into a master. It is for scoring evidence paths and making bounded decisions. One lightweight solution is path-based scoring with typed edge weights.
Conceptually:
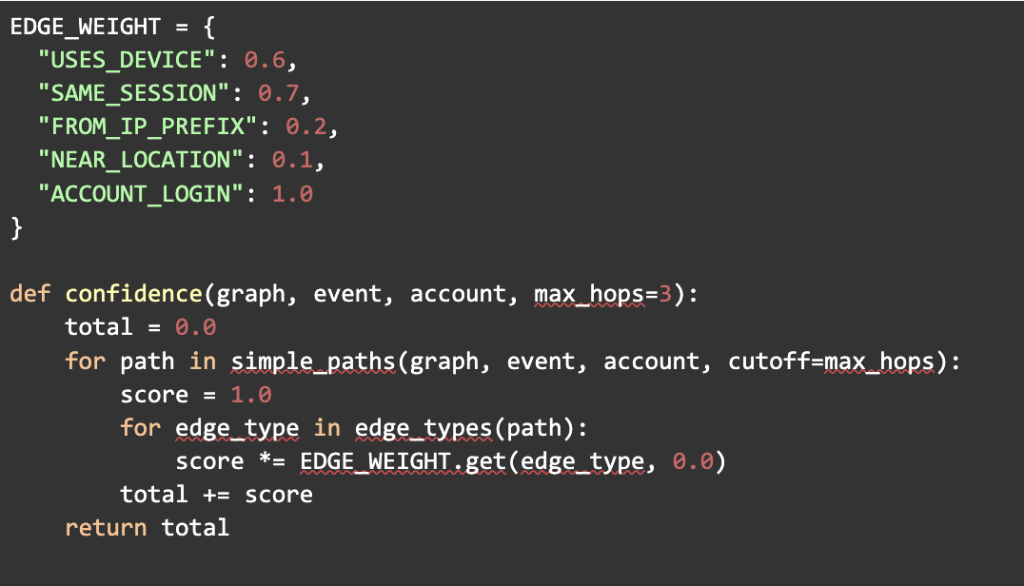
The point is not an exact weight. It’s the shape of the decision: typed evidence accumulates, short paths are preferred, and scoring is inspectable. This is a direct cousin of probabilistic record linkage: evidence contributes weight, and thresholds drive match decisions.
Thresholds, abstention, and the discipline of “unknown”
If you take only one idea from record linkage to clickstream identity, take this: you need an explicit “possible match / undecided” region.
As Fellegi–Sunter framing and subsequent practical systems built upon it, decision-making is based on thresholds and uncertainty exists when evidence is ambiguous. In a clickstream graph, ambiguity is the default: households share devices, classrooms share tablets, corporate NATs collapse many users into one IP range, and login events appear intermittently.
So your resolver should have three outputs, not two:
- Match: confidence ≥ high threshold.
- Non-match: confidence ≤ low threshold (or contradictory evidence).
- Unknown: in-between.
Data is not wasted when “Unknown” is the order. It is risk-managed data. It avoids misleading merging that messes with analytics and downstream ML labels. From a practical standpoint we see this manifesting itself as a policy: enrichment jobs get to output NULL inferred identity; downstream consumers should be built on it.
Governance and privacy: policy as code, not a slide deck
Identity graphs implicate personal data. GDPR makes clear that identifiers online (like IP addresses and cookie identifiers) can leave traces that make that identification possible when used together. Such identifiers can also be personal data, the UK regulator’s guidance makes clear. This alters what “good engineering” means. Governance is not a document. It’s enforcement that runs inside your pipeline.
Three practices tend to divide mature identity layers from fragile ones:
First, by default minimize attributes. If an identifier doesn’t result in measurable improvements in resolution quality or operational outcomes, don’t keep it. This is consistent with existing privacy risk management guidance (for example, from NIST’s framing of privacy risk management as structured practice, with implementations varying across organization and jurisdiction).
Second, decrease the blast radius with delegation of responsibilities. Store raw identifiers in tightly controlled stores; allow most teams to consume only tokens or mapped IDs and, when necessary, confidence and explanation artifacts.
Third, check if inference makes sense. For every inferred mapping; it should be explainable as a set of paths and weights. If an auditor, or an internal data scientist troubleshooting model drift, can’t reproduce why an event was related to an identity, trust erodes quite quickly.
That is where platform policies matter, too. Apple specifically defines tracking as linking identifying information across third-party properties, and requires user permissions through ATT for such tracking. Even if you do not use it for advertising, engineering leaders should handle “linking identifiers across contexts” as an act of high scrutiny.
Operational integration that doesn’t turn into “rule sprawl”
In many firms, the identity layer begins as a batch enrichment job, before being pulled into real-time products. That shift is the one where operational discipline is really important.
Batch is where you would like to make your start. It gives you reproducibility, makes backtests feasible, and it gives you a stable artifact: an event_id → inferred_identity_id → confidence → explanation_pointer which the analyst can reason on.
When you dive into streaming, the operational risks are also higher: latency constraints make it hard to get much evidence per event, and fast rule changes can lead to gaps in identity that last very long. It is why change management is part of the culture of the company:
- Explicitly match the version rules and keep the version with each mapping.
- Test threshold changes backtest changes prior to deployment, as small threshold shifts could lead to large merge/split cascades.
- Sample matches for human review, in particular within the threshold boundary region.
- Keep rollback paths, because identity errors are very rarely reversible without replay etc.
This reflects a broader theme in reliable AI: systems are trusted not because they’re “smart,” but because they limit uncertainty and behave predictably at their edges.
Bio:
Meihui Chen is a Senior Data Scientist at Intuit, where she builds data platforms and applied machine learning systems focused on marketing and product analytics, identity resolution, measurement, and privacy-aware analytics.



