
In today’s fast-evolving world of AI, the importance of product success can be easily overstated. Working for big tech companies like Amazon and Capital One, I have been constantly behind finding new solutions to value various new features and products. In this article, I like to introduce a framework that can help us quantify the product success.
The Launch Illusion
In the fast-moving world of digital products, every launch is a celebration. New features arrive with promises of smoother user journeys, smarter recommendations, or eye-catching designs that will delight customers and boost revenues. And often, the first results look promising. Revenue ticks upward, engagement grows, and product managers breathe a sigh of relief.
But hidden inside these “successful” launches is often an uncomfortable truth: not all features contribute equally. Some silently drag down user experience and erode long-term value. A flashy new widget might confuse customers. A promotional button might look helpful but actually deter purchases. These subtle negative effects are hard to detect because traditional methods measure averages, and averages conceal as much as they reveal.
Measuring Responsibility Fairly
My recent worked on building a framework called Negative Feature Attribution via Constrained Shapley (N-FACS). The idea is simple yet transformative: instead of only celebrating what works, measure what hurts.
The inspiration comes from cooperative game theory, where Shapley values are used to fairly divide contributions among players in a coalition. In the context of product launches, the “players” are the individual features. Shapley values simulate every possible order in which features could be introduced, and then calculate the fair share of each feature’s responsibility.
Formally, the Shapley value for a feature j is:
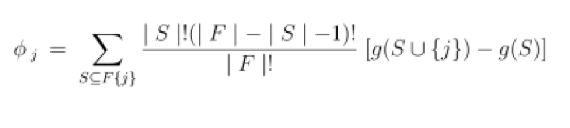
Here, g(S) is the outcome when only the subset S of features is active. The formula ensures fairness: every feature gets credit (or blame) proportional to its true contribution, no matter the order of rollout.
What N-FACS does differently is constrain this attribution to only negative contributions. Positive effects are ignored, ensuring that underperforming features can’t hide behind their more successful siblings.
A Car with a Flawed Infotainment System
To make this tangible, imagine a new car model. The engine is more efficient, the suspension smoother, and sales surge. But the redesigned infotainment system confuses drivers, leading to distracted driving. A traditional review would still call the car a success. But anyone stuck with that glitch knows otherwise.
N-FACS is like the diagnostic tool that isolates the infotainment problem, quantifies its harm, and tells engineers whether to fix or remove it. The goal isn’t to dismiss the entire car, but to surgically identify the one component dragging it down.
Stories from the Digital World
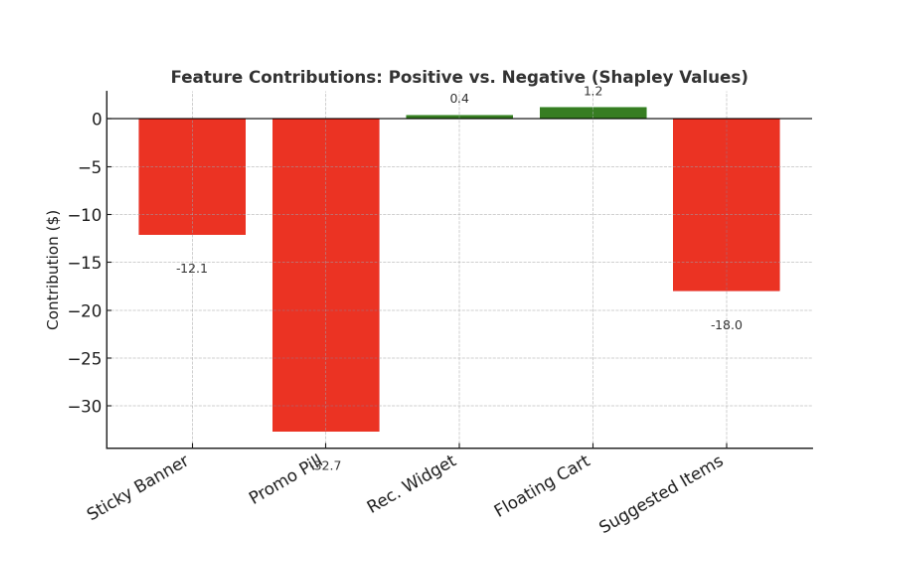
Consider e-commerce. A major retailer launches several checkout features: a floating cart button, a personalized recommendation widget, and a promotional discount pill. Overall sales rise, so the launch seems like a win. But with N-FACS, the retailer might discover that while the floating cart and recommendations help, the discount pill actually reduces conversions. Customers find its inconsistent pricing confusing and abandon their carts. Without this analysis, the company might never realize that the feature designed to boost sales was silently costing revenue.
In fintech, the story could play out differently. A bank adds a “quick loan approval” button. On average, applications rise. But certain customers interpret it as aggressive marketing and lose trust, closing their accounts. N-FACS would reveal this hidden downside before it snowballs into reputational damage.
Or in streaming services, imagine a new recommendation system that increases total viewing time but narrows diversity of content for some users. Those users become dissatisfied and churn. N-FACS ensures product teams see not just the upside but also the collateral damage.
Even in healthcare apps, small design choices can matter. A motivational reminder could inspire many, but frustrate or demotivate vulnerable users. Traditional analytics would miss this nuance. N-FACS captures it.
Toward Smarter Launches
What excites me about this framework is how it shifts the culture of product development. For years, success has been measured by growth metrics: more clicks, more time, more revenue. But in the rush to highlight gains, teams often ignore the hidden costs.
By quantifying negative impacts with rigorous math, N-FACS empowers teams to ask the harder, more valuable question: which parts of our product are quietly failing us? It gives designers evidence to improve experiences, managers confidence to make selective rollbacks, and executives visibility into hidden product debt.
Conclusion: Subtraction as Innovation
In a digital world where launches happen daily, it’s not enough to ask “Did this product work?” We must ask, “Which parts helped, and which parts hurt?” Success isn’t always about adding more. Sometimes, it’s about knowing what to subtract.
With N-FACS, we finally have a way to see those hidden flaws — and build products that are not just bigger, but better.

