Long before large language models could write poetry or neural networks could identify tumours in X-rays, AI researchers were obsessed with something far simpler. Card games.
Not as a hobby. As a proving ground.
The quest to build machines that could play cards, bluff opponents, and calculate odds under uncertainty shaped artificial intelligence in ways most people never hear about. And the lessons learned from shuffled decks still echo through the AI systems we use today.
When Machines First Learned to Think Through Games
Claude Shannon published “Programming a Computer for Playing Chess” in 1950, laying out the mathematical framework for how a machine could evaluate positions and choose moves.
Shannon wasn’t just building a chess player. He was testing whether computers could mimic strategic thought, believing that cracking games would open the door to attacking more significant problems.
Chess was perfect information. Both players see the entire board. But Shannon’s framework planted a seed: if machines could handle strategy in a controlled environment, maybe they could eventually handle messier ones.
In 1952, Arthur Samuel at IBM began work on a checkers program that didn’t just follow rules. It learned from its own games, adjusting its strategy after thousands of matches against itself. By 1959, Samuel published “Some Studies in Machine Learning Using the Game of Checkers,” popularising a term we now use constantly: machine learning. His program eventually defeated Robert Nealey, one of America’s top-ranked checkers players, in a landmark 1961 match.
These early game-playing programs weren’t about entertainment. They were building blocks for a question that would haunt AI research for decades. What happens when the machine can’t see all the cards?
The Imperfect Information Problem That Changed Everything
Chess and checkers are transparent. Every piece sits visible on the board. Card games broke that model completely.
Poker, in particular, forced researchers to grapple with hidden information, deception, and probability in ways board games never did. You don’t know your opponent’s hand. You don’t know what cards are coming next. You have to make decisions with incomplete data and somehow still win.
This is where game theory entered the picture. Mathematicians and computer scientists realised that poker wasn’t just a gambling game. It was a formal model for decision-making under uncertainty. The strategies that worked in poker (mixing actions unpredictably, reading patterns in opponents’ behaviour, balancing risk against potential reward) mapped directly onto real-world problems from military strategy to economic negotiations.
For AI researchers, card games became the frontier. Perfect information was solved territory. Imperfect information was where the hard problems lived.
Solitaire and the Hidden Depths of Computational Complexity
Not every card game involves bluffing an opponent. Single-player games like Klondike solitaire posed a different kind of challenge, one rooted in pure computational complexity.
Here’s a fact that surprises most people: determining whether a given Klondike deal is winnable has been proven NP-complete. That means as the problem scales, no known algorithm can solve it efficiently in every case. Roughly 82% of standard deals are solvable, but figuring out which ones, with certainty, is computationally brutal.
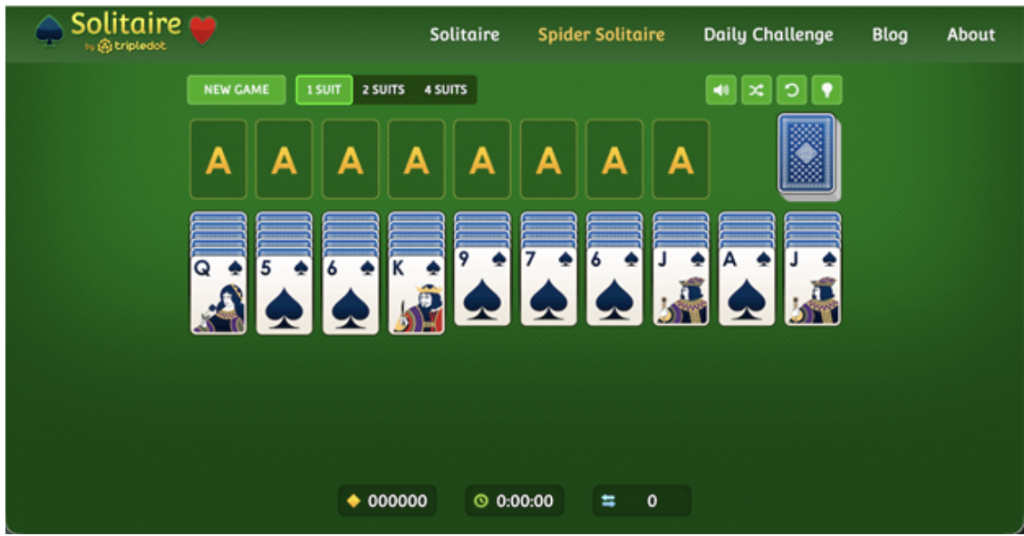
Spider Solitaire takes this complexity even further. The game comes in one-suit, two-suit, and four-suit variants, and each additional suit doesn’t just add difficulty for human players. It expands the decision space exponentially. The four-suit version has a win rate of around 5 to 8%, and a generalised version of Spider Solitaire has been formally proven NP-complete by researcher Jesse Stern in 2011 using reduction from 3-SAT. For complexity theorists, these games became compact, elegant testbeds for studying problems that resist efficient solutions.
Solitaire variants taught researchers something practical too. Sometimes the most interesting computational problems aren’t adversarial. They’re structural puzzles hiding inside seemingly simple systems.
How Poker AI Cracked the Code on Superhuman Play
The real breakthrough came in the 2010s, when decades of theoretical work finally produced machines that could outplay the best humans at poker.
In January 2017, Libratus entered a 20-day heads-up no-limit Texas hold’em competition against four top professional players at Rivers Casino in Pittsburgh. Built by Carnegie Mellon’s Tuomas Sandholm and his PhD student Noam Brown, Libratus played 120,000 hands and finished with a collective lead of over $1.76 million in chips. What made Libratus remarkable was its overnight learning. Each night it analysed its own losses from the day, patching weaknesses in its strategy before the next session began.
Two years later, Brown and Sandholm (now collaborating with Facebook AI Research) unveiled Pluribus, the first AI to beat professionals in six-player no-limit hold’em. This was a leap. Handling five opponents simultaneously, each with hidden cards and unpredictable strategies, was exponentially harder than heads-up play. Pluribus trained by playing against copies of itself and computed its base strategy in just eight days on modest hardware costing roughly $144 in cloud compute time.
Meanwhile, the card game bridge attracted its own milestone. In 2022, NukkAI’s NooK system defeated eight world champion bridge players, winning 67 out of 80 sets – an 83% win rate. Bridge adds cooperative play on top of hidden information – players must communicate through bidding conventions with a partner – making it a unique AI challenge.
From Card Tables to the AI That Reasons Under Uncertainty
The through-line from Shannon’s 1950 chess paper to today’s large language models runs directly through card game research.
Here’s why that matters. Perfect-information games taught machines to search and evaluate. Card games taught them to reason under uncertainty, model what opponents might be thinking, and make good decisions without complete data.
Modern LLMs face a version of this same problem constantly. When a language model generates a response, it’s working with incomplete context, ambiguous prompts, and no guarantee that any single answer is correct. The mathematical tools that Sandholm, Brown, and others developed for poker AI – techniques like counterfactual regret minimisation – overlap with the broader challenge of building systems that handle ambiguity gracefully.
Card games didn’t just entertain AI researchers. They forced a fundamental shift in how we think about machine intelligence – from systems that calculate perfect answers to systems that navigate an uncertain world. Every time you interact with an AI that hedges, qualifies, or weighs competing possibilities, you’re seeing the legacy of researchers who sat down and asked a deceptively simple question.
Can a machine play cards?