
AI has grown exponentially in recent years thanks to the release of ChatGPT.
What is intelligence?
Intelligence is a complex concept. From the ancient Greeks to modern-day researchers, defining intelligence has been a central theme when studying the human mind. The ancient Greek philosophers Plato and Aristotle laid the foundation for later theories of intelligence, with Plato emphasizing the concept of innate knowledge and learning through reason, whereas Aristotle focused on learning through experience.
AI currently leads the intelligence debate, but the field long lacked a clear definition of intelligence. In 2007, DeepMind co-founder Shane Legg addressed this issue by analyzing ten definitions of intelligence. He then proposed a definition that captures its general essence:
“Intelligence measures an agent’s ability to achieve goals in a wide range of environments.”
Intelligence is broken down into three components: an agent, an environment, and goals. But in Legg’s definition, the key characteristic of intelligence is generality – a component previously missing from AI systems.
The birth of artificial intelligence
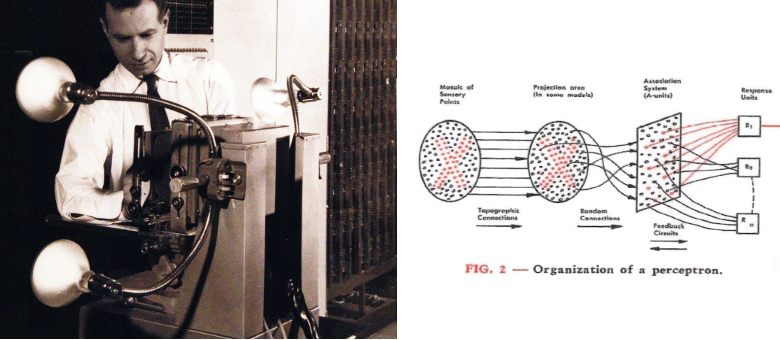
In 1943, neuropsychologist Warren McCulloch and logician Walter Pitts proposed the first mathematical model of a neuron. While elegantly simple, it was unable to learn from data. In 1957, Rosenblatt’s perceptron introduced the first learning algorithm for artificial neutrons. This aligned with Aristotle’s view of learning from experience, sparking intense interest in artificial intelligence through the 1960s. By 1965, H. A. Simon boldly stated, “Machines will be capable, within twenty years, of doing any work a man can do.”
However, this optimism quickly faded; expectations were not met, leading to the first “AI winter” of the 1970s. Interest returned in the 1980s with “expert systems” which solved specific problems through domain expert knowledge, but despite initial success, this renewed interest was short-lived, leading to a second AI winter in the late 1980s.
Despite these setbacks, in the 1990s and early 2000s the application of rigorous statistical techniques to the field led to the development of powerful new algorithms with weird and wonderful names such as support vector machines (1992), AdaBoost (1995), and random forests (2006). Due to the limited computational power of the time, these algorithms relied on feature engineering, which involves hand-selecting and transforming raw data into useful inputs for a machine learning model. This all changed with the deep learning era.
The Dawn of Deep Learning
The rise of cloud computing, the internet, and big data led to a new AI paradigm. Deep neural networks process raw data without relying on hand-crafted feature engineering. These networks develop their own representations from raw inputs, given sufficient data and enough parameters. Within these networks, intermediate numerical representations are repeatedly combined with model parameters to generate an output. This approach aligned well with the new form of computing – general-purpose GPU.
Throughout the 2010s deep learning, big data, and GPU computing created breakthroughs in machine translation, object detection and speech recognition Success was driven by the quantity of the two key ingredients: data and computational power. But this approach revealed a problem: one ingredient was overpowering the other.
The rise of large language models
Since the invention of the semiconductor, Moore’s Law predicted that the number of transistors on an integrated circuit doubles every two years. Recently, Nvidia achieved a 1,000x single GPU performance increase over 8 years, far surpassing Moore’s prediction. Although Moore’s Law continues to hold at the transistor level, this performance increase was achieved through a focus on the entire GPU computing stack, including architecture, software, and algorithms.
The size of annotated datasets couldn’t keep up with GPUs’ exponential growth, despite better annotation tools. The solution has been to use self-supervised learning, where a machine learning system learns directly from unlabeled data. In this way, terabytes of internet data can be used to train models without human annotation.
Scaling compute, model size, and data has led to the era of Large Language Models (LLMs). While previous small language models were limited to performing single tasks, LLMs handle a wide range of tasks and accept task instructions in natural language.
Legg and Aristotle’s definitions of intelligence are therefore partially met – LLMs can handle a wide range of tasks and have learned skills through experience and observation. However, LLMs are prone to hallucinations – plausible responses not grounded in fact – meaning Plato’s intelligence definition remains unmet.
A future fueled by exponential growth
AI has grown exponentially these past two years due to the release of ChatGPT. Investment into hardware, software, data and algorithms is growing daily, increasing model capabilities.
The race is on to train ever-larger models with higher capabilities. This year we have seen mainstream adoption of multi-modal models that understand images, video, and audio data. Models’ ability to reason, plan, and act on their environment is starting to become reality, bringing Plato and Legg’s intelligence to machines.
While predicting exponential growth may be challenging, one thing is clear: the future will be increasingly shaped by Generative AI models that exhibit broad intelligence and can adapt to a wide range of tasks. As the field continues to grow, so will the potential of this technology, shaping the world in ways beyond imagination.




