
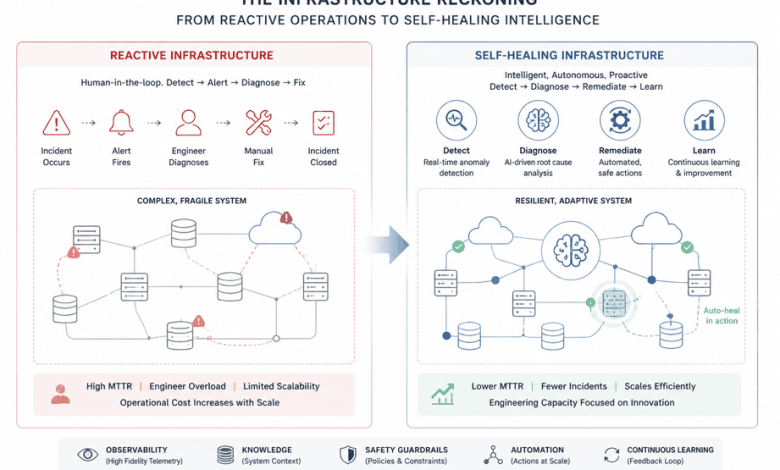
Most enterprise cloud platforms are still running on reactive infrastructure. Something breaks. An alert fires. An engineer gets paged. The engineer diagnoses the problem, applies a fix, and closes the incident. This cycle repeats thousands of times a year, consuming engineering capacity that could be building new capabilities instead of managing failures that should never have required human intervention in the first place.
I have spent over two decades building and operating large-scale enterprise systems, first at VMware and SAP, and now at Salesforce, where I architect the intelligent, self-healing cloud platforms that power some of the most demanding enterprise environments in the world. What I have come to believe, after watching infrastructure management practices evolve across three major platform companies, is that the gap between reactive and proactive infrastructure is one of the largest untapped opportunities in enterprise technology.
The organizations that figure out how to build self-healing systems, systems that can detect, diagnose, and correct their own failures without human intervention, will have a structural advantage over those that continue to scale reactive operations. This is not a future aspiration. The components are available today. The question is whether engineering organizations are willing to invest in the infrastructure discipline required to make it real.
The Scale Problem Is Getting Worse
The deployment scalability challenge at enterprise organizations is well documented but not always fully understood. I once led platform framework development and infrastructure innovations adopted by more than 100 internal teams and external customers, the scale of operations creates operational demands that are fundamentally different from what most engineering organizations encounter.
When I led the initiative that tripled deployment scalability across a major platform, the bottleneck was not compute capacity or network bandwidth. It was human capacity. Every deployment requires human oversight. Every incident requires human diagnosis. Every capacity planning decision requires human judgment. As deployment volume scales, the human overhead scales with it, and the systems that were designed to empower engineering teams become systems that consume engineering capacity at an unsustainable rate.
The math does not work long-term. An organization that doubles its deployment frequency every year cannot sustain a model where each deployment requires the same level of human involvement. At some point, either the organization stops scaling deployments, or it finds ways to reduce the human involvement per deployment.
The solution is not to hire more engineers. It is to build infrastructure that requires less human involvement per unit of operational output.
What Self-Healing Infrastructure Actually Means
The term self-healing infrastructure gets used in ways that range from accurate to aspirational to pure marketing. I want to be specific about what I mean when I describe a platform as self-healing.
A self-healing system can detect anomalies in its own behavior. It can diagnose the likely cause of those anomalies with sufficient confidence to take action. And it can apply corrective action that resolves the problem or mitigates its impact without requiring a human to be in the loop.
This is not the same as autonomous infrastructure, which would imply systems that operate entirely without human oversight. That is neither achievable nor desirable for most enterprise systems. The goal is to move a meaningful portion of routine operational decisions out of the human loop, freeing engineers to focus on the problems that actually require human judgment.
At Vmware, I led the development of platform frameworks that move in this direction. The work involved several distinct capabilities that are worth describing in detail because they are the foundation of anything that calls itself self-healing.
Anomaly detection at scale. The first requirement is the ability to observe system behavior with sufficient granularity and timeliness to detect deviations from normal. This sounds straightforward, but building high-observability platforms across complex distributed ecosystems requires significant investment in instrumentation, metric collection, and alerting infrastructure. The systems that detect anomalies reliably are the ones where engineers have been deliberate about defining what normal looks like and building the data pipelines that surface deviations quickly.
Automated diagnosis with confidence levels. Detecting an anomaly is not the same as knowing what caused it. A spike in error rates could be caused by a code deployment, a traffic anomaly, a dependency failure, a resource constraint, or any number of other factors. A self-healing system needs enough context to attribute the anomaly to a likely cause with sufficient confidence to justify automated action.
This is where I have seen most self-healing initiatives stall. The diagnosis layer requires deep knowledge of the system’s architecture, the relationships between components, and the historical patterns of failures. Building that knowledge into an automated system is a significant engineering investment, and it is an investment that most organizations underfund because the return is less visible than the return on a new feature.
Automated remediation with safety rails. When a system has diagnosed a failure with sufficient confidence, it can apply corrective action. The nature of that action depends on the failure mode. In some cases, it is simple: restart a failed service, scale up a constrained resource, route traffic around a degraded component. In other cases, the appropriate response is more nuanced, and the system needs to apply a graduated response that escalates if initial remediation does not resolve the problem.
The safety rails are essential. Automated remediation that cannot be overridden or rolled back is a liability. The self-healing systems I have built include explicit rollback mechanisms, human-in-the-loop checkpoints for high-risk actions, and comprehensive logging that allows engineers to understand what the system did and why.
The Observability Imperative
If there is one theme that runs through everything I have learned about building resilient enterprise platforms, it is this: observability is the foundation.
I have transformed complex distributed ecosystems into resilient, high-observability platforms at three major enterprise software companies. The pattern is consistent. Organizations that invest in observability infrastructure early consistently outperform organizations that treat it as a lower priority than feature development. When something goes wrong in a well-observed system, engineers can diagnose it in minutes. When something goes wrong in a poorly observed system, engineers spend hours reconstructing what happened from fragmentary data, if they can reconstruct it at all.
The return on investment in observability is high and underappreciated. A team that spends three months building comprehensive instrumentation for a platform will save more than three months of incident resolution time over the following year. The problem is that the cost of poor observability is diffuse and deferred, while the investment in observability is immediate and visible. This creates a systematic bias toward underinvesting in infrastructure visibility that is difficult to overcome without deliberate leadership attention.
For AI systems in particular, observability requirements are more demanding than for traditional software. In a conventional backend system, you can infer the health of the system from request rates, error rates, and latency distributions. In an AI inference system, you also need to understand whether the model is producing sensible outputs, whether input distributions are shifting in ways that affect model behavior, and whether the data pipelines that feed the model are operating correctly. The observability stack for AI infrastructure is broader and deeper than the stack for traditional systems.
The Cost Optimization Story Nobody Talks About
Cloud cost optimization is consistently listed as a priority for enterprise engineering organizations. It rarely gets the investment it deserves because the tools and techniques required for meaningful cost reduction are more complex than the dashboards and alerts that most cloud cost monitoring tools provide.
One of the outcomes I am most proud of from my platform engineering work is the initiative that cut cloud costs by 20 percent across a major enterprise platform. This was not achieved through better vendor negotiations or reserved instance purchasing, though those have their place. It was achieved through infrastructure intelligence: understanding how compute resources were actually being consumed, identifying the patterns of waste that are invisible in aggregate cost reports, and building automated mechanisms to right-size and scale resources based on actual demand rather than provisioned capacity.
The waste in most enterprise cloud environments is significant and structural. Teams provision capacity for peak load and let it sit idle most of the time. Deployment pipelines over-provision resources because engineers do not have visibility into actual resource consumption patterns. Infrastructure that was provisioned for a specific use case continues running after that use case is deprecated or replaced. These patterns are individually small but collectively substantial.
Addressing them requires the same capabilities as self-healing infrastructure: deep observability into resource consumption, automated diagnosis of waste patterns, and automated remediation that rightsizes or decommissions resources without human involvement. The investment is similar, and the return on that investment includes both improved reliability and meaningful cost reduction.
Platform Thinking as a Force Multiplier
One of the most important shifts in my career was moving from thinking about individual services to thinking about platforms. The distinction matters because platforms multiply the impact of every engineer who uses them.
At SAP, I led the design of platform frameworks that were adopted by more than 100 teams across the organization. The value was not in the framework code itself. It was in the operational leverage that the framework provided. Teams that built on the platform inherited its reliability patterns, its observability capabilities, and its self-healing mechanisms without having to build them independently. The platform team made an investment once, and that investment generated returns every time a new team onboarded.
This is the platform engineering model that is gaining traction in enterprise organizations, and for good reason. When every team builds its own infrastructure from scratch, the average quality of infrastructure is constrained by the least experienced team. When teams build on a shared platform, the average quality rises to the quality of the platform, and the most experienced engineers can focus on improving the platform rather than rebuilding the same capabilities in every service.
The connection to AI is direct. The organizations that are succeeding with AI in production are largely the ones that have invested in platform engineering as a discipline. They have built the infrastructure foundations that make AI deployment reliable, the observability layers that make AI behavior visible, and the self-healing mechanisms that make AI systems resilient. The organizations that are struggling with AI in production are largely the ones that are trying to deploy AI on top of infrastructure that was not designed to support it.
What Engineering Leaders Should Do
If I were advising engineering leaders on where to focus infrastructure investment over the next several years, I would start with three priorities.
Treat observability as a first-class engineering concern. Not as a feature of the platform, not as a nice-to-have that gets attention when incidents reveal gaps, but as a first-class engineering concern with the same priority as performance, reliability, and security. The teams that build observability into their infrastructure from the start consistently spend less time firefighting and more time building.
Invest in platform engineering as a strategic capability. The ROI on platform infrastructure is high and grows over time. Every team that builds on a shared platform generates compounding returns on the investment that platform team made. This requires leadership attention and budget allocation that is often difficult to justify against product feature priorities, but the organizations that build strong platform capabilities are the ones that sustain high velocity over time.
Build self-healing capability incrementally, starting with the highest-frequency failure modes. A system that can automatically remediate 20 percent of routine failures, the ones that consume the most on-call time without requiring complex judgment, is worth more than an aspirational roadmap that promises full autonomy but delivers nothing. Start with the failures that are most predictable, most diagnosable, and most safely remediated automatically. Build from there.
The Infrastructure That Will Matter
The next several years will test the infrastructure choices that enterprise organizations are making today. AI is becoming a core operational dependency in ways that hardware or software infrastructure has not been before. The systems that fail in AI contexts will not just degrade application performance. They will degrade the decisions that depend on AI outputs, with consequences that are harder to predict and harder to recover from.
Building infrastructure that can support AI at that level of criticality requires the same discipline, rigor, and investment that enterprise organizations apply to other forms of critical infrastructure. It requires platform thinking, observability investment, and a commitment to engineering excellence that is visible at every layer of the stack.
The organizations that make that investment will have infrastructure that supports their ambitions. The ones that do not will spend their time managing the consequences.


