
CelerData has announced StarRocks 4.0, a major version release of the open-source analytics database that serves as the core of its lakehouse platform. The update is said to enable faster and more concurrent analytics to better serve the needs of rapidly scaling AI and machine learning workloads across modern enterprises. Organizations are scaling out their model training and inference systems, adding new production AI agents for autonomous applications and specialized services, leading to demand for extremely fast and governed, highly concurrent analytics. The platform is intended to help data teams serve those workloads by combining an open data lake architecture with the speed of performance typically associated with more closely governed data warehouses.
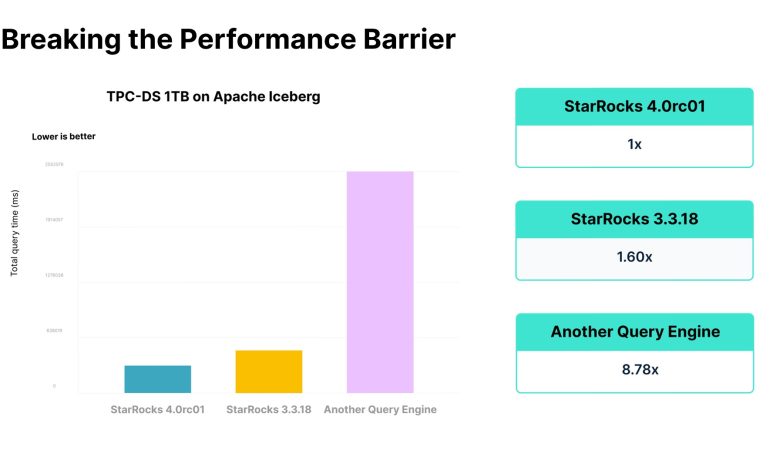
The company claims that analytics performance is up to sixty percent faster than the previous version of the software. These performance improvements are said to result from enhancements to the platform’s join, aggregation, and spill management operations, combined with an upgraded execution engine that promotes parallelism while lowering CPU consumption. The net effect is more predictable performance for demanding analytics workloads such as those required to continuously feed AI models with the latest data, on a massive scale. When serving agent-driven applications or AI systems with continuously running inference pipelines, this is said to mean the stability and responsiveness users expect from tightly managed data warehouses.
New to StarRocks 4.0 is Flat JSON V2, which offers a new method for querying semistructured JSON data at speeds that are closer to what would be possible with structured data. This update is said to allow AI teams to use logs, clickstreams, and other user-behavior datasets to train models or generate real-time features at scale, without the need to flatten or restructure existing pipelines. Query speeds for JSON data are said to be as much as fifteen times faster as a result of the new format, which could be used by AI systems that require high-speed access to high-volume telemetry.
The latest version also improves the efficiency of analytics running directly on cloud object storage, a data architecture favored by many AI and machine learning platforms that ingest and store large datasets from multiple vendors. Bundling and metadata caching improvements, along with a new compaction strategy, are said to reduce cloud API calls and help keep high concurrency workloads performing with lower latency. This feature is said to help AI teams that require continuous retrieval and updates to training or inference data without latency or unnecessary cloud costs.
Apache Iceberg is also integrated more deeply into the platform through updates that bring the open table format capabilities to the governance features of more traditional data warehouses. Changes to partitioning, write optimization, metadata parsing, and file compaction and compaction are said to make Iceberg tables easier to manage at scale, while delivering more predictable query performance. This could be particularly important to AI teams that work with versioned datasets, incremental training sets, or historical datasets that require long-term archives at extreme scale. Even when table statistics are stale or partially missing, StarRocks is said to be able to better optimize execution plans to avoid performance degradation.
Governance has also been improved to better meet the compliance requirements of multi-cloud AI deployments. A new catalog-centric access control system is intended to bring identity and permissions management to a common baseline across different deployments. Support for JWT-based session catalogs and ephemeral cloud credentials is said to avoid the need for hard-coded storage credentials and simplify cross-cloud access to data for AI teams, while maintaining enterprise security.
StarRocks 4.0 also includes a new set of features that are intended to help workloads that require high accuracy or transactional reliability, such as financial services, scientific applications, and time-series analytics. The addition of Decimal256 arithmetic is said to allow exact calculations to scale at extremely large numerical values. Multi-statement transactions are also said to improve consistency for certain workflows that span multiple tables. The ability to incrementally train on newly ingested data can help avoid problems that are introduced by frequently refreshing datasets. AI users in such domains might leverage those features for market forecasting, industrial telemetry, or sequential learning applications.