
Soul Zhang Lu Team Open-Sources SoulX-LiveAct: From “Able to Generate” to “Able to Generate Stably Over Extended Periods”
As AI technology accelerates its adoption in digital human live streaming, video podcasts, and real-time interactive scenarios, user expectations for content continuity and performance consistency continue to rise. Against this backdrop, the Soul Zhang Lu team has carried out systematic optimization of real-time digital human generation technology, releasing the open-source model SoulX-LiveAct to further strengthen its technical position in the real-time digital human generation space.
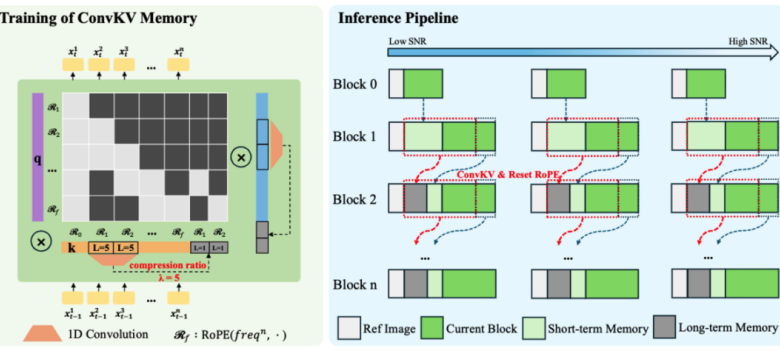
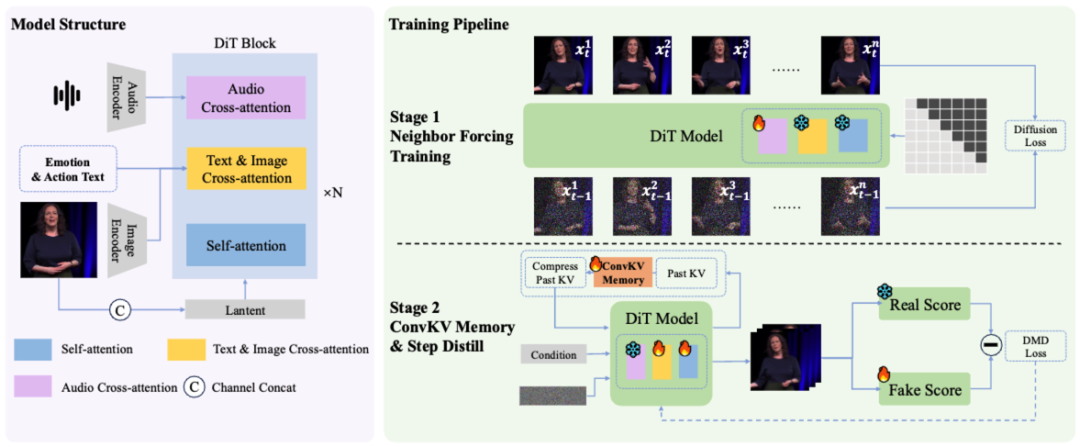
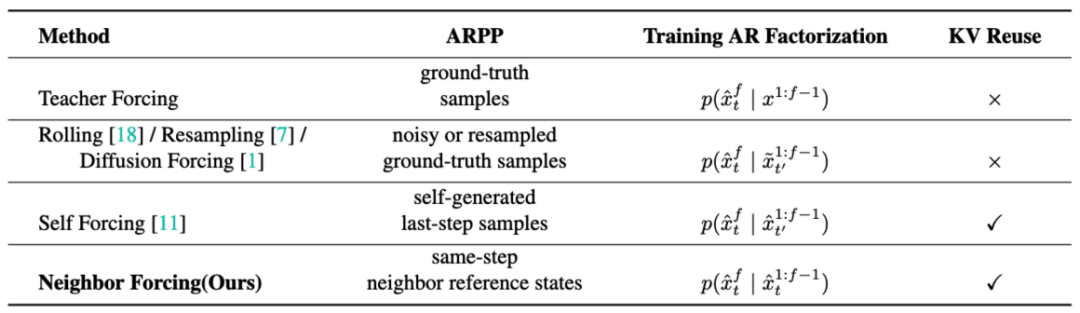
SoulX-LiveAct centers on the core challenge of long-duration continuous generation, employing autoregressive diffusion (AR Diffusion) as its foundational framework and achieving performance improvements through the Neighbor Forcing mechanism and ConvKV Memory mechanism. The model generates video in a chunk-by-chunk fashion, with the diffusion model handling detail modeling within each chunk and contextual information flowing between chunks to enable continuous streaming generation. Building on this, the Neighbor Forcing mechanism aligns adjacent-frame latents within the same diffusion step, ensuring the model maintains a consistent noise semantic space across training and inference, thereby reducing error accumulation caused by distributional inconsistencies.
Meanwhile, the ConvKV Memory mechanism introduces structural optimization to the KV cache in traditional attention mechanisms. It partitions historical information into two components: a “high-precision short-term window” and “compressed long-term memory.” The former preserves local detail and consistency, while the latter compresses information through lightweight convolution into fixed-length historical representations.
To enhance long-sequence stability, SoulX-LiveAct incorporates a RoPE Reset mechanism that periodically realigns position encodings, preventing positional drift as sequences grow. During training, the model not only uses Neighbor Forcing to align training distributions but also constructs long-sequence chunk training samples, enabling the model to directly confront error accumulation and correction processes during training. Additionally, a Memory-Aware training approach consistent with inference is introduced, allowing the model to maintain stable performance under compressed memory conditions—reducing performance fluctuations stemming from train-inference discrepancies at the source.
In terms of inference performance, SoulX-LiveAct transforms historical context from a variable-size cache into a fixed-budget memory structure, achieving constant GPU memory inference—meaning inference memory usage does not grow as video duration increases. Furthermore, the combination of short-term windows and compressed long-term memory keeps computational and communication costs stable for each chunk, preventing latency accumulation during long-video generation. At 512×512 resolution, the system achieves 20 FPS streaming inference on 2×H100/H200 hardware, with end-to-end latency of approximately 0.94 seconds and per-frame computational cost of 27.2 TFLOPs.
Across multiple benchmark evaluations, SoulX-LiveAct demonstrates strong comprehensive capabilities. On the HDTF dataset, the model scores 9.40 for Sync-C and 6.76 for Sync-D, achieves distribution similarity scores of 10.05 FID and 69.43 FVD, and earns 97.6 Temporal Quality and 63.0 Image Quality in VBench, with VBench-2.0 Human Fidelity reaching 99.9. On the EMTD dataset, the model maintains leading performance with 8.61 Sync-C and 7.29 Sync-D, achieving 97.3 Temporal Quality and 65.7 Image Quality in VBench, with Human Fidelity at 98.9. These results indicate the model’s high proficiency in lip-sync accuracy, motion consistency, and long-duration stability.
Leveraging these capabilities, SoulX-LiveAct supports a variety of sustained online scenarios, including digital human live streaming, AI-powered education, smart service terminals, premium content delivery, and podcast production. In open-world interactive environments, where the demand for characters to “maintain consistent expression over time” is even greater, SoulX-LiveAct’s performance on the EMTD dataset and its real-time streaming capabilities provide the foundational capacity for sustained online interaction.
Since the beginning of this year, the Soul Zhang Lu team has successively open-sourced SoulX-FlashTalk and SoulX-FlashHead. SoulX-FlashTalk is a 14B-parameter model that achieves sub-second latency of 0.87s at 32 fps while supporting stable long-video generation. SoulX-FlashHead is a lightweight 1.3B model capable of 96 FPS inference on a single RTX 4090 GPU. Building on these, SoulX-LiveAct further fills the gap in “long-duration stable generation” capabilities.
In its open-source strategy, the Soul Zhang Lu team continues to publicly share its technical achievements, driving the iteration of its own AI infrastructure while providing developers with reusable tools. Through collaboration with the global developer community, these technologies are continuously expanding application boundaries and fostering a more dynamic AI application ecosystem.
