

Large language models handle impressive workloads, yet their reliability varies when the context is complex or the stakes are high. In enterprise settings, especially healthcare, precision is the benchmark. A mistaken justification or misread symptom influences billing accuracy, compliance review, and the quality of care that follows.
Static prompts often fall short in these contexts. They assume a fixed environment, degrade as edge cases accumulate, and offer no internal mechanism for correcting drift. Self-validation introduces a feedback process. Rather than depending on a single prompt, the model reviews its own reasoning, identifies weaknesses, and attempts the task again with sharper constraints. This process allows the system to adapt to each situation and correct itself when necessary.
Recursive meta-prompting enhances this approach. The model produces an answer, critiques its process, and then writes improved instructions for the next attempt. This repeated cycle reduces hallucinatory details, produces more consistent logic, and adapts across varied situations.
This article breaks down how recursive meta-prompting works, how it compares to other self-correction methods, and why it matters for enterprise deployments.
What Recursive Meta-Prompting Actually Means
Recursive meta-prompting treats prompts as adaptable functions that can be improved rather than static instructions. In the formal framing, a meta-prompt is a functor that transforms a task into a new prompt tailored to it.
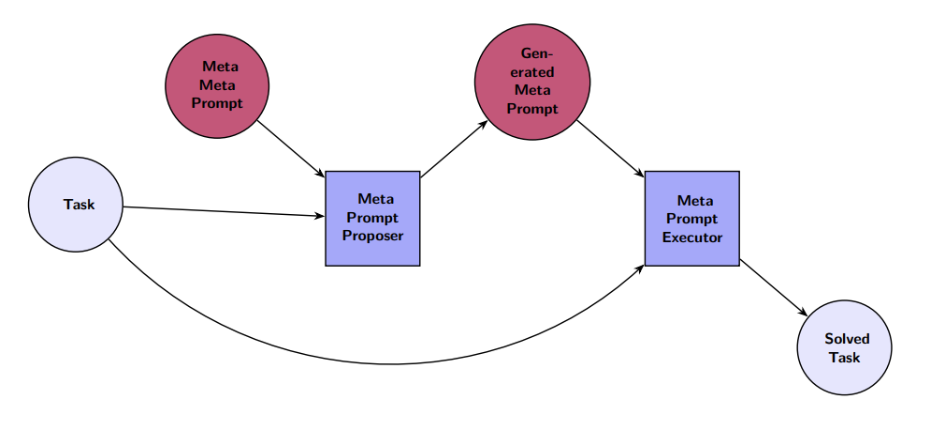
An illustration of Recursive Meta Prompting with a single recursion step.
Source: Meta prompting for AI systems | Zhang et al.
The process focuses on refining the prompt architecture instead of revising the output. The diagram above illustrates a sequence representing recursive meta-prompting with a single recursion step:
- The model receives the task T.
- It generates a meta-prompt M(T) that defines how the task should be handled.
- The model checks whether M(T) captures the task requirements.
- If it does, the model applies M(T) to produce the final output.
The model uses this structure to adjust how it approaches the problem, sometimes generating a prompt that, in deeper layers of recursion, generates another prompt. This mirrors metaprogramming, where a system creates the instructions that guide its own execution.
Other self-correction systems target different parts of the reasoning process. Chain-of-Thought prompting, for example, helps the model articulate intermediate reasoning, which improves accuracy in math, symbolic tasks, and commonsense questions.
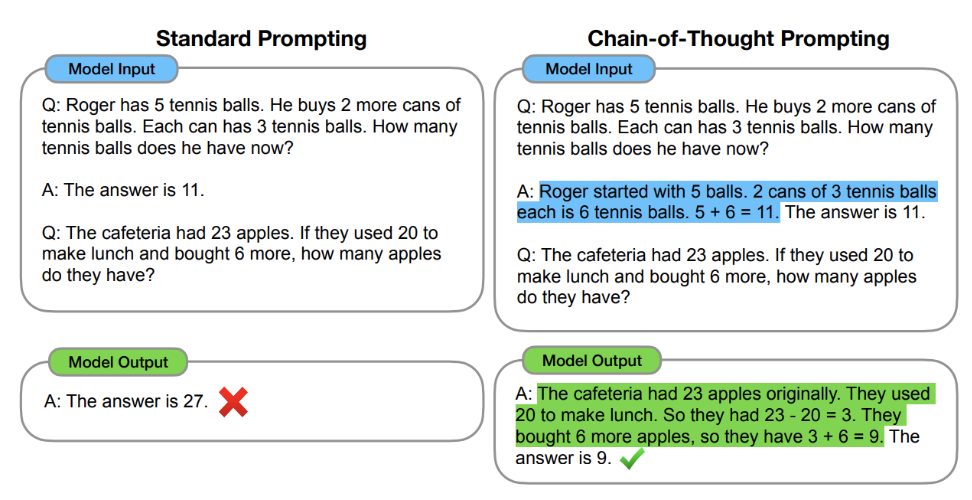
Diagram comparing standard vs. chain-of-thought prompting.
Source: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | Wei et al.
Self-Refine uses a draft-feedback-rewrite cycle that strengthens text generation and code repair without additional training. Reflexion extends this by storing reflections that guide future attempts, creating continuity across multiple trials.
Recursive meta-prompting operates differently. Instead of correcting model outputs, it corrects the instructions that shape those outputs. This gives the system a stable way to revise its own problem-solving structure and adapt to the specific constraints of each task.
Here’s a table comparing how each system operates within the reasoning process.
| Method | Core Idea | Strength | Constraint |
| Recursive Meta-Prompting | Generates and updates prompts for the task | Stable, adaptable prompt design | Extra computation per refinement loop |
| Chain-of-Thought | Produces intermediate reasoning steps | Clearer logic | No built-in validation |
| Self-Refine | Draft → feedback → rewrite | Stronger outputs | Works at the output level |
| Reflexion | Stores reflections for later attempts | Better long-horizon tasks | Depends on accurate self-assessment |
Recursive validation matters most when accuracy and consistency are non-negotiable. Its impact is easiest to see in applied settings, like behavioral health.
Implementation in Behavioral Health AI

Image: Using a chatbot in healthcare by khunkornStudio | Shutterstock
In behavioral health, clinical notes must stand up to audit, compliance, and the realities of real-world patient sessions. At Nudge AI, for instance, the system doesn’t merely refine phrasing. It rebuilds the narrative, analyzes diagnostic reasoning, and verifies CPT codes through structured cycles.
When an AI scribe produces a draft, it doesn’t proceed unchecked. Meta-prompts review diagnostic language, safety markers, session details, justification rules, and complexity. If issues arise, the model reconstructs the entire note rather than fixing small sections. This prevents error drift and ensures the final output matches the actual session.
These cycles yield measurable results for clinics:
- 90% coding accuracy compared to the 54% U.S. national average
- Documentation time reduced from 20 minutes to 7 minutes per session.
- Reliable detection of billable add-on codes that are frequently missed
These gains emerge because recursive meta-prompting generates structured evidence at each stage, allowing subsequent cycles to verify and correct as needed. Instead of relying on a single pass, multiple domain-specific reviews ensure notes are defensible and billing-ready.
Research Foundations and System Evolution
The development of self-validating AI models follows a broader movement toward systems that critique their own reasoning. Each foundational method introduces a different mechanism for self-assessment.
Self-Refine demonstrates quality gains from self-review and revision. The model generates a draft, identifies issues, and produces an improved version. This loop continues repeating as needed until further changes add no benefit.
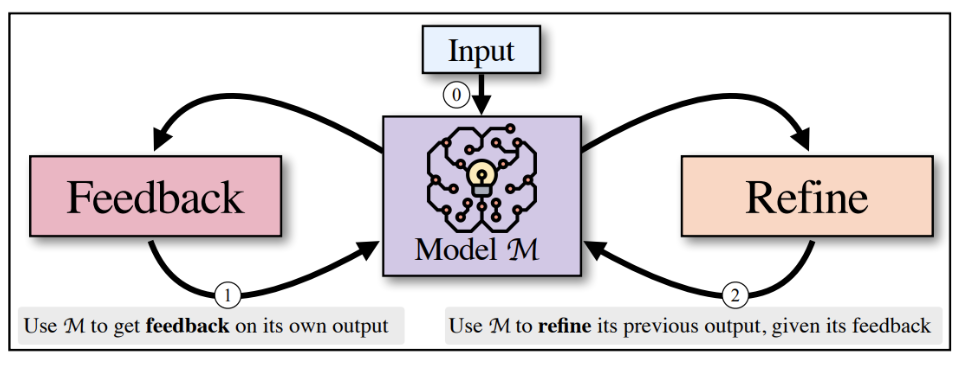
Diagram showing Self-Refine as an iterative self-refinement algorithm that alternates between two generative steps: Feedback and Refine.
Source: Self-Refine: Iterative Refinement with Self-Feedback | Madaan et al.
Reflexion adds a memory component. After completing a task, the model writes reflections on what failed and what to change, improving its decisions on sequential tasks like code generation and complex question answering.
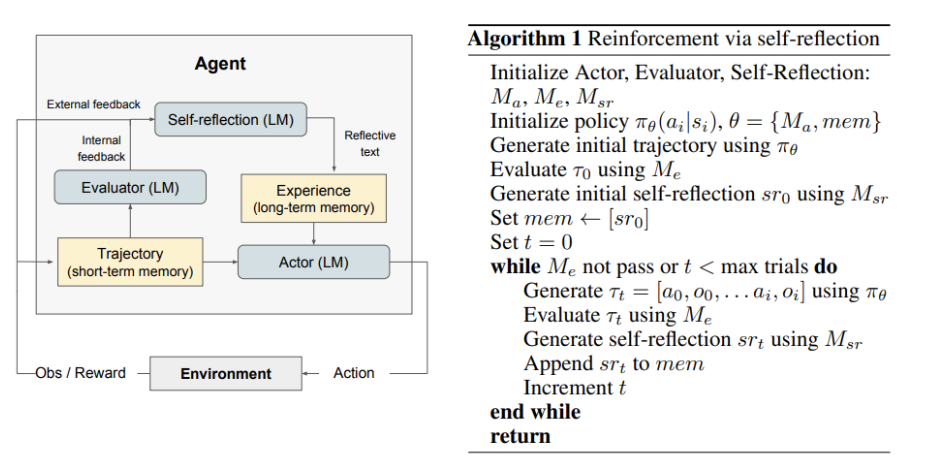
(Left) Diagram of Reflexion. (Right) Reflexion reinforcement algorithm.
Source: Reflexion: Language Agents with Verbal Reinforcement Learning | Shinn et al.
Auto-GPT-style agents go further by organizing multi-step workflows. These agents can set their own sub-goals, use tools, and progress through complex tasks independently. Combined with an “Additional Opinions” algorithm, these systems improve decision quality across multiple steps. Still, many such agents lack a way to verify that each intermediate decision remains on track.
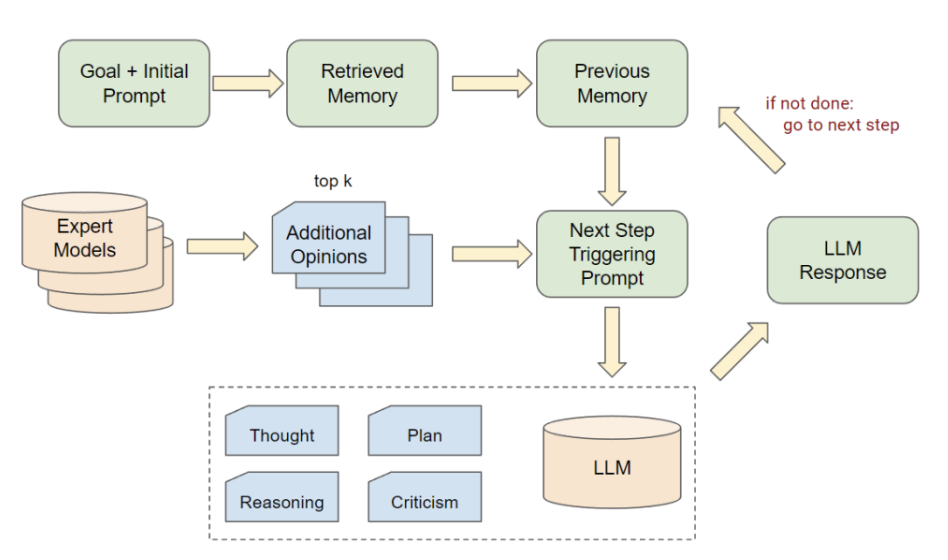
Illustration of one step of Auto-GPT with Additional Opinions.
Source: Auto-GPT for Online Decision Making: Benchmarks and Additional Opinions | Yang et al.
Without a consistent self-correction mechanism, reasoning can go off course. Recursive meta-prompting addresses this by continually refining the instructions that guide each step. Over time, this approach maintains close alignment with domain requirements.
Future Outlook
Several fields are beginning to rely on language models for tasks that demand accuracy and clear logic. Systems that can review and adjust their own reasoning will be needed across certain domains.
- Legal: Contract review and filings require accurate references and logic. Recursive checks can confirm correct language, catch citation errors, and verify summaries against jurisdictional rules.
- Financial Services: Risk and compliance briefs compress dense information. Multi-pass validation helps confirm regulatory conditions and catch details a single-pass model would miss.
- Education: Instructional agents benefit from recursive checks that reveal weak solutions or rubric errors.
When the stakes are high, models benefit from running several cycles of self-review. This approach minimizes subtle errors, produces transparent decision paths, and builds reliability without the need for external oversight or extra training.
Conclusion
As more organizations integrate AI into core workflows, the need for systems that can justify and refine their outputs becomes unavoidable. Accuracy isn’t the result of bigger models or more instructions. It comes from architectures that actively improve their own reasoning process.
Recursive meta-prompting transforms prompt design into a dynamic, self-correcting element of AI reasoning. Each validation cycle resolves inconsistencies and grounds outputs in the logic and constraints of real-world domains. At Nudge, this architecture has moved us beyond single-pass outputs toward workflows that reflect the way clinicians approach documentation.
For teams building or evaluating enterprise AI systems, it’s worth looking beyond static prompting. The next wave of reliability will come from models that question themselves before anyone else has to.




