

Qwen3-Next-80B-A3B-Instruct is Alibaba’s latest open-source Mixture-of-Experts (MoE) model, released on September 11, 2025. Despite having 80 billion total parameters, it activates only 3 billion per inference step through its highly sparse MoE architecture, delivering flagship performance at a fraction of the computational cost.
Key Technical Features:
- Hybrid Attention: Optimized for long-context processing
- High-Sparsity MoE: Ultra-low activation ratio (3.75% of parameters), 10x faster inference than dense models
- 262K Context Window: Handles up to 262,144 tokens, ideal for lengthy documents and multi-turn conversations
Best Use Cases:
- Long document analysis and summarization
- Complex multi-turn dialogues
- Code generation (LiveCodeBench score: 68.4)
- High-throughput production environments
According to Artificial Analysis benchmarks, Qwen3-Next-80B-A3B achieves MMLU Pro scores of 81.9 and GPQA scores of 73.8, with inference speeds reaching 144 tokens/second—making it an ideal choice for cost-conscious enterprise applications.
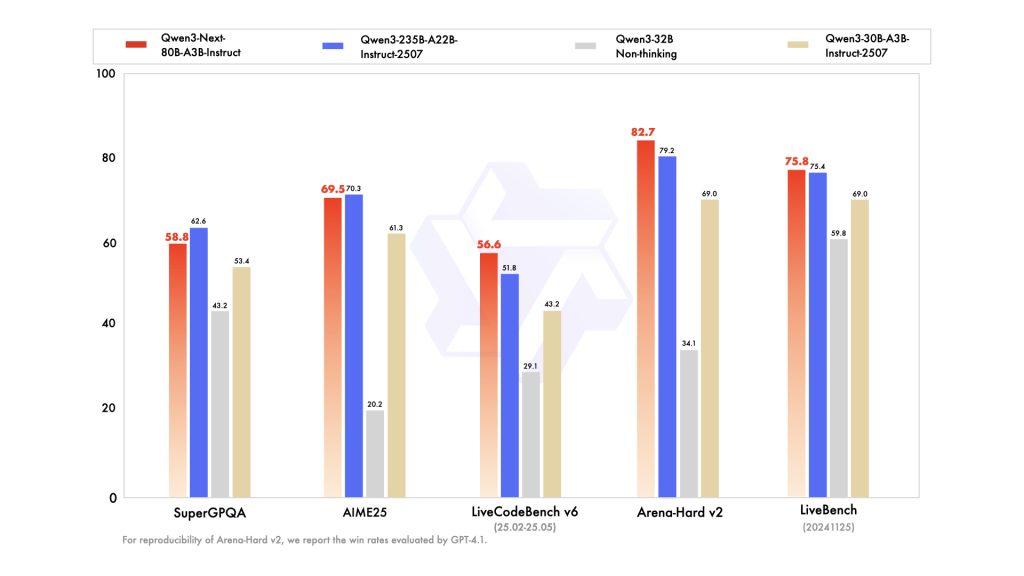
Source: Reproduced from Qwen official blog
Qwen3-Next-80B-A3B-Instruct Price Comparison
As of January 2026, 9 major platforms offer Qwen3-Next-80B-A3B-Instruct API access, with significant price variations. Here’s the complete breakdown:
Price Comparison Table (Sorted by Input Price)
| Provider | Input ($/1M tokens) | Output ($/1M tokens) | Uptime | Rate Limits | Notes |
| DeepInfra | $0.09 | $1.10 | 99.8% | No minimum | – |
| Parasail | $0.10 | $1.10 | 97.7% | TBD | – |
| Chutes | $0.10 | $0.80 | 99.5% | No minimum | – |
| Infron | $0.09 | $0.80 | 99.9% | 10K RPM | Auto-selects cheapest provider |
| SiliconFlow | $0.14 | $1.40 | – | May have limits | CN-friendly |
| Google Vertex AI | $0.15 | $1.20 | 99.7% | Enterprise SLA | Official partnership |
| AtlasCloud | $0.15 | $1.50 | 99.2% | None | – |
| GMICloud | $0.15 | $1.50 | 99.7% | None | – |
| Novita | $0.15 | $1.50 | 100% | None | – |
| Alibaba | $0.15 | $1.20 | 99.0% | Official pricing | Native support |
Price Difference Analysis
- Input Cost Variance: Most expensive ($0.15) vs. cheapest ($0.09) = 67% difference
- Output Cost Variance: Most expensive ($1.50) vs. cheapest ($0.80) = 88% difference
- Blended Cost (assuming 1:3 input:output ratio):
- DeepInfra: $0.09 + $3.30 = $3.39/M tokens
- Chutes: $0.10 + $2.40 = $2.50/M tokens ⬅️ Lowest blended cost!
- Alibaba: $0.15 + $3.60 = $3.75/M tokens
Key Finding: For output-heavy workloads (content generation, code completion), Chutes’ low output pricing makes it the most cost-effective choice overall.
Stability Comparison Factors
Beyond pricing, these factors impact your real-world costs:
- Uptime: Novita (100%) vs. Parasail (97.7%) = ~16 hours vs. 4 hours monthly downtime
- Rate Limits: Official channels (Google Vertex AI, Alibaba) typically offer higher RPM quotas
- Response Speed: Median TTFT of 1.23s, but provider variations can reach ±30%
- Geographic Latency: CN users may see lower latency with SiliconFlow
The “Real Cost” Behind the Price
Many developers focus solely on per-token pricing, missing the hidden Total Cost of Ownership (TCO). In production environments, these factors can make a “cheap” solution expensive:
1. Retry Costs from Downtime
If a provider has 97.7% uptime (like Parasail):
- About 16 hours monthly downtime
- At 100 QPS with 3 retries per failure, monthly wasted cost:
- 16h × 3600s × 100 QPS × 3 retries × $0.10 = $1,728 extra spend
By comparison, choosing 99.8% uptime (DeepInfra) reduces downtime to 1.4 hours, cutting retry costs by 91%.
2. Engineering Overhead of Multi-Provider Management
Managing multiple providers manually requires:
- API Adaptation: Different JSON schemas, error codes, rate limit policies = 2-5 dev days
- Monitoring & Alerts: Each provider needs separate logging, monitoring, alerting infrastructure
- Billing Reconciliation: 3 providers = 3 billing systems = 2-4 hours monthly accounting
Engineering Cost: Assuming $100/hour senior engineer rate, 10 hours monthly maintenance across 3 providers = $1,000/month in labor.
3. Rate Limiting Performance Degradation
Budget providers often control costs through strict rate limits:
- RPM Constraints: When traffic spikes (product launch, viral moment), requests queue
- Queue Latency: User wait time increases from 1s → 5s = 80% user drop-off (per Google research)
4. Opportunity Cost of Failed Failover
Without automatic failover when your primary provider fails:
- Business Interruption: Hourly loss = traffic × conversion rate × AOV
- Example: 1,000 users/hour × 3% conversion × $50 AOV = $1,500/hour lost revenue
Bottom Line: For production workloads, a stable unified router saves far more in hidden costs than you’d save from a few cents per token.
How to Get the Cheapest Qwen3-Next-80B-A3B-Instruct in Practice?
Depending on your use case, here are three recommended approaches:
Option 1: Single Provider (Best for Testing/Small Scale)
Ideal for:
- Daily usage < 1M tokens
- Non-critical applications that can tolerate occasional downtime
- Development/testing environments
Recommended Providers:
- Maximum Savings: Chutes ($2.50/M blended cost)
- Balanced Choice: DeepInfra ($3.39/M + 99.8% uptime)
- CN Users: SiliconFlow (lower network latency)
Risks:
- ❌ No failover = provider downtime = service interruption
- ❌ Easy to hit rate limit bottlenecks
- ❌ Limited negotiating leverage with single vendor
Option 2: Manual Multi-Provider Switching (For Tech Teams)
Ideal for:
- Dedicated DevOps team available
- Extreme cost sensitivity
- Willingness to invest engineering resources
Cost Analysis:
- ✅ Dynamic switching based on real-time pricing
- ✅ Active selection of optimal providers
- ❌ Initial development: 10-20 dev days ($15,000-$30,000)
- ❌ Monthly maintenance: 10 hours ($1,000)
Option 3: Unified Router (Recommended for Production)
Ideal for:
- Production environments requiring 99.9%+ availability
- Daily usage > 5M tokens
- Need rapid scaling without operations burden
Why Choose Infron?
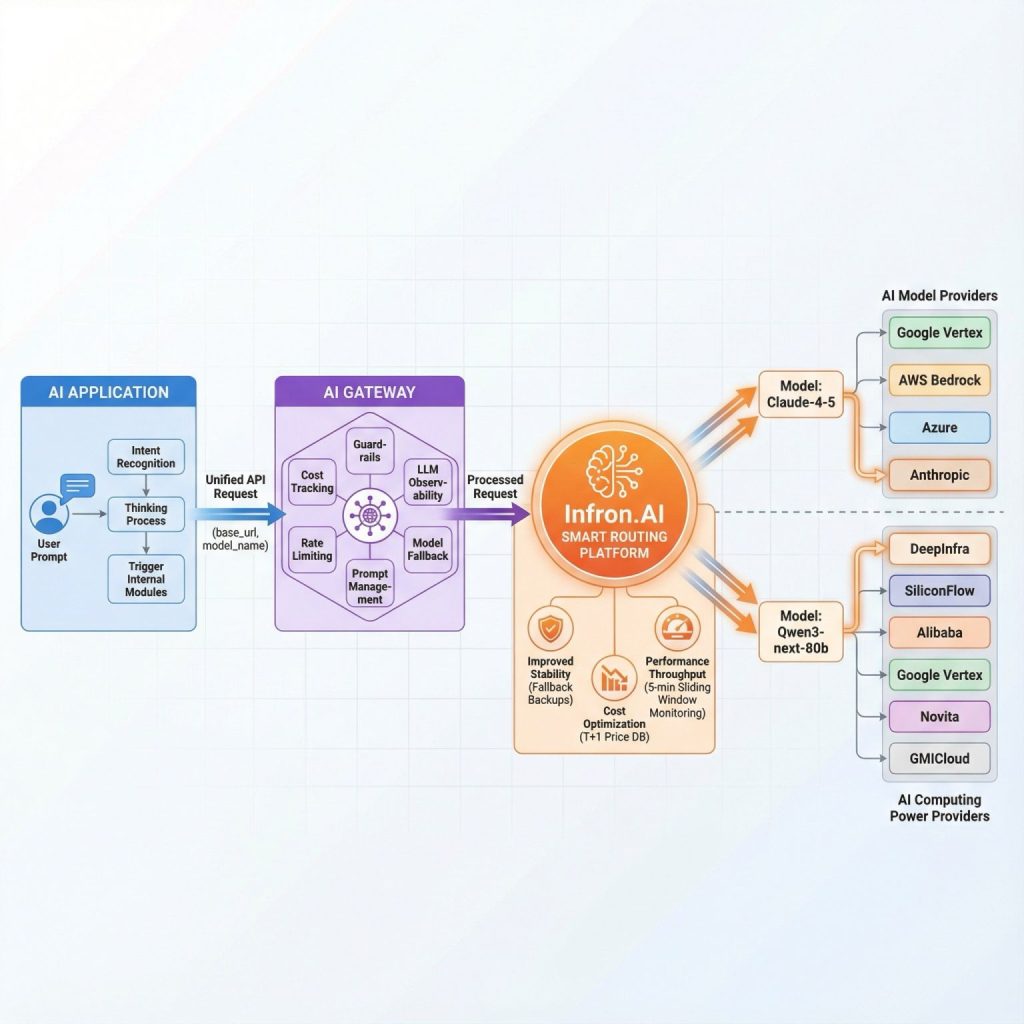
Infron provides an enterprise-grade AI Model Router that solves all multi-provider pain points:
| Feature | Self-Built Solution | Infron AI Solution |
| Integration Cost | 10-20 dev days | 10 minutes (OpenAI SDK compatible) |
| Vendor Management | 30+ separate contracts | 1 unified contract + billing |
| Auto Failover | Build retry logic yourself | Built-in smart routing across 60+ providers |
| Rate Limit Handling | Queue when limits hit | 10K RPM premium channel, no approval wait |
| Cost Optimization | Manual price monitoring | Auto-selects cheapest provider, save up to 35% |
| Monitoring & Alerts | Configure multiple systems | Unified dashboard + real-time alerts |
| SLA Guarantee | None | 99.9% uptime SLA + compensation |
Cost Comparison (100M monthly tokens scenario):
Self-Built Approach:
– Token cost: $250 (cheapest platform)
– Engineering maintenance: $1,000/month
– Retry/failure cost: $500/month
– Total: $1,750/month
Infron AI Approach:
– Token cost: $245 (auto-selects optimal provider)
– Platform fee: $0 (usage-based, no fixed fees)
– Total: $245/month
Savings: $1,505/month (86%)
Infron Core Advantages:
- True Price Transparency: Real-time pricing across 300+ models, auto-routes to cheapest provider
- Zero-Downtime Guarantee: When DeepInfra fails, automatically switches to Chutes—users never notice
- Elastic Scaling: No quota applications needed, use Infron AI’s enterprise channels (10K RPM)
- Unified Billing: Single invoice covers all providers, supports corporate wire transfer
- Enterprise Support: Priority engineering support + Data Protection Agreement
One-Line Migration:
from openai import OpenAI
client = OpenAI(
base_url=”https://llm.onerouter.pro/v1″,
api_key=”<API_KEY>”,
)
completion = client.chat.completions.create(
model=”qwen/qwen3-next-80b-a3b-instruct”,
messages=[
{
“role”: “user”,
“content”: “What is the meaning of life?”
}
]
)
print(completion.choices[0].message.content)
Conclusion
If you’re just testing or building personal projects: Go with Chutes (lowest blended cost at $2.50/M) or DeepInfra (lowest input price + high reliability).
If you’re running production workloads, need scale, and want savings + stability: Use Infron.
Infron eliminates the headache of managing 30+ providers, with automatic failover + automatic best-price selection + 99.9% SLA guarantee. No more dealing with downtime, rate limits, or billing reconciliation—let your team focus on building product.



