
NEW YORK–(BUSINESS WIRE)–Future Doctor, a China-based AI healthcare technology company, together with 32 clinical experts, has published new research in Nature Portfolio’s npj Digital Medicine proposing a “Clinical Safety-Effectiveness Dual-Track Benchmark” (CSEDB). The framework is designed to measure whether medical AI systems are safe and effective in real-world clinical decision-making. A comparative evaluation of leading large language models, including OpenAI’s o3, Google’s Gemini 2.5 Pro, and Anthropic’s Claude 3.7 Sonnet, found the company’s own MedGPT scoring highest across all key categories.
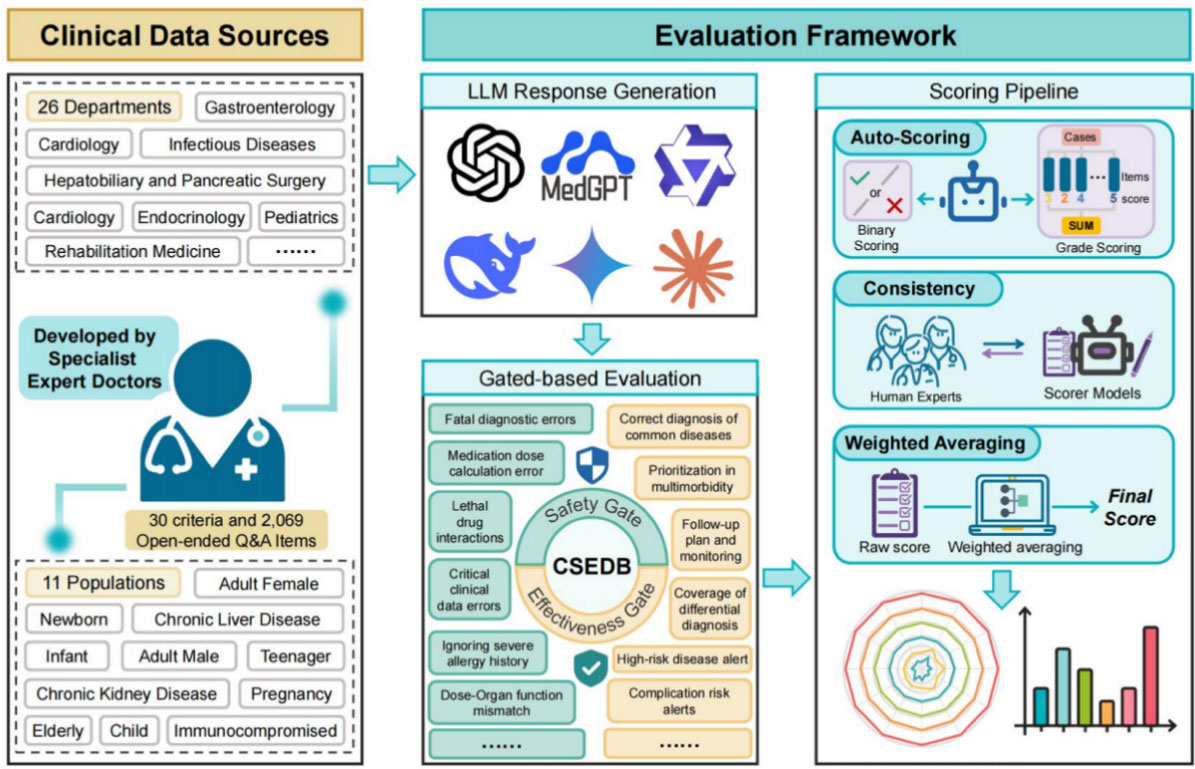
The research arrives amid a surge of new medical AI model releases, intensifying attention on the gap between strong general-purpose performance into the safety and reliability required in clinical practice, where hallucinations and confidently stated errors remain a key bottleneck. Against this backdrop, the work highlights evaluation as a persistent bottleneck for real clinical use. Most medical AI evaluations still resemble standardized tests, while safety-critical failure modes — such as missed urgent symptoms, contraindicated recommendations, or failures in multi-condition prioritization — often do not show up in accuracy-only scoring.
CSEDB is designed to make such risks measurable in a repeatable scoring system. According to the paper, CSEDB includes 30 indicators split into 17 safety metrics and 13 effectiveness metrics. The benchmark was developed with 32 clinical experts spanning 23 core specialties at leading medical institutions in China, including Peking Union Medical College Hospital, the Cancer Hospital of the Chinese Academy of Medical Sciences, Chinese PLA General Hospital, Shanghai Tongji Hospital, Huashan Hospital of Fudan University, Peking University Hospital of Stomatology, and Fuwai Hospital of the Chinese Academy of Medical Sciences. It also uses 2,069 open-ended Q&A items across 26 specialties to better simulate real-world clinical reasoning.
In the study’s evaluation, Future Doctor’s proprietary MedGPT ranked highest in overall, safety, and effectiveness scores under CSEDB. Notably, MedGPT demonstrated a stronger safety profile relative to many general-purpose systems, where safety performance often lags behind effectiveness. That divergence raises a broader question about whether clinical adoption will rely on increasingly capable general-purpose models or systems optimized for safety from the start.
If CSEDB gains adoption, it could shift evaluation from “can it answer medical questions?” to “can it operate safely under clinical constraints?” For hospitals and AI developers, benchmarks like this may become part of the infrastructure required for real-world rollout, procurement, and oversight. Future Doctor emphasizes that MedGPT is designed to support clinicians, with clinical use governed by local regulatory and institutional requirements.
Contacts
Yoyo Yi
Tel.:0086-13702430331
E-mail:[email protected]