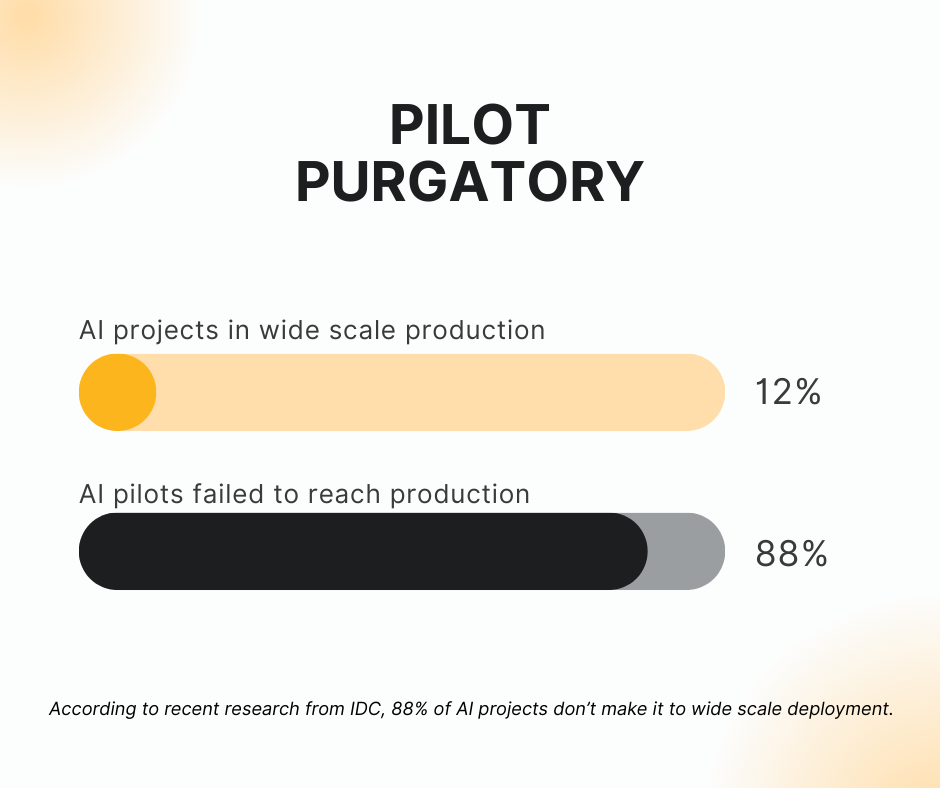
I like to say that in building AI, there are astronomers and there are astronauts. You either theorize about how an AI project can succeed in production through your telescope, or you actually walk on the moon and productionize these projects. Recently, reports are correctly drawing attention to pilot purgatory – the fact that almost all AI projects fail to reach production. IDC says 88% of AI projects stall in the pilot phase. MIT says it’s 95%. In any case, something is crushing our rosiest hopes for AI (or more accurately, some things).
My team has spent over a decade productionizing AI and ML systems for the Fortune 500 and scrappy startups, and we’ve seen the same pitfalls time and again. I’ve charted five common (and fixable) reasons why a promising AI prototype gets stuck in pilot purgatory.
A Quick Intro to Orchestration
Before we jump into these traps, a quick introduction to an increasingly essential term in building AI: orchestration. It’s defined (or ill-defined) differently across the industry right now, so here’s a clear standard. Orchestration is the command center of AI systems, the layer that coordinates data, models, and compute so workflows run reliably and at scale. Oftentimes, the success of an AI system comes down to how a team orchestrates it.
Now, let’s get into the traps that kill AI systems in the cradle.
- Reliability: Scaling Becomes Failing
In the pilot phase, workflows are small, environments are simple, and stakes are low. But scaling to production changes everything. Under the weight of real users, changing data, and millions of tasks (i.e., actions AI workflows take), AI systems become tremendously brittle and unreliable.
My team works with a Fortune 500 automotive company building autonomous driving technology. Their pipelines spanned everything from perception labeling to GPU-intensive model training and needed to handle petabytes of data. That is a HUGE amount of data. Manually maintaining the health of workflows risked banishing them to pilot purgatory.
The reality is that most AI systems don’t scale linearly; they scale exponentially. If you don’t orchestrate them reliably, you’re asking them to fail, meaning you can’t rely on manual intervention to fix broken workflows.
Instead, you need automatic maintenance and failure recovery built into your AI systems. When a workflow breaks because not enough compute is provisioned, it should retry with more compute. When an agent runs, it should be able to dynamically make decisions at runtime instead of waiting for a DevOps intervention.
The automotive company recognized this trap as they scaled and successfully productionized one of the most impressive AI systems I’ve ever seen.
- Costs Spiral Out of Control
Costs are notoriously unpredictable and underestimated. Most companies lack real-time compute usage transparency and get left with a runaway bill like a snooty waiter dropping off the check at the end of a bad date.
For a fintech client, cost inefficiencies surfaced quickly once orchestration demands grew. Their homegrown pipeline setup didn’t allow them to allocate resources by task, so they had to provision large, cost-intensive clusters—even for workflows that didn’t need all that capacity. Model execution times lagged, and compute costs continued to rise.
This isn’t unusual. For pilots, cost is an afterthought. A team spins up some GPUs, runs some tests, and chalks it up to R&D. But in production, those costs multiply quickly.
Without compute-aware orchestration, AI systems often:
- Overprovision resources “just in case”
- Leave expensive nodes idle due to poor autoscaling
- Recompute identical tasks due to a lack of caching
- Retry failed tasks without debugging root causes
The result? Bills that exceed budget and make leadership question the entire initiative. Sustainable AI requires managing orchestration, computation, and cost as a single system.
- Your Tools Don’t Play Nicely Together
Like a house of cards, an AI system built on a tech stack of hacked-together point solutions and DIY patches is destined to collapse. In a proof of concept, it’s fine to glue together a few scripts and tools with some Python and YAML. But once multiple teams, services, and environments get involved, that glue becomes a liability.
We worked with a London-based autonomous driving company that orchestrates thousands of workflows across neural simulators, Spark pipelines, Python models, and raw container tasks. Their AI systems touch every step of the self-driving lifecycle, from labeling to embedding generation to inference, and each step brings its own dependencies and compute needs.
To run these diverse workflows at scale, they needed an orchestration layer that could cleanly isolate environments, define per-task resources, and support modular reuse across teams. Without that flexibility, scaling experimentation and collaboration would have been much more challenging.
Orchestration has to do more than schedule jobs. It must:
- Pass data seamlessly between tasks and tools
- Version workflows and artifacts
- Support heterogeneous compute and environments
- Connect to the APIs, models, and platforms your team already uses
By unifying their AI development layer through orchestration, this company deployed a foundation for sustainable, production-ready AI.
- Your Sandbox Isn’t The Real World
A pilot might run beautifully on a developer’s laptop or a single cloud instance. But production deployments span environments: local, staging, dev, prod, even multi-cloud.
If moving between those environments requires manual reconfiguration, editing YAML, or swapping containers, the deployment and debugging costs outweigh the benefits.
Production-grade AI systems need orchestration that travels with the code. That means reproducibility, portability, and type safety by default.
A synthetic biology startup was developing ML-powered protein design tools. Their workflows initially ran fine, but did not scale well, limiting their ability to implement AI development best practices, such as reproducibility, isolation of dependencies and resources across tasks, caching, and data provenance. Being able to look back and see exactly which workflow produced which output was a requirement. They needed a system that could support these best practices not just locally, but across public cloud, private cloud, and on-premise environments.
Without environment-flexible orchestration, they would have been slowed down considerably.
- Compliance Defiance
In production, compliance is a dealbreaker. Whether you’re meeting regulatory requirements, satisfying auditors, or maintaining credibility with stakeholders, you need to prove that your AI system maintains a certain standard of trust.
One global company learned this the hard way when coordinating quarterly forecasts across eight teams and more than 15 models. Manual handoffs and opaque workflows made it nearly impossible to trace results with confidence. Forecasts dragged on for weeks, and leadership lacked clear visibility into how data flowed or which model versions were used.
This is the difference reproducibility makes. In a pilot, you might survive by piecing together Slack messages and GitHub commits. In production, reproducibility and lineage must be automatic and auditable.
Without these controls, AI becomes a mystery box. You can’t validate results, debug failures, or demonstrate compliance. And in today’s regulatory environment, that’s a showstopper.
The Way Out: AI-Native Orchestration
The traps that keep AI projects stuck in pilot purgatory aren’t inevitable. Reliability, cost control, compliance, and complexity all point back to the same root cause: weak foundations. The way out is AI-native orchestration.
Done right, orchestration turns brittle prototypes into production-ready systems. It makes workflows resilient to messy, real-world data while keeping budgets in check. It makes compliance easy and unifies the fragmented AI development tech stack. In short, it provides the modern infrastructure that AI actually needs to be reliable in production.
Some companies have already made the leap, and they’re the ones getting real value out of AI today. For everyone else, the race is on to buy or build production-quality orchestration. That’s how you walk on the moon.