Data engineers deal with immense datasets, and traditional ways of handling them (ETL) are sometimes inefficient. Working with data by hand and applying strict procedures means losing time and failing to obtain up-to-date information quickly, creating a negative effect in decision-making, potential and efficiency. This leads to poor quality of data, slow problem solving and overall inability to identify problems or to predict change.
There is a beautiful solution to this in Machine learning (ML). Supervised and unsupervised learning are techniques that can be incorporated into data engineering to automate a process, identify search patterns and make consequent predictions since it is an added advantage to business. In this post, let me briefly walk you through into how the field of Data Engineering is evolving with the help of machine learning techniques. We will define some obvious and not so obvious terms, provide working examples and go over the details of applying and selecting the right approach of including ML in your processes. This leaves many to anticipate a new era of data engineering popularly known as smart technology.
Use Cases
Machine learning isn’t just an idea for data engineers; it’s a useful tool that can improve every part of your process. Here are some of the most important ways it can be used:
Anomaly Detection
The Challenge. Finding data anomalies by hand is slow and prone to mistakes.
The ML Solution. Unsupervised machine learning algorithms, like clustering and isolation forests, can automatically spot unusual patterns, helping to detect errors, fraud, or unexpected system behavior.
Data Cleaning & Imputation
The Challenge. Missing or inconsistent data can mess up analysis and lead to wrong conclusions.
The ML Solution. Machine learning models can understand your data’s structure, allowing them to smartly fill in missing information, fix inconsistencies, and standardize values.

Data cleaning, imputation, and validation workflow diagram
Feature Engineering
The Challenge. Raw data often doesn’t show its full potential for analysis and prediction.
The ML Solution. Machine learning algorithms can automatically extract important features from raw data, like trends, correlations, and interactions, providing richer inputs for further analysis.
Predictive Quality Control
The Challenge. Traditional quality control often involves fixing problems after they’ve caused damage.
The ML Solution. Machine learning (ML) models analyze past data to predict possible quality issues, allowing you to take action and prevent problems before they happen.
Real-time Decision Making
The Challenge. Old school data processing cannot easily respond to request as they take a lot of time in processing the data.

The ML Solution. One more advantage is the ability to make decisions right from the stream of real-time data together with ML models. This is good for such things as fraud detection, recommended offers/products to clients, and price differentiation.
Industry-Specific Examples
- Finance: Fraud, algorithmic trading and risk assessment.
- Retail: Forecasting demand, individualized recommendations, and demand Fulfilment.
- Healthcare: In diagnosing patients and forecasting health outcomes as well as aiding in the evaluation of the risk that patients are likely to pose to the healthcare system as well as selecting the best treatment options to apply in patient management.
- Manufacturing: Forecasting of maintenance requirements, quality control and the improvement of other processes.
The ML in these areas adds substantial value to efficiency, accuracy, and decision-making to your data processes.
Using ML in these areas can greatly improve efficiency, accuracy, and decision-making in your data processes.
Making ML Work for Your Data Pipelines
Let’s dive into the details of how machine learning works with your data engineering processes. We’ll keep it practical and straightforward:
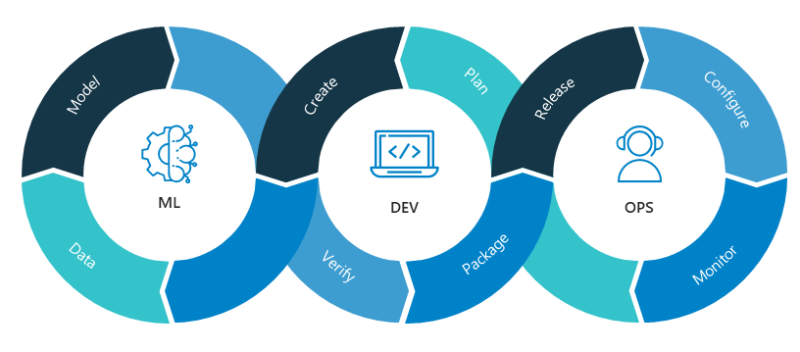
The ML Pipeline in Data Engineering
Think of an ML pipeline as an intelligent upgrade to your existing data processes. It’s a seamless addition that boosts your capabilities. Here are the key stages:
- Data Ingestion and Preparation. This is where your data engineering skills are crucial. ML models need clean, reliable data. Ensure you have strong data ingestion methods, cleaning routines, and feature engineering in place.
- Model Training. Choose the right ML algorithm and train it using your prepared data. This involves adjusting the parameters to make your model accurate and reliable.
- Model Evaluation. Always test your model thoroughly! Use techniques like cross-validation to ensure your model performs well on new data.
- Model Deployment. Integrate your trained model into your data pipeline, using APIs, microservices, or other methods.
- Model Monitoring and Maintenance. Monitor their performance, detect any issues, and retrain them as needed to keep them accurate.

Choosing the Right ML Algorithms
The algorithm you choose depends on your specific use case and the nature of your data. Here’s a quick overview:
- Supervised Learning. Best for tasks like prediction and classification where you have labeled data. Examples include linear regression, decision trees, and neural networks.
- Unsupervised Learning. Great for finding hidden patterns or grouping data into meaningful clusters. Examples include k-means clustering and anomaly detection algorithms.
- Reinforcement Learning. Used for sequential decision-making problems where an agent learns through trial and error. Less common in data engineering pipelines but useful in dynamic environments.
Training Models with Data Engineering Best Practices
- Data Splitting. Divide your data into training, validation, and test sets to avoid overfitting and ensure your model works well on new data.
- Feature Scaling. Standardize or normalize features to prevent some from dominating others during training.
- Hyperparameter Tuning. Find the best settings for your ML algorithm to get the best performance.
- Regularization. Use techniques like L1 or L2 regularization to help prevent overfitting.
- Integrating ML Models into Existing Pipelines
- APIs. Create RESTful APIs to allow other applications or components to use your ML model.
- Microservices. Build lightweight, independent services that contain specific ML models, making your architecture more scalable and easier to maintain.
Monitoring and Maintaining ML Models in Production
- Concept Drift. The world changes, and so do patterns in your data. Keep an eye on your model’s performance and retrain it when needed.
- Logging and Alerts. Set up systems to monitor your model’s predictions and alert you if performance drops.
By understanding these technical points, you can implement machine learning solutions that improve your data engineering processes.
Challenges and Considerations
Integrating machine learning into your data engineering has its challenges. Let’s address these to prepare for a successful ML journey:
Data Availability and Quality
The saying “garbage in, garbage out” is especially true for machine learning. Your models are only as good as the data you use to train them.
The Challenge. Ensuring you have enough high-quality, representative data can be difficult. Incomplete, inconsistent, or biased data can lead to inaccurate models and misleading results.
The Solution. Focus on collecting and cleaning your data thoroughly. Invest in strong data governance frameworks. Consider using techniques like data augmentation or creating synthetic data if you face limitations.
Scalability and Performance
The Challenge. As your data increases and ML models get more complex, you need systems that can handle the load. Picking the wrong tools can cause slowdowns and other issues.
The Solution. Look into cloud solutions for flexible computing power. Use tools like Apache Spark for processing large amounts of data. Make sure your ML algorithms are efficient.
Skills Gap
The Challenge. Machine learning requires not just algorithms but also a strong grasp of statistics and domain knowledge. Finding engineers with these skills can be hard.
The Solution. Invest in training and upskilling your existing team. Partner with data science experts or consultants. Look for talent with a passion for both data engineering and machine learning. To bridge this skills gap, consider leveraging data engineering services that offer specialized expertise in ML implementation and MLOps.
Ethical Implications
The Challenge. ML models can reflect or even worsen biases in the data they learn from, leading to unfair outcomes.
The Solution. Work on removing bias in data collection and processing. Use algorithms that are less prone to bias. Regularly check your models for fairness and make changes as needed.
By tackling these issues head-on, you can make sure your ML projects are effective, ethical, and dependable.

Your Roadmap to ML-Powered Data Engineering
Want to use machine learning in your data workflows? Here’s how to start:
Identify Your Pain Points
Begin by identifying where ML can help most in your current process. Are there issues with data quality, manual feature engineering, or the need for real-time predictions?
Start Small and Iterate
Don’t start with a complex ML model. Begin with a simple use case, like detecting anomalies or cleaning data, and expand as you gain experience.
Build Your ML Toolkit
Get to know popular ML libraries and frameworks like Scikit-learn, TensorFlow, or PyTorch. Try different algorithms to see what works best for you.
Focus on Data Quality
Collect high-quality, relevant data. Make sure it’s well-labeled, clean, and formatted for ML training. If you lack data, consider using synthetic data generation.
Collaborate with Data Scientists
If you’re new to ML, working with data scientists can be very helpful. They can assist with choosing the right algorithms, fine-tuning models, and navigating ML complexities.
Monitor and Maintain
ML models need regular attention. Monitor their performance, track changes in data, and retrain them as needed to keep them accurate and relevant.
Explore AutoML Platforms
If you’re short on time or ML expertise, consider AutoML platforms. They can automate tasks like model selection, hyperparameter tuning, and feature engineering.
Embrace MLOps
When deploying ML models, use good MLOps practices. This includes versioning models, tracking experiments, and automating deployment pipelines to ensure reproducibility and scalability.
Stay Curious and Keep Learning
ML is always evolving. Keep up with the latest research, tools, and techniques by attending conferences, reading blogs, and joining online communities.
Bonus Tip
Start with a small proof-of-concept project to show the value of ML to your stakeholders. This can help you get support and resources for larger projects.
Remember, integrating ML into your data workflows is a journey. It takes time, effort, and a willingness to learn. But the benefits in efficiency, accuracy, and insights make it worth the investment.
Conclusion
Machine learning is changing data engineering by making data cleaner, work more efficient, insights deeper, and decisions more proactive. This is not just a trend; it’s the future. Don’t be scared – start small and try new things. The tools and resources are available.
The future of data engineering is smart and driven by data. Use machine learning to get the most out of your data and stay ahead.
What do you think about the mix of machine learning and data engineering? Share your experiences and thoughts in the comments below!