I have spent more than 15 years building data platforms for large enterprises across finance, healthcare, energy, manufacturing, telecom, and other industries. In consulting, the challenge is rarely just to design a good architecture on paper. The real challenge is to make that architecture work inside complex organizations: with legacy systems, fragmented ownership, regulatory requirements, cost pressure, and business teams that need outcomes quickly. The best data platforms I have worked on were not successful because they used the newest tools. They worked because the engineering decisions were tied to clear business use cases, the architecture was designed for scale from the beginning, and governance was built into the system rather than added later.
This is the playbook I use when building enterprise data platforms that need to move from MVP to production.
Start with the Use Case, Not the Platform
The most common mistake I see is starting with the platform itself: “We need a data lake,” “We need Snowflake,” “We need Databricks,” “We need a modern data stack.” Those may be the right tools, but they are not the starting point.
The starting point should be the business decision someone needs to make.
A better first question is: who needs to make which decision, by when, and with what level of confidence? For example, the CFO may need margin visibility across three geographies by Thursday. A field operations team may need real-time monitoring to dispatch crews faster. A compliance team may need traceable data lineage for regulatory reporting. A manufacturing team may need predictive maintenance to reduce downtime.
Once that decision is clear, architecture choices become much sharper. You can define latency requirements, source systems, data quality rules, semantic definitions, access patterns, and the level of governance required. Without that anchor, teams often build infrastructure that is technically impressive but disconnected from operational value.
In my work, I have seen this difference clearly. When a platform is built around a real business use case (compliance automation, customer insight, predictive operations, clinical analytics, trading analytics) it is much easier to align engineering, product, and business stakeholders. The platform becomes a delivery mechanism for value, not just an infrastructure project.
As a consultant with a data engineering background, I always try to connect the technical architecture to measurable outcomes. If the platform cannot explain how it improves a decision, reduces cost, accelerates delivery, or lowers risk, it is not yet properly designed.
Design for Integration, Not Ingestion
Enterprises usually do not struggle because they lack data. They struggle because their data is fragmented, inconsistent, and difficult to use across systems.
A typical large organization has transactional systems, legacy databases, cloud applications, IoT data, spreadsheets, third-party feeds, and sometimes mainframe or AS400 systems still running critical business processes. Ingesting all of that data into a central place is only the first step. It does not create a usable platform by itself.
The real engineering challenge is integration.
Integration means creating a consistent operational layer across fragmented sources. It means defining common entities, aligning business definitions, resolving duplicate or conflicting records, and building transformation logic that can be trusted. It also means designing for interoperability, so data from one domain can be used by another without every new use case starting from zero.
For example, in energy and utilities, operational data may come from SCADA systems, asset systems, smart meters, and enterprise planning tools. In healthcare, patient and provider data may be distributed across different platforms with strict privacy and compliance requirements. In financial services, regulatory reporting and trading analytics may depend on data that originally sits in separate systems with different controls and definitions.
In those environments, the platform cannot simply collect data. It has to make data usable.
This is where deep data engineering matters. You need to understand ingestion patterns, transformation layers, schema evolution, orchestration, lineage, access control, and performance. But you also need to understand the business meaning of the data. “Revenue,” “customer,” “asset,” “provider,” or “product” may not mean the same thing across systems.
A scalable platform creates a governed layer where these definitions are made explicit and reusable. That is what allows new use cases to be built faster, because teams are not repeatedly solving the same integration problems.
Build Governance Into the Architecture, Not the Roadmap
Governance is often treated as something that comes later. Teams build the platform, deliver the MVP, and plan to “add governance” when the system scales.
That approach usually fails.
In enterprise systems, especially in regulated industries, governance is not a separate workstream. It is part of the architecture. If lineage, access control, data quality, privacy, and auditability are not designed into the platform from the beginning, they become blockers later.
This is especially important in healthcare and finance, where data may be sensitive, regulated, or subject to audit. A model or dashboard may look useful, but if the organization cannot explain where the data came from, who accessed it, how it was transformed, and whether it meets compliance requirements, the solution will not scale.
In practice, this means building governance into every layer of the platform. Access control should not depend on manual approvals alone. Lineage should be captured by the system. Data quality checks should run before data reaches downstream consumers. Sensitive data should be classified and protected. Ownership should be clear at the domain level.
I have worked on platforms where governance frameworks were central to making the architecture production-ready. That includes tools and patterns around RBAC, Purview, Unity Catalog, data quality controls, de-identification layers, and domain ownership models. The specific tools vary by client and cloud environment, but the principle is the same: governance must be operational, not theoretical.
This also affects trust. Business users will not adopt a platform simply because the data is available. They adopt it when they trust that the data is accurate, current, secure, and explainable. Governance is what turns data availability into data trust.
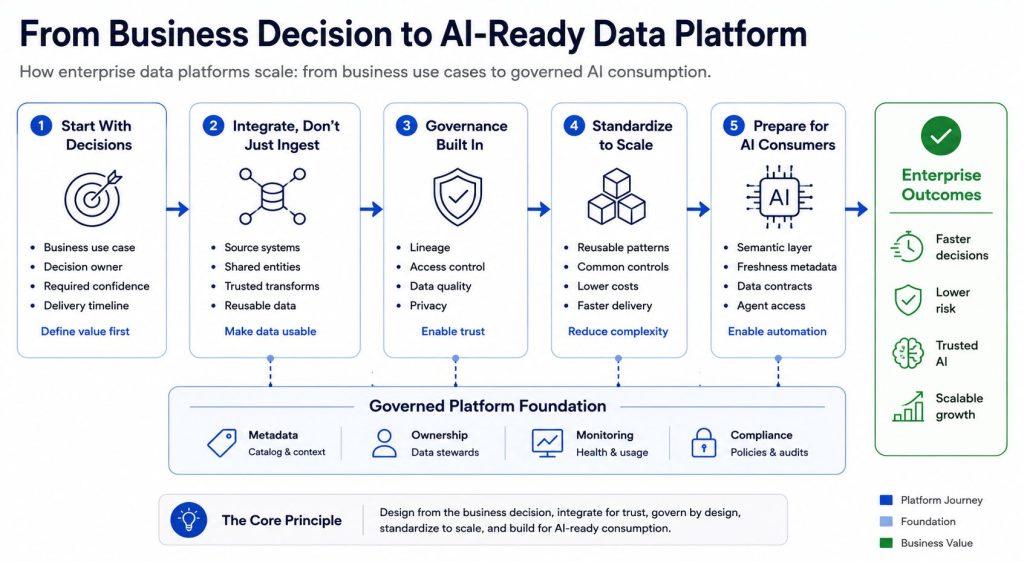
Standardize Early to Scale Fast (and Cut Costs)
Custom engineering can be useful in the early stages, but custom builds do not scale well across enterprise environments. Every custom pipeline, custom integration pattern, and custom deployment process adds long-term cost.
If every client team or business unit builds its own version of the platform, the organization ends up with duplicated effort, inconsistent definitions, and expensive maintenance. The solution is not to remove flexibility. The solution is to standardize the parts that should be repeatable.
In my work on platform-based approaches, including the Digital Data Platform framework at BCG, standardization has been one of the biggest drivers of speed and cost reduction. Reusable components, reference architectures, accelerators, and common governance patterns can reduce setup time significantly. They also make delivery more predictable.
The goal is to avoid rebuilding the foundation for every use case. Standard ingestion patterns, transformation layers, semantic models, access controls, monitoring, and deployment practices allow teams to move faster while staying aligned with enterprise standards.
This is where FinOps also becomes important. Data platforms can become expensive very quickly if teams over-provision compute, duplicate storage, or fail to monitor usage patterns. Cost control has to be part of the engineering model, not a finance conversation after the fact.
In a recent engagement I have seen standardization reduce platform delivery costs by nearly 50% and shorten setup time from months to weeks. But the value is not only cost reduction. Standardization also improves reliability. When teams reuse tested patterns, they make fewer mistakes. When architecture is modular, cloud-agnostic, and well-governed, it is easier to scale from MVP to enterprise adoption.
A good enterprise platform should give teams a fast path to delivery without forcing every use case into a rigid template. The art is knowing what to standardize and where to allow domain-specific flexibility.
Your Platform Will Be Queried by Agents — Design for That Now
The next generation of enterprise data platforms will not only serve dashboards, analysts, and applications. They will increasingly serve AI agents, LLM-based tools, and automated decision workflows.
That changes the design requirements.
When a human analyst queries a dataset, they can sometimes notice when something looks wrong. When an AI agent queries a dataset, interprets the result, and triggers another action, the platform needs stronger guardrails. The system has to make data meaning, freshness, quality, and access rights explicit.
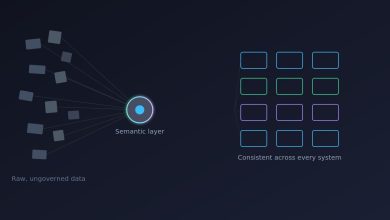
This is why semantic layers are becoming trust infrastructure. It is not enough to expose raw tables. AI systems need structured, governed, and contextualized data. They need to know what a field means, how fresh the data is, who owns it, whether it can be used for a given purpose, and what quality checks have been applied.
Freshness metadata is especially important. I have seen operational models make poor recommendations because sensor data looked valid structurally but had not updated for days. From the model’s perspective, the data was present. From the business perspective, it was wrong. Future platforms must make freshness and reliability visible to both applications and AI systems.
Data contracts will also become more important. If data producers change schemas, definitions, or quality standards without notifying consumers, downstream systems break. In an AI-enabled enterprise, this risk becomes larger because more systems will depend on data automatically. Contracts between producers and consumers should define schema, semantics, SLAs, quality rules, and ownership.
I have been working with ideas such as agentic data contracts, where AI agents can help negotiate, monitor, and enforce data quality agreements between producers and consumers. The principle is simple: governance has to move closer to the system itself. Manual committees and periodic audits will not be enough when AI systems operate at machine speed.
This does not mean every company needs to rebuild its platform immediately. But companies designing data platforms today should assume that agents will become future consumers of enterprise data. That means investing now in semantic consistency, access control, lineage, freshness metadata, and automated quality checks.
AI does not sit on top of the data platform. It depends on how the platform is designed.
Most of the AI conversation in the enterprise is about models, agents, and copilots. Almost none of it is about the data platform underneath. That is backwards.
Models are commoditizing. Agents are commoditizing. The data platform is not. It is the one layer your organization actually owns, and it is the layer that will determine whether your AI investments produce decisions you can trust or failures you cannot explain.
The companies that win the next decade of AI will not be the ones with the best models. They will be the ones whose data platforms were built to be queried, governed, and trusted by systems that never sleep.