

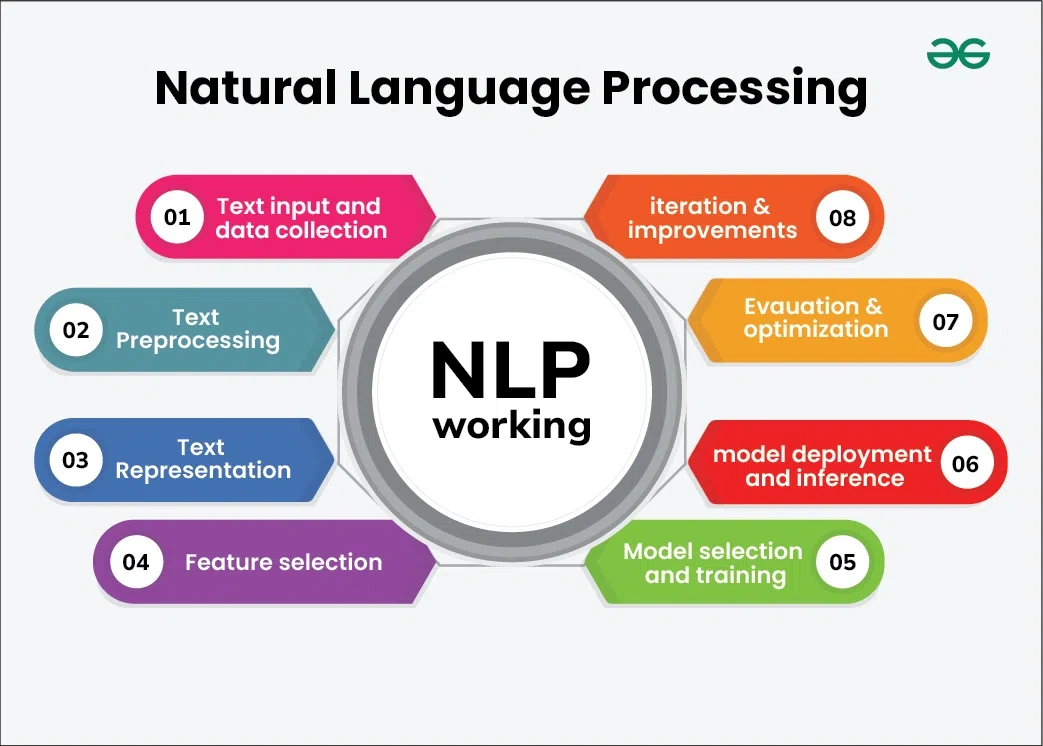
AI-generated text detection reaches up to 93% accuracy with BERT models, which perform by a lot better than other classification methods. These detection systems still have flaws and can only identify AI content correctly 7 out of 10 times in sample tests. The challenge to tell human and machine-written content apart has led experts to develop advanced natural language processing (NLP) techniques.
Researchers look for specific linguistic patterns to spot AI generated text. AI text classifiers measure predictability through perplexity scores, and higher values usually point to human authorship. Burstiness measurements show how sentence structures vary, and human writing shows more diversity than AI-generated content. Tools like Originality.ai can misclassify between 10% and 28% of human-written pieces as machine-generated, which proves these detection methods aren’t perfect yet. Visit AIDetector for practical insights and up-to-date detection results using real-world text samples. Content creators and educators can better guide through AI text identification by understanding these detection methods and knowing their current strengths and limits.
How NLP Enables AI Text Detection
NLP forms the foundation of systems that detect AI generated text. These detection tools work through language pattern analysis that breaks down both human and machine-written content into parts we can study.
Tokenization and Embedding Representations
The first step in AI text detection involves tokenization—breaking text into smaller units called tokens. These tokens represent words, subwords, or characters based on how the system is designed. To cite an instance, the sentence “The cat sat on the mat” becomes tokens like [“The”, “cat”, “sat”, “on”, “the”, “mat”] at word level.
The next step converts each token into numerical vectors through embedding. These vector representations capture meaning in a multi-dimensional space where:
- Words with similar meanings cluster together in vector space
- Mathematical formulas show relationships between concepts
- Context and meaning become measurable features
Word embeddings like Word2Vec and GloVe turn text into numbers that algorithms can process. These vectors help detection systems spot subtle patterns that tell human writing from machine-generated content.
Contextual Understanding via Transformers
Transformer-based models have revolutionized how we detect AI generated text, and they also power modern AI Writing Assistant Software listed in Revoyant used for content generation and editing.BERT (Bidirectional Encoder Representations from Transformers) achieves 93% accuracy when it distinguishes AI-written content from human writing.
BERT looks at the entire text sequence at once, unlike older models that read text in one direction. This helps it understand the context around each word better. The bidirectional approach lets the model:
- See how words connect across sentences
- Pick up subtle meanings from surrounding text
- Find patterns unique to AI-generated content
Transformer architecture uses multiple attention mechanisms that focus on different parts of a sentence at once. This creates a complete understanding of context that helps detect AI text accurately.
Role of Named Entity Recognition and POS Tagging
Part-of-speech (POS) tagging labels each word’s grammatical role in a sentence—showing nouns, verbs, adjectives, and other elements. Detection systems use this structural information to see how AI and humans build sentences differently.
Named Entity Recognition (NER) finds specific information types in text, such as:
- Person names
- Organizations
- Locations
- Dates and times
- Quantities
Detection systems use NER to review how AI models handle facts and proper nouns compared to human writers. The process starts with labeled text datasets where entities are marked. Then it extracts features like POS tags and word embeddings to train detection models.
These methods give AI text classifiers advanced language analysis capabilities. They look at token patterns, context relationships, and structure to find subtle signs that separate human writing from machine text. However, challenges with accuracy and bias still exist.
Detection Algorithms and Statistical Methods
Statistical methods are the foundations of modern tools that detect AI generated text. These tools look at subtle language patterns to distinguish machine-generated content from human writing. Modern AI Content Detector Software listed in Spotsaas applies these statistical models to measure specific text properties and how words are distributed. They measure specific text properties and how words are distributed.
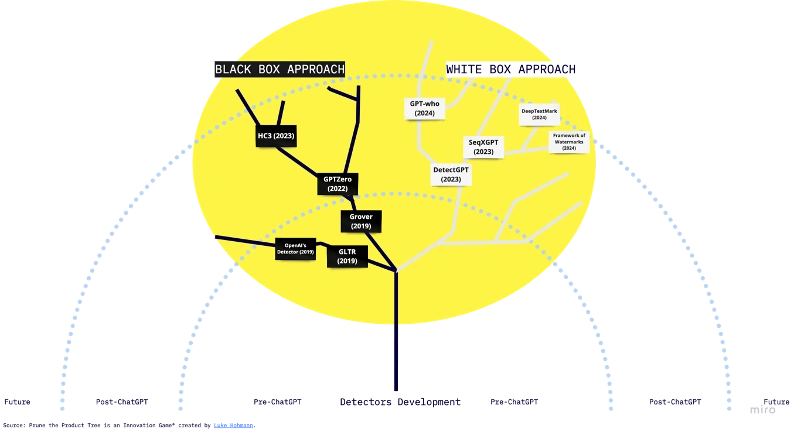
image source: tractari auto oradea pret
Perplexity and Burstiness Metrics
Perplexity measures how “surprised” a language model is when it sees text. It reviews how well a probability model predicts a sample. Lower scores point to more predictable content. AI-generated texts usually show lower perplexity scores because large language models are trained to maximize text probability by minimizing perplexity. The math involves the exponent of the negative log-probability of text, which shows predictability patterns.
Burstiness looks at how sentence structure, length, and complexity change. People’s writing naturally has higher burstiness because we write in bursts and lulls. We mix long, complex sentences with shorter ones based on our creative flow. AI-generated content tends to be more uniform with steady pacing and consistent tone, which leads to lower burstiness scores. Studies show original human-written abstracts scored a lot higher on burstiness than AI-generated versions in many text formats.
N-gram and Function Word Frequency Analysis
N-gram analysis looks at sequences of ‘n’ words or characters to find distinct patterns in text. This method reveals how often certain word combinations appear and can expose AI’s preference for specific phrases. Research shows AI-generated abstracts use similar n-grams more often, especially in higher n-gram ranges (3-grams and above). This shows less variety in language compared to human writing.
Function words analysis focuses on common grammar elements like prepositions, conjunctions, and articles that humans use without thinking. These words make up less than 0.04% of vocabulary but account for over 50% of words we actually use. This analysis works because:
- Function words come from the brain’s Broca’s area and work subconsciously in human writing
- They create unique linguistic fingerprints that process differently than content words
- Their patterns differ noticeably between AI and human writing
Studies of verb frequency show AI systems favor certain verbs in all topics. Words like “including” (0.1203%), “leading” (0.0834%), and “making” (0.0641%) appear regularly whatever the subject.
Stylometry for Authorial Fingerprinting
Stylometry uses statistical analysis to find unique writing styles. Originally created to attribute authorship to anonymous documents, it now helps find distinctive “fingerprints” in text based on measurable language features.
An evidence-based model called StyloAI shoes stylometric analysis’s power. It uses 31 features across six categories to tell AI and human writing apart:
- Lexical diversity (vocabulary richness, type-token ratio)
- Syntactic complexity (sentence structures, complexity)
- Sentiment and subjectivity (emotional tone patterns)
- Readability metrics (text complexity indicators)
- Named entities usage (specific names, places, organizations)
- Uniqueness and variety (content originality measures)
This stylometric approach achieved 81% accuracy on the AuTextification dataset and 98% on the Education dataset when tested on different types of writing. These results beat previous detection models.
So, these statistical methods show clear, measurable differences between human and machine-generated text. They offer reliable ways to detect AI generated content across different contexts and writing styles.
Building an AI Text Classifier: Step-by-Step
Building a reliable classifier to detect AI generated text needs careful preparation and testing. The process combines machine learning expertise with natural language processing techniques through several technical steps.
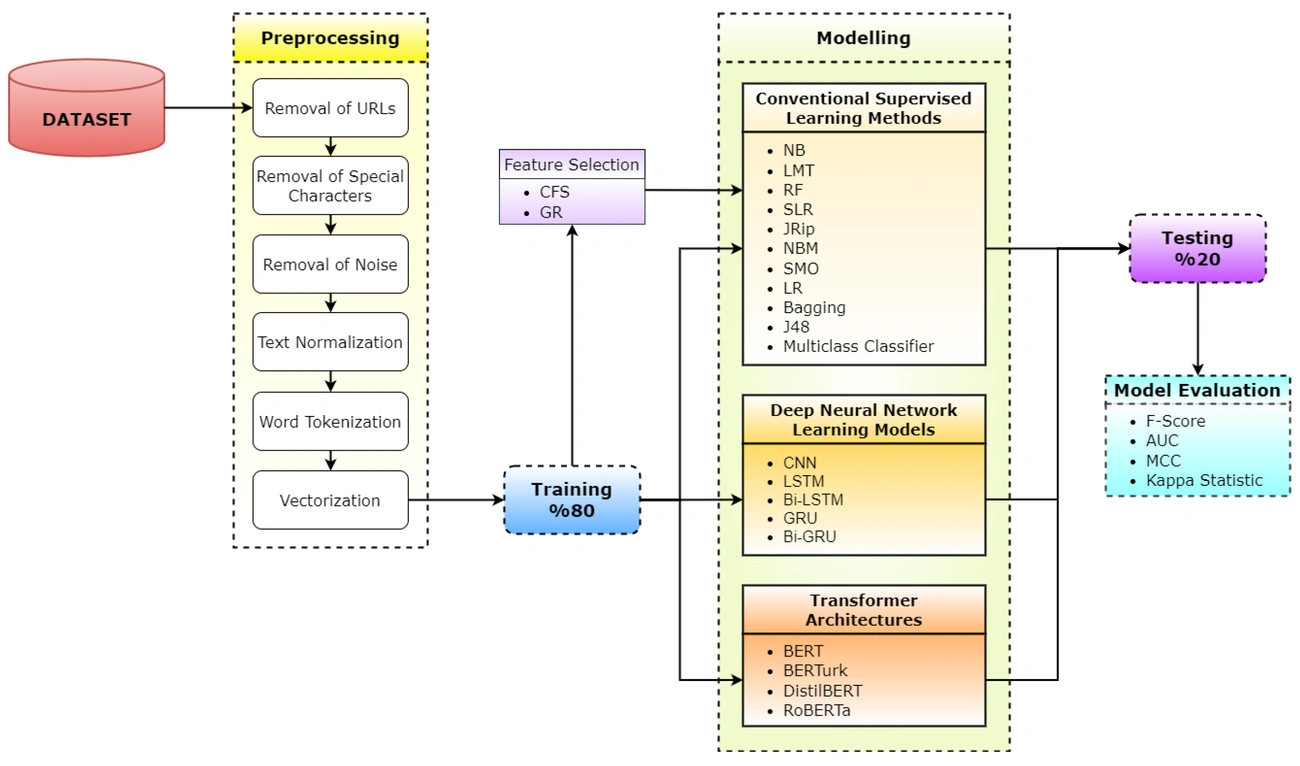
Dataset Preparation: Human vs AI Text
Quality data forms the foundations of any good AI text classifier. Detection models that work well usually employ balanced datasets with both human-written and AI-generated content. To name just one example, OpenAI’s classifier went through fine-tuning on “pairs of human-written text and AI-written text on the same topic”. Another research study created a dataset with 4,231 question-answer combinations from Applied Statistics that had equal numbers of human and AI-generated responses.
Good dataset preparation needs:
- Text normalization (converting to lowercase, removing special characters)
- Balanced word counts between human and AI samples to avoid length bias
- Train/validation/test splits for model development
Research showed that after processing, “the average machine generated word count is 276 and average human generated word count is 256”. This shows why controlling length bias matters – models might otherwise detect based on text length instead of language patterns.
Fine-tuning RoBERTa with LoRA
RoBERTa models excel at detecting AI-generated content, but traditional fine-tuning of these large models needs substantial computing power. Low-Rank Adaptation (LoRA) solves this by cutting down the number of trainable parameters.
LoRA freezes the pre-trained model weights and adds smaller matrices that represent updated weights through low-rank decomposition. This method brings impressive efficiency gains:
“The model with LoRA has about 200 times fewer trainable parameters than the fully fine-tuned model, greatly reducing computational costs”. It also trains “25% faster than the fully fine-tuned model, while only having 1.1% less accuracy after 3 epochs”.
Implementation typically follows these steps:
- Starting with a pre-trained RoBERTa model
- Adding LoRA layers to Query and Value vectors in Attention layers
- Training with parameters like lora rank (8-16) and lora alpha (16-32)
Evaluating Accuracy with Confusion Matrix
A full picture helps determine how well the classifier spots AI generated text. The confusion matrix gives a complete view of model performance through four key metrics:
- True Positives (TP): AI text correctly identified as AI-generated
- False Negatives (FN): AI text incorrectly classified as human-written
- False Positives (FP): Human text incorrectly classified as AI-generated
- True Negatives (TN): Human text correctly identified as human-written
Specialized metrics beyond accuracy help learn about detection capabilities. Precision tells us how often positive predictions are right, while recall measures if an ML model can find all instances of the positive class. The F1 score, which represents the harmonic mean of precision and recall, offers a balanced way to measure performance, especially with imbalanced datasets.
Today’s best systems show different levels of success. Originality.ai achieved impressive results with “the highest true positives = 5,547” and “the lowest false negatives = 243” on their test dataset. OpenAI’s classifier, however, correctly identified only “26% of AI-written text as ‘likely AI-written'”.
Ethical and Practical Challenges in Detection
Technical advances in AI text detection systems haven’t solved their most important ethical challenges. These problems are systemic and threaten detection methods’ reliability and fairness in settings of all types.
Bias Against Non-Native Writers
AI detection tools show clear bias against non-native English speakers. A Stanford study found these tools could accurately classify essays from US-born students. However, they wrongly flagged more than half (61.22%) of English proficiency test essays from non-native speakers as AI-generated. The results get worse. All seven tested detectors wrongly labeled 19% of human-written TOEFL essays as machine-generated. At least one detector flagged 97.8% of these essays.
This bias comes from detection algorithms that heavily rely on “perplexity” metrics associated with linguistic sophistication. Non-native writers naturally score lower in word richness, diversity, and sentence complexity. These are the same markers these tools use to spot AI text. The irony is that these biased results might push non-native speakers to use AI tools more often just to avoid false accusations.
Transparency and Explainability in Classifiers
AI detection systems work like mysterious “black boxes” and barely explain their decisions. Nobody flagged by these systems can understand or challenge the results. AI systems need to reveal their model operations, algorithm logic, and evaluation methods to be truly transparent.
Systems without clear explanations risk losing people’s trust, especially since they make many mistakes.
Responsible Use in Education and Hiring
Educational institutions know these limitations and increasingly avoid detection tools to enforce academic integrity. One university chose not to use Turnitin’s AI detection because they didn’t know how it would affect students. This careful approach makes sense because false cheating accusations can harm students both mentally and physically.
Experts say detection results alone should never prove misconduct. Organizations must create clear policies that explain how detection tools work. They need simple appeal processes and must train their evaluators properly.
Future of AI Detection and Watermarking
Watermarking technology and detection methods must keep pace with text-generating AI to identify machine-authored content. These new approaches show promise with better accuracy and resistance against evasion techniques.

Resilient Watermarking in LLM Outputs
AI text generation advances have made watermarking systems more sophisticated. Semantic watermarking marks a breakthrough by embedding markers in the content’s meaning rather than surface-level patterns. This makes them harder to remove through paraphrasing. Context-aware watermarks adapt their implementation based on content type. They apply strong detectable markers for academic writing and use subtle touches for creative content.
In spite of that, watermarking has its limits. Google admits that generative watermarks stay vulnerable to “stealing, spoofing and scrubbing attacks.” They weaken by a lot when text goes through edits or LLM paraphrasing. Future systems could use cryptographic pseudorandom functions with keys known only to model developers. This would allow detection without affecting output quality.
Multi-modal Detection Systems
Future detection will combine multiple data types at once. Unified watermarking ecosystems could embed synchronized markers in content of all types. This creates interconnected webs of traceable authenticity. Videos with AI-generated dialog could carry synchronized text and audio watermarks. Such an approach makes manipulation more challenging.
This multi-modal strategy reflects broader AI development trends. Modern systems combine numeric data, text, images, and video to achieve richer and more accurate results.
Integration with LMS and CMS Platforms
Detection tools will blend more smoothly with existing educational and professional platforms. Learning Management Systems (LMS) with detection features could track revision histories and confirm writing process authenticity. Such integration would verify content continuously instead of after the fact.
Privacy issues remain a major concern. “AI labs could potentially be compelled to reveal user identities through legal requests from law enforcement agencies”. Many users might not realize their AI-generated outputs leave a trail. This raises questions about transparency and informed consent.
The future of AI detection and watermarking must strike a balance between effective identification, privacy protection and clear implementation.
Conclusion
The rise of AI-generated text detection has become a complex technological race between sophisticated language models and detection systems. In this piece, natural language processing acts as the life-blood of these detection mechanisms. Without doubt, detection accuracy has improved substantially through tokenization, embedding representations, and transformer models. BERT-based approaches now achieve up to 93% accuracy in controlled settings.
Statistical methods are the foundations of effective detection systems. Perplexity scores and burstiness measurements help separate human and AI-written content based on predictability patterns and linguistic variety. On top of that, n-gram analysis and function word frequency reveal subtle markers that humans often miss but algorithms can calculate with precision.
We have a long way to go, but we can build on this progress. Current detection systems don’t deal very well with content from non-native English speakers, which raises serious ethical concerns about algorithmic bias. Developers need to address these fairness issues before widespread adoption. The lack of transparency in these systems’ decision-making process undermines trust and prevents proper accountability.
AI text detection is moving toward multi-faceted approaches. Semantic watermarking embedded in LLM outputs shows promise, though text modification vulnerabilities persist. Multi-modal detection systems that analyze patterns across different content types could provide more resilient identification mechanisms as AI continues to advance.
Perfect detection remains out of reach despite our progress in identifying machine-generated content. Organizations must balance technological solutions with thoughtful policies during this transition period. These policies should acknowledge both the strengths and limitations of current detection methods. The development of these technologies will definitely shape how we authenticate content in our increasingly AI-influenced world.


