

Facebook’s conversational AI is now capable of generating a second of audio in a text-to-speech format in half a second according to a reveal by Facebook on their blog on Friday.
The powerful text-to-speech (TTS) system can be used in real-time using regular processors and is currently powering their flagship physical product the Portal.
The role of the TTS system is to use neural networks to mimic the nuances of human voice where one second of speech can require a TTS system to output as many as 24,000 samples which requires massive computation.
To give you an idea of how expensive this might be to Facebook, Google’s latest-generation TPUs have an operating cost of between $2.40 to $8 per hour on the Google Cloud Platform.
The Portal, which was released in November 2018, is a smart display available in four variations that can be used for video calling and available for use on selected Facebook applications, from reading support for the visually impaired to virtual reality (VR) experiences.
Facebook said in the company blog that their “long-term goal is to deliver high-quality, efficient voices to the billions of people” in their community with building and deploying this neural TTS system as a way to reach the goal while not jeopardising any quality.
Speaking on Facebook’s conversational AI in a statement, the company said: “The system … will play an important role in creating and scaling new voice applications that sound more human and expressive,”
How Facebook’s Conversational AI works
The conversational AI system is highly flexible and is going to be used to create and scale new voice applications that “sound more human and expressive” making the experience more enjoyable for the end-user.
The components of the system focus on four different functions of speech including a linguistic front-end, a prosody model, an acoustic model, and a neural vocoder.
Neural-based TTS pipeline
The neural-based TTS pipeline is what processes Facebook’s conversational AI to create the audio for the end-user to listen to with each function focussing on a different aspect of speech.
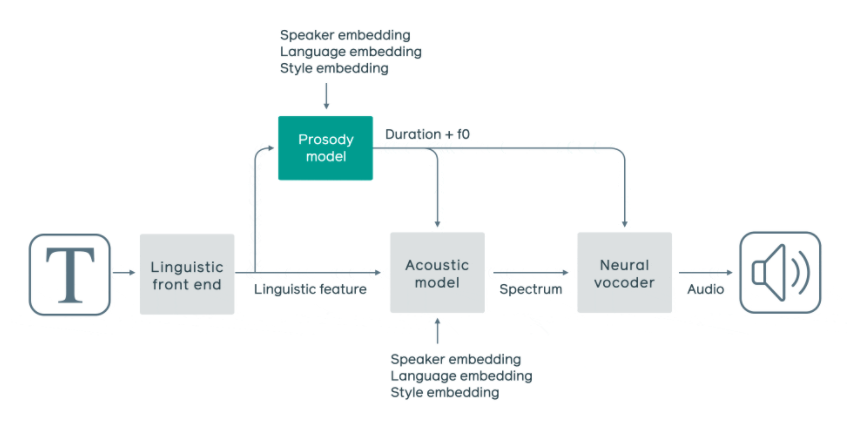
Linguistic front end
The linguistic front-end converts the input text to a sequence of linguistic features, such as phonemes and sentence types.
These are units of sound that can be distinguished so you can hear one word clearly from another word to avoid confusion with an example being rod and rot.
Prosody Model
The prosody model function in Facebook’s conversational AI predicts the rhythm and melody to create the expressive qualities of natural speech.
Facebook highlight the importance of building a separate prosody model in the neural-based TTS pipeline as it allows for easier control on the speech style during synthesis time.
Having this process as part of the pipeline allows for it to draw on the linguistic features, speaking style, and language format so the model can interpret and predict the sentences speech-level rhythms and their frame-level fundamental frequencies.
With Facebook’s conversational AI picking up speaking styles it can create new voices that would be used in voice assistants and change the tone, manner, and speed in which that virtual assistant speaks to people.
In the Facebook blog unveiling their conversational AI they say: “Its model architecture consists of a recurrent neural network with content-based global attention, whose context vector contains semantic information of the entire sentence. This allows the model to generate more realistic and natural prosody.”
According to Facebook this only requires 30 to 60 minutes of data for each new style to be configured, an impressive time when you look at the hours of recording it takes for an Amazon TTS system.
Acoustic Model
The acoustic model allows Facebook’s conversational AI to achieve higher computational efficiency and high-quality speech thanks to the conditional neural vocoder architecture they adopted which makes predictions based on spectral inputs instead of one that generates audio directly from the text or linguistic features.
Having this approach enables Facebook’s neural vocoder to focus on spectral information packed in the neighboring frames while allowing training to happen on a lighter and smaller neural vocoder.
Neural Vocoder
The neural vocoder is the function that’s made it possible to take the time down from the earlier version of the TTS system which took 80 seconds to the current model which is generating one second of audio in less than half a second.
Facebook’s conditional neural vocoder consists of two key components: a conversational neural network and a recurrent neural network.
The conversational neural network upsamples the input feature vectors from frame rate, at roughly 200 predictions per second, to a sample rate, at roughly 24,000 samples per second.
The recurrent neural network synthesises audio samples auto-regressively (one sample at a time) at 24,000 samples per second.
This allows for Facebook’s conversational AI acoustic model to leverage conditional architecture to make predictions based on spectral inputs, or specific frequency-based features.
Facebook’s conversational AI achieves 160x faster speed for real-time performance on CPUs
By combining and implementing optimisation techniques including tensor-level optimisations and custom operators, unstructured model sparsification, blockwise sparsification, and distribution over multiple cores Facebook’s conversational AI was able to witness a 160x improvement in synthesis speed achieving an RTF of 0.5 as seen in the image below.
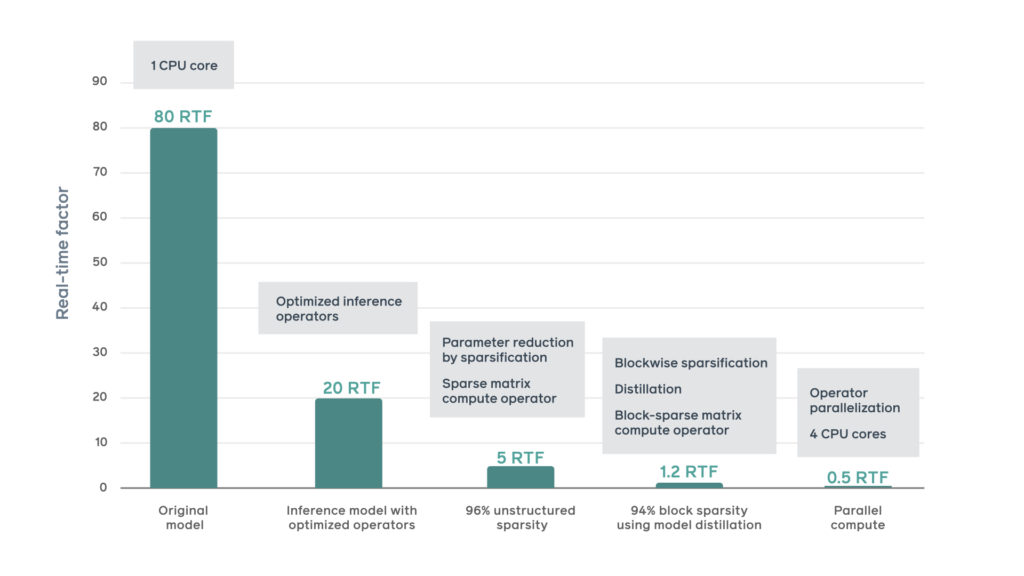
With the help of training-orientated PyTorch, Facebook were able to setup to an interference-optimised environment giving the conversational AI additional speedup and reducing the total operator loading overhead.
Facebook witnessed a 96 percent unstructured model sparsity – where 4 percent of the model parameters are nonzero – without degrading audio quality thanks to the unstructured model sparsification.
Due to using the optimised sparse matrix operators Facebook’s conversational AI increased the speed by five times.
The blockwise sparsification allowed for nonzero parameters to be restricted in blocks of 16×1 and to be stored in contiguous memory blocks so that memory bandwidth utilisation and cache usage can be significantly improved.
By using the distribution over multiple corses, the conversational AI model witnessed further speedup by distributing heavy operators over multiple cores on the same socket.
Facebook’s conversational AI collects training data more efficiently
The new training method was adopted from using corpora for statistical text-to-speech systems as outlined in a study by Google in 2018.
The training method (outlined in the picture below) relies on a corpus of hand-generated utterances and was modified to select lines from large unstructured data sets.
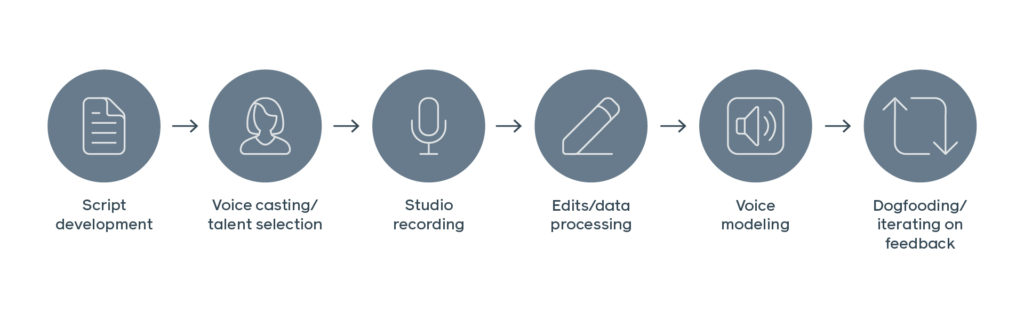
Facebook said the modified approach above led to fewer annotations and studio edits for the recorded audio from a voice actor as well as improved TTS quality and allowed Facebook to scale to new languages rapidly without relying on hand-generated datasets.
Combined with the improved neural TTS system it’s helped them reduce voice development cycle from what was a year to under six months and create voice in new accents and languages with the first success being a British-accented voice.
What’s the future of Facebook’s conversational AI
With voice assistants technology becoming more and more common and Facebook letting us know they are developing technology capable of detecting people’s emotions through voice we could see a feeling matched voice assistant in people’s homes.
For example, if you’re in a quiet room, Facebook’s conversational AI would respond in a quite and softer tone compared to if you were cooking with the family around where it would speak in a deeper more defined voice.
The next steps Facebook will be taking is adding more languages, tones, dialects, and accents to the conversational AI’s speaking portfolio.
Facebook says “with our new TTS system, we’re laying the foundation to build flexible systems that will make this vision a new reality” which will align with their long term goal of delivering high-quality, efficient voices to billions of people.
2 Comments