
Regulatory reporting burden rising fast
GaiaLens has noticed that an increasing number of large enterprises in heavily regulated markets are piloting the use of AI to save time and resources associated with the increasing burden of regulatory reporting.
Therefore, it makes sense to take closer looks at some best practice in the area of using AI to streamline and automate regulatory reporting. If done right, AI can prove extremely effective in automating both internal and external reporting associated with key regulatory compliance and pricing negotiations.
The core consideration when building these sorts of projects is to target AI pilots towards reporting activity where the data collection and analysis burden is increasing year on year, and workload is projected to continue rising with that burden. Typically, the process of pulling the data together, analysing and validating its accuracy, drafting the explanatory narrative for key findings and using all the resulting rich data to create a report ready for the regulator takes too long today. So, by the time the report is filed it’s often out of date.
Tackling ‘messy data’
AI can add value where staff within your company’s data team are currently having to manually copy and paste data between disparate systems that are not integrated with each other. In this common scenario, there is no single version of the truth available. Teams pull together data at different times and tweak it slightly – forcing huge efforts to work out which numbers are actually correct.
Fragmented systems mean that data lacks a shared vocabulary or syntax. For example, if ‘sales revenue’ in System A including pending sales but ‘revenue’ in Systems B only counts cleared funds, the resulting report will fail unless human intervention untangles the semantic mismatch. This is why adopting standardised methods, for models to connect to fragmented data sources seamlessly and securely, is becoming an architectural imperative for AI projects.
It’s important to see AI as a dynamic partner that is capable of doing the heavy lifting so your experts can focus on strategy, context and affirming accuracy of the results that it’s generating. AI done right can be a hugely powerful engine for synthesising data and generating complex insights at scale. However, it is not a magic button which you press to generate highly regulated reports without human oversight. Beware of consultants who are offering this sort of nirvana.
Data unification & integration
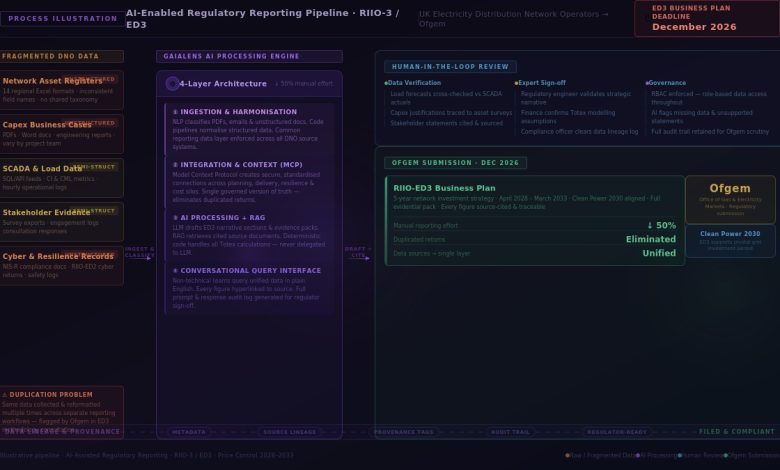
How then should AI projects be built for regulatory reporting? It’s a combination of unifying fragmented data architectures to enable connectivity between key data silos; and pairing new integrated data sets with smart conversational interfaces which enable staff to query the data and get instant, structured answers which they can act on to run their business better.
Let’s get into the four distinct layers which enable a robust AI-enabled data architecture for regulatory reporting to be built:
- Ingestion & Harmonisation: These are the data streams which pull and standardise the data
- Integration & Context Layer: Setting standard protocols such as Model Context Layer or Model Context Protocol (MCP).
- AI Processing & Retrieval: The Large Language Models paired with retrieval architectures (RAG) to extract, summarise and draft securely.
- Presentation & Interactivity: The ‘human in the loop’ interface which increasingly takes the form of secure, conversational AI agents which allow users to query the data and generate insights without being SQL (Structured Query Language) experts.
Before using AI to draft your reports, AI is very well placed to help you automatically scan, classify and tag your unstructured documents, using its natural language capabilities to turn the messy data swamp into a clean structured foundation for future reporting.
Structured and unstructured data
You need to process unstructured data differently from structured data. Structured data (numbers, databases etc) should be routed through deterministic analytical pipelines. Allows standard code (e.g. Python or SQL) to execute pre-prescribed transformations, checks, joins, aggregations and validations.
Unstructured data such as PDFs, emails, and memos should be routed through NLP and AI models to extract entities, sentiment and facts. These are then converted into structured formats to join to join the main data pipeline. Never ask an LLM (Large Language Model) to do complex arithmetic or apply strict compliance logic. Use standard code for deterministic calculations. Pass the results of those calculations to the AI system, instructing it to synthesise, summarise, draft the narrative surrounding the numbers, and surface them via an intuitive query interface.
Traceability key
Remember, that use of metadata, lineage and provenance is vital in automated reporting. These are vital for building trust in the data that the AI system generates. Provenance tells the AI where a fact came from, lineage tells it how it was transformed, and metadata tells it what it means. Without these, you cannot audit an AI’s output, making it useless for regulatory or financial reporting.
Which reporting tasks are best suited to AI today?
AI is ideal for first draft narrative generation summarising hundreds of pages of supporting documents, sentiment analysis on operational reports, and providing conversational interfaces that democratise access to complex data for non-technical teams.
AI adds a huge amount of value in extraction (pulling specific clauses from unstructured text), classification (categorising disparate data streams), and accessibility (allowing users to ‘talk’ to massive datasets to find exactly what they need instantly).
AI can also help map source system data into templates, reporting structures or output formats. Here it acts as a ‘semantic bridge’. Instead of a human manually mapping col_rev_01 to Q3_Gross_Revenue, an AI system can read the metadata, understand the context of both the source and the target template, and automatically suggest and/or execute the mapping with high confidence.
AI is also brilliant for assembling evidence packs and supporting documentation associated with regulatory reporting. It’s particularly useful when supported by Retrieval-Augmented Generation (RAG). A robust RAG pipeline allows AI to instantly query a vast repository of internal documents, extract the paragraphs needed to justify a reporting metric, and compile them. This approach is also heavily used today for completing onerous public sector tender response documents, for example. Furthermore, RAG provides an interface where reviewers can follow up with specific questions about that evidence in real-time.
AI can also help identify missing data, inconsistencies or unsupported statements.
Here AI becomes a faultless semantic proofreader and fact checker. It can scan a drafted report, cross-reference it against your underlying data lake (often using RAG to verify facts against the source documents), and flag statements like “Sales grew robustly in Q3” if the underlying data actually shows a two per cent decline, or highlight areas where required compliance fields are blank. You should see AI as the best way to get to a first draft in terms of commentary or narrative around reported figures, ready for your human expert to review.
Ground control
In terms of the governance and controls that are needed to deploy AI for regulatory reporting, strict role-based access control (RBAC) is critical. RBAC should be enforced at the context level to ensure models only retrieve data that the specific user is authorised to see.
Organisations also need prompt and response logging for audit trails, data loss prevention (DLP), and mandated human-in-the-loop checkpoints before any report is finalised.
The human reviewer should be presented with the AI-generated draft together with hyperlinked citations to the exact source data used. Ideally, this happens within an interactive interface where the reviewer can ask the AI, “Show me the regional breakdown for this specific figure,” to give them an instant citation to verify the logic before sign-off.
By implementing strict RAG architectures organisations can ensure every figure, statement or commentary element is traceable back to verified source data. The AI must be constrained to only generate statements based on provided, retrieved documents, and instructed to append citation tags to every sentence. The user interface should then allow the reviewer to click any claim and instantly view the highlighted source text.
Beware of ‘automation complacency’ where reviewers trust the AI too much and rubber-stamp reports without fully checking them. Additionally, there are risks of confident hallucinations making it into external reports, and the ingestion of biased data skewing the narrative.
Getting started with AI pilots
A good area to look at for any AI reporting pilot is an internal operational report such as weekly department status summaries, monthly IT resource utilisation reports, or even deploying an internal chatbot for HR-related data gathering.
You can run these pilots in ‘shadow mode’. Keep your existing human-driven reporting process running and build the AI pipeline alongside it to assess a single, low-risk use case. Compare the AI’s output against the human’s output for speed, accuracy and depth over two reporting cycles before replacing the manual workflow.
Don’t be tempted to focus upfront on building the ultimate AI model (the ‘brain’) and ignore the data pipeline that is needed to feed it (the ‘nervous system’). Don’t try to launch sophisticated data-querying bots before bringing together and cleaning the underlying data which is likely to be sitting in fragmented, ‘dirty’ Excel spreadsheets, leading to failed pilots and lost executive trust.
Fix your data foundation first, don’t just bolt AI onto broken legacy data systems. AI won’t fix a ‘messy’ data culture. However, once you get your data clean and establish secure, standardised connections (like MCP) to your sources, everything changes. With that solid plumbing in place, you can deploy powerful conversational interfaces to transform reporting from a tedious manual chore into a dynamic, real-time conversation with your enterprise data.
For those that get started on AI pilots this year, clear rewards should begin flowing within 12 months. Once organisations have used AI to speed up the filing of key regulatory reports’ it becomes possible to go further to use it to unlock enterprise data in all aspects of your business – transforming how your stakeholders interact with their information. With strong governance in place, they will be able to extract real-time insights from that data to help them make better business decisions, faster, working with a single, up to date version of the truth.




