

Machine Learning is one of the most crucial technological sciences behind the Generative AI models that we have come to know and love in recent years. But as demand for new, larger, and improved LLMs grows, so does the corresponding ML workload they entail.
Weights and Biases (W&B) is one of the core businesses that caters for the increasing ML workload, offering a set of scalable and integrated solutions to optimize MLOps. To the tech-savvy among us, this might already be clear from the company name. But for those less familiar with ML terminology:
- ‘Weights’ refer to the degree of importance that specific connections between words and phrases have within the parameters of an LLM’s neural network.
- ‘Biases’ refer to the starting points in a model’s development, acting as generalized constraints which guide the model’s interpretation of the data it is then trained on.
With a background in providing tools for AI engineers and data scientists, MLOps were a natural area of specialism for two of the co-founders, Lukas Biewald and Chris Van Pelt, who came together with ex Google Software Engineer, Shawn Lewis, to found the company in 2017.
In doing so, they identified a key niche within the tech industry that would ultimately establish the company’s position as a leading provider in MLOps, counting customers such as OpenAI, Meta, Google DeepMind, and more.

The critical difference between software development and ML engineering
In an opening keynote speech at Weights and Biases’ annual ‘Fully Connected’ conference in London on 15th May 2024, CEO and Co-Founder Lukas Biewald highlighted the company’s fundamental mission: to give ML engineers the tools and support they need to develop AI to the same extent that software developers have the tools they need to develop software.
“We started out with the observation that software engineers have amazing tools to make software. But ML engineers at that time did not have these amazing tools”
Lukas Biewald, CEO and Co-Founder of W&B
For some businesses, the line between software development and MLOps can be a fuzzy one, given that ML is typically integrated into software applications, and the fact that the term ‘software’ is often used to refer to a broader spectrum of applications that take place virtually over a network. However, W&B emphasize some fundamental differences between software development and ML engineering.
“Software development is this very linear, iterative, arguably deterministic workflow. ML and AI development is essentially an experimental one. What this means is that when you develop software, your code is really your IP (intellectual property), and companies have long realised this – they protect their code, their version of IP. But when you develop models, it’s really the learning that’s unique. I think a lot of people at first thought maybe the models themselves are the IP – that’s maybe the better analogy to code – but you can’t actually inspect the models. There’s been 30-40 years of people working on model explainability, but I think that explainability is getting worse, not better.”
Lukas Biewald, CEO and Co-Founder of W&B
As businesses are increasingly coming to realize, the process of LLM development is a messy one, involving countless data points and extensive tuning of a model’s parameters to get the desired outputs from the input data. This fiddling around, alongside the huge scale of data, means that the end model typically has a low level of explainability, and can’t be easily replicated.
To really understand the ins and outs of a model’s artificial cognition, developers have to look at a model’s training trajectory – this refers to the history of the model’s parameter tuning. As Lukas pointed out, it is really the training trajectory of the model that is the IP of the ML process, rather than the model itself. Indeed, it is the training trajectory that enables developers to replicate models and thus optimize MLOps, even though the model itself is the marketable product for end users.
Thus, for W&B, the training trajectory represents an often-overlooked goldmine of data that is key to being able to reproduce good models, and collaborate effectively with other teams on ML projects.
This is becoming increasing recognized within the wider AI industry, with other companies beginning to utilize model trajectories for greater insights into ML processes. For example, Japan’s leading Telecom company, NTT, has recently found a more efficient way to fine-tune LLMs by using one model’s training trajectory to fine-tune other models, thus cutting the costs and time of this process. This innovation was fuelled by their discovery that the learning trajectories of different models are essentially identical to each other under a symmetry related to the permutations of neurons/nodes.
But such innovations require an efficient and easy way to store a model’s training trajectory. Without a structured workflow and the aid of technology, keeping a record of the training trajectory is a hard and laborious process. A few years ago, this meant that many ML developers weren’t even keeping a record of the training process, let alone a sufficiently detailed one that would enable the process to be replicated.
“They don’t track it [the training trajectory], because actually tracking things is hard. You can never rely on humans to consistently do this tracking, even if they really want to – and just tracking things like hyperparameters is not a complete related tracking. You actually need reproducibility.”
Lukas Biewald, CEO and Co-Founder of W&B
Overall, model reproducibility and explainability are crucial aspects of MLOps that help businesses with not just the development, but also the deployment of models. Within the overcrowded market of AI vendors, the ability to explain to clients exactly how the model is able to produce its outputs is a key selling point. Additionally, having a high degree of reliability and accuracy in model replication is crucial factor for business agility and resilience in the highly competitive and innovative arena of LLMs.
The problem of explainability in the real world
The lack of explainability and transparency into how LLMs really get from their input data to their outputs is a wider problem within the AI market. Several industries, such as the media, are restricted in their applications of AI because they require a high standard of transparency and explainability that many LLM developers cannot yet provide.
The BBC, for example, is a traditionally conservative company that can be slow to take advantage of emerging technologies. Nevertheless, in an effort to remain at the forefront of emerging AI technologies, it has undertaken several projects researching the applications of ML within traditional tasks. Danijela Horak, Head of AI Research at the BBC, highlighted several of these in her keynote as a guest speaker at the W&B conference.
LDRS services (local democracy reporting services)
The BBC often uses recordings made by locals to create articles and stories, with the write-ups of these transcripts traditionally being carried out by human editors. In an effort to modernize this task, the BBC took Mistral’s open-source LLM, and trained it on 10,000+ of these articles so that it could automate this task.
Transcription
More generally, transcribing audio files and recordings is a key application of ML within the media industry. But a significant challenge in this area is mitigating bias against dialect variation. While models can be fine-tuned to increase the accuracy of the audio-processing to be more inclusive of regional dialects, the final outputs are typically still far from optimal.
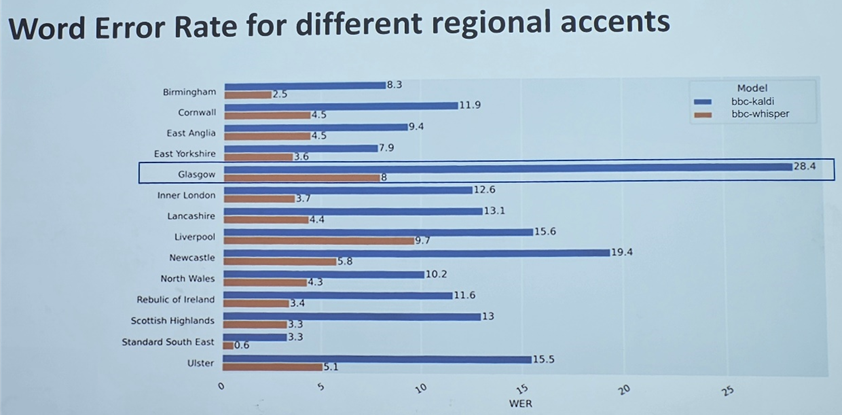
Image repair
Traditionally, the BBC would use Photoshop’s neural filter to remove scratches and damage from prints. However, this can be a time consuming and painstaking process. In a R&D project, the BBC developed their own ML model to automate this process and increase the quality of prints for their archives.
Video colourisation
To regenerate its large archive of old, black-and-white video tapes, the BBC has trialed a new AI technology to bring these videos to life by adding colour. This task can be done manually, but not in an efficient and cost-effective way – usually even a small clip of video requires hundreds of artists and restorers and a big budget. Nevertheless, AI’s utility for this use-case was limited in accuracy due to data insufficiency – in this case, due to a lack of quality coloured photos from a matching time and place.
Deepfake detection
As the deepfake threat rises, big media companies such as the BBC are tasked with finding effective ways to detect them and tackle the spread of misinformation. Traditionally, tasks such as information provenance, fact-checking, etc, are carried out by the BBC Verify Team (made up of approximately 60 journalists). More recently, BBC Verify trialed an AI technology, C2PA, which specializes in the provenance of digitally signed content, for such tasks.
Overall, there are several promising applications for AI in the BBC. But Danijela pointed out that despite the great potential for AI to optimize these tasks, the transparency and explainability of LLM models remains a key barrier to official adoption and implementation.
“The main issue for the newsroom when it comes to these models (apart from the fact that they don’t have great accuracy) is explainability. Even if we had a 92 or 95% rate of accuracy, we would still not be able to use them. So the key issue for our team and stakeholders was explainability and reproducibility.”
Danijela Horak, Head of AI Research at the BBC
The BBC are now working on building their own data set, so that they can provide greater transparency and explainability for their AI models by showing the provenance of the data that is feeding the model. They are also collaborating with the University of Oxford to carry out further research into this area, and hopefully find new ways that they can integrate AI technologies into media tasks in a safe, transparent, and explainable way.
Weights and Biases’ solution
Weights and Biases are helping tackle the problem of explainability by tracking and optimizing MLOps, focusing primarily on the back-end operations of ML.
Their most fundamental service is providing an automated system of record for developers. This ensures that model development can be more easily tracked, explained, and replicated.
Major development companies such as Salesforce have testified to the value of saving their development records. OpenAI, for example, said that W&B’s system of record increased their sanity amidst the chaos as the team grew.
Most impressively, one of their customers, Toyota, was able to speed up their product development 10x thanks to their system of record.
Weights and Biases’ latest offering, Weave, takes the company’s offering up a notch, providing a range of additional services and benefits. Created to ease the workload of foundation model builders, LLM developers, and software engineers, Weave’s applications are very easy to integrate, requiring just a single line of code to run – which also explains why it is referred to as the company’s ‘lightweight’ toolkit.
“The code is a huge engineering challenge, and it’s a huge product challenge – this is fundamentally what we’ve been working on for the last five years that we’ve been around.”
Lukas Biewald, CEO and Co-Founder of W&B
With this one simple line of code that seems almost too good to be true, Weave helps W&B customers to optimize their ML processes and capture more data from them. Its key provisions are:
- P-95 latency: this brings down the latency for the longest-running queries in foundational models, which in turn increases their compute power.
- A back-end aggregation map of data metrics (previously front-end): this makes the map more accurate and reflective of the underlying data, which can enable the engineers to identify a potential issue more easily.
- A visualisation of the model that can track its lineage and represent the mass of data running through its millions of nodes. W&B offer the fastest data lineage system in the industry.
- A ‘multiple views’ option for ML engineers which enables them to be more experimental in how they work: they can now cut the data in multiple ways and save it, and share these views with their team.
- A model registry which help teams carrying out fine-tuning operations to keep track of the models they are generating, and evaluate them according to standard metrics.
- Automated workflows, which mean that when a model’s trial run is completed, you can automatically trigger certain actions such as carrying out further runs on thousands of other machines, restarting the run in case of a crash, or evaluating the model using another LLM.
- An internal slackbot that can help employees with a variety of requests, and perform various troubleshooting functions on a secure, access-controlled basis.
- A high degree of flexibility and integrability which can fit into existing workflows and frameworks.
Weights and Biases’ cornerstone position in the ML ecosystem
A key factor which differentiates Weights and Biases from its competitors is the value it places on its partners and customers. In a TechCrunch article, Lavanya Shukla, VP of growth at W&B highlights that the company’s products are co-designed with partners and customers to ensure that they are actually meeting their needs.
This open and collaborative approach has helped place Weights and Biases at the centre of the delicately balanced ecosystem of MLOps, and means that their products tend to be fully integrable with other LLM providers. These include companies such as OpenAI, Nvidia, and many open-source development platforms including Hugging Face, PyTorch, and TensorFlow.
The collaborative creation of Nvidia NIM
To demonstrate the value of collaboration with partners to create integrated solutions, the company shared highlights from one of their recent and most exciting collaborations with Nvidia to create Nvidia’s NIM microservices, a project spearheaded by W&B Co-Founder Chris Van Pelt.
This collaborative project was born out of the company’s efforts to meet its customers’ fine-tuning needs for LLMs, a service which has seen a huge increase in demand as companies race to gain real value from customized LLMs trained on company-specific data.
NIM is included in Nvidia’s AI Enterprise software package, and is an enterprise-grade cloud platform that optimizes data pipelines and deploys generative AI applications such as chatbots. Weights and Biases has optimized this platform in several ways, helping to guide the users through the fine-tuning stages of development to an application-ready end product.
For example, they demonstrated how their tools would be able to make NIM’s user-request system easier to use by sorting the requests according to factors such as urgency, request type, area of application, etc.
The first step to achieving this would be fine-tuning a foundation model (in this case, Llama 27B), and running experiments with the user-request data to find out the optimal configuration of the model. This is where access to the model’s full lineage of datasets (as provided by the Weave toolkit) comes in handy.
Once the model has been selected, the developer can then promote it to the model registry, naming it for its specific purpose. At this point, it can be shared with a wider team so that all members can view the models which show the most promise.
This is the fundamental process of fine-tuning that W&B’s toolkit facilitates. But there is far more you can do with it, as CTO Shawn Lewis pointed out – just as the audience thought the demo was over.
“In reality, we’ve just gotten started. There’s still so many unanswered questions. How do we make our model run fast? How can we be sure that our service is using updated packages free from vulnerabilities? How do we rate and limit service usage?”
Shawn Lewis, CTO and Co-Founder at W&B
This is where the NIM platform really comes into play as a secure and highly efficient container for deployment. Utilizing NIM, ML developers have a great variety of options for how to run their MLOps in a secured and traceable way.
For example, they can manually trigger model compilation from the registry UI, or they can integrate the model with the platform’s existing CI/CD (continuous integration/development) system if they want to automatically run a compilation when a new alias (i.e. model version) has been added.
This gives developers a great deal of flexibility: they can carry out tasks on a fully manual basis, a fully automatic basis, or partly manual basis with an embedded AI agent available to pick up the tasks and optimize models for the specific accelerator (i.e. processing system) that they will be running on.
The embedded agent can also automatically test and evaluate the accuracy and latency metrics of the model before shipping it to users. All of these steps involved in the fine-tuning and deployment of a ML model are also captured within the system of record, even when they are fully automated.
“This gives teams peace of mind and the ability to audit, debug, and optimize every component of their MLOps pipeline”
Shawn Lewis, CTO and Co-Founder at W&B
Key Takeaways
- W&B’s fundamental goal is to make the process of ML model training more transparent and traceable. This is key for certain industries such as the media, where data transparency and model explainability is particularly crucial.
- As the AI industry comes under increasing scrutiny from governments (such as from the EU AI Act) and the law (think copyright infringement allegations), the need for transparency and explainability in MLOps pipelines will only increase.
- With business demands for specialized and customized ML tools growing at a fast pace, the already important role of MLOps will play an increasingly big role in AI adoption.
- W&B’s new toolkit, Weave, provides businesses with a strong range of user-focused solutions that have the additional benefits of customization and integrability.



