
Thesis: The hardest part of adopting agentic AI at scale isn’t building the agents. It’s productionizing the knowledge and data, the MCP-ready APIs those agents must safely call, and the reporting with attached KPIs that proves business value. Organizations that automate these three bottlenecks with LLM-powered processes, and ship in phased rollouts to learn from real users via RLHF/RLAIF, will outpace those waiting for 90%+ offline accuracy before launch.
Why agents, and why now?
Web-presence platforms span the full SMB lifecycle: build a site, acquire visitors, convert them to sales or leads, support them, then retain and expand. Copilots that draft copy or images help, but they don’t close loops. Real impact arrives when systems can plan, act, and learn across surfaces, website builder, domains/DNS, email, e-commerce, and support, under policy, permission, and budget. That’s an agent: not just a talker, but a doer that carries measurable responsibility for outcomes.
Most leaders agree on the destination. The struggle is the operational path: moving from impressive demos to repeatable, governed adoption across multiple products. The difference comes down to whether you treat data, tools, and measurement as first-class products, and whether you use LLMs to automate the heavy lifting in those areas.
The 80/20 reality of adoption
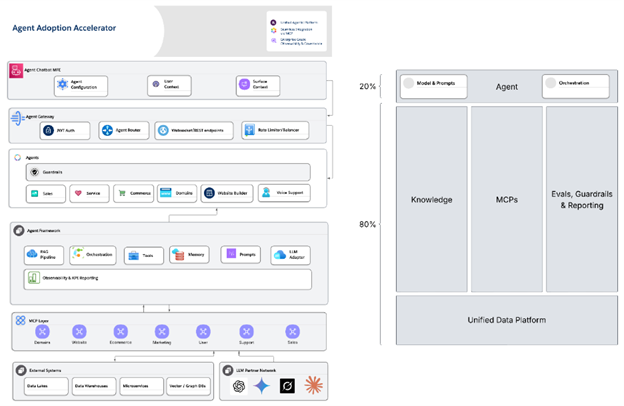
Figure 1 — Agent Adoption Accelerator. The left stack shows the delivery path from Agent Chatbot MFE → Agent Gateway → Agents → Agent Framework → MCP Layer → External Systems. The right frame encodes the 80/20 reality: the visible “agent” is roughly 20% of the work; the foundation – Knowledge, MCPs, and Evals/Guardrails & KPI Reporting on a Unified Data Platform is the other 80% that makes scale possible.
Pillar 1 — Industrialize knowledge for agentic RAG
Most “RAG problems” are data engineering and governance problems in disguise. Treat knowledge as a governed product and let LLMs automate the grunt work:
- Ingest & normalize. Pull from CMS/help centers, product catalogs, chat transcripts, incident runbooks, and telemetry. Use LLMs to extract structure, unify taxonomies, and tag entities (products, policies, plans).
- Sanitize by default. PII redaction, profanity filters, policy labels (PCI/PHI/export), de-duplication, and canonicalization before indexing so contamination doesn’t spread.
- Quality gates. Auto-score chunk health (readability, self-containment), prune semantic overlap, check freshness, repair dead links, and flag “opinion vs. policy.”
- Purpose-scoped indexing. Mark what’s safe to cite vs. what’s safe to act on; keep retrieval narrow to the task and the requester’s entitlements.
- Self-healing knowledge. “Doc diff” jobs trigger re-embeddings and regression checks when sources change.
Outcome: RAG becomes a governed knowledge plane your agents (and auditors) can trust, rather than a leaky cache that undermines confidence. (In Figure 1, this is the Knowledge column on the Unified Data Platform.)
Pillar 2 — MCP-ready APIs or it didn’t happen
Agents create value only when they can take safe actions. Standardize actuation behind Model Context Protocol (MCP) servers per surface, Domains, Email, Builder, Commerce, Support, so tools are consistent, discoverable, and hardened once for the entire company.
- Stable tool contracts. Idempotent operations; plan/dry-run → apply → rollback; deterministic error codes; rate limits.
- Least-privilege scopes. Per-tool service accounts and payload allowlists tied to tenant and role.
- LLM-assisted adapters. Generate/validate OpenAPI or GraphQL specs from examples; auto-draft wrappers, unit tests, and safety assertions.
- Shadow first. Agents propose plans; MCP validates preconditions (DNS ownership, MX conflicts, inventory locks) before writes.
- Unified observability. Every tool call emits structured logs, traces, and cost meters for SRE and finance.
Outcome: A tool registry you can harden once and reuse everywhere, velocity for teams, safety for the org. (In Figure 1, this is the MCP Layer.)
Pillar 3 — KPIs wired in from day one
If you can’t see it, you can’t scale it. Every agent ships with an agent contract:
- Objective & budget. e.g., raise first-contact resolution (FCR) within a $X/day cost envelope.
- Allowed tools & data scopes. What the agent may call and see, with tenancy and PII boundaries.
- Eval suite. Offline checks (retrieval quality, instruction following, toxicity) and online safeguards (guarded canaries, anomaly alerts).
- Telemetry → KPIs. Action outcomes tied to P&L metrics: time-to-publish, conversion/AOV, CSAT/FCR, deflection, ad-spend efficiency, stockout days.
Outcome: Agents earn autonomy with evidence, not aesthetics. (In Figure 1, this is the Evals/Guardrails & KPI Reporting column.)
Don’t wait for 90%: ship small, learn fast
Perfection is the enemy of adoption. Replace “model accuracy first” with fitness-to-act under guardrails:
- Level 1 — Advise. Agent plans steps and cites sources; a human executes.
- Level 2 — Approve-to-execute. Agent proposes a plan; executes with human approval; rollback armed.
- Level 3 — Budgeted auto-execute. Within policy and cost caps, the agent acts; humans review exceptions and weekly scorecards.
Each level is a feedback engine, not just a release milestone. In Figure 1 terms, you gradually move up the left stack—from Framework → Agents → Gateway → MFE—graduating autonomy as evidence accumulates.
Close the loop with RLHF & RLAIF
Shipping early matters because feedback is fuel:
- RLHF (human feedback). Approvals/rejections, edits, and accepted vs. rejected plans become supervised examples and reward signals.
- RLAIF (AI feedback). Critique-and-revise loops, tool-aware checkers, and contrastive pairs improve planning, validation, and tool selection without heavy labeling.
- Bandits & A/Bs. Compete prompts/tools/strategies against real KPIs; keep winners, retire losers.
- Safety hardening. Log jailbreak attempts, tool-abuse patterns, and hallucinated citations; convert them into tests and guardrails.
Principle: Optimize for safe, measurable action and let RLHF/RLAIF sharpen performance in the real world.
How to read the architecture (mapping to Figure 1)
- Agent Chatbot MFE. A thin micro-frontend that drops into any surface (web or voice). It carries consistent UX, context passing, and configuration without tying the platform to a brand or vendor.
- Agent Gateway. Centralized auth (e.g., JWT), routing, transport (REST/WebSockets), and rate limiting/balancing. This is your safety and tenancy choke point for multi-product scale.
- Agents row. Product-owned agents: Sales, Service, Commerce, Domains, Website Builder, Voice, each with a published agent contract (objective, budget, tools, scopes, evals).
- Agent Framework. The golden path: RAG pipeline, orchestration, memory, prompt libraries, LLM adapters, and Observability & KPI reporting. This is where reuse lives.
- MCP Layer. Surface-specific servers (Domains, Website, E-commerce, Marketing, User, Support, Sales) implementing plan/apply/rollback, scopes, and tracing. Harden once; reuse everywhere.
- External Systems & LLM Partner Network. Data lakes/warehouses, microservices, vector/graph DBs, and multiple model providers, swappable because contracts live above.
Operating model: organize for scale
- Platform team. Owns the agent framework, data plane, MCP standards, eval harnesses, guardrails, and observability.
- Product pods. Own intents per surface and assemble agents using the platform’s golden path.
- Policy-as-code. Approvals, budgets, tenancy, and PII scopes enforced at build time and runtime.
- Enablement. SDKs, prompt/component libraries, templates for agent contracts, internal training, and office hours.
This structure lets many teams ship quickly without fragmenting safety or reinventing the plumbing.
A shared agentic framework gives teams across website builder, domains, e-commerce, and customer support the opportunity to move fast without re-solving data, tools, and measurement.
- A unified data pipeline normalizes knowledge, runs LLM-powered sanitation/labeling, and maintains purpose-scoped indexes for RAG and training.
- Shared MCP servers expose safe actions like DNS changes, email setup, site provisioning, order lookups, and refunds—each with plan/apply, rollback, scopes, and observability.
- Guardrails + evals ship with every agent, and KPI dashboards track both model and business metrics by cohort.
- Phased rollouts (advise → approve-to-execute → budgeted auto-execute) accelerate learning while containing risk.
- Feedback loops combine RLHF (human approvals/edits) with RLAIF (AI critique) to improve reasoning and tool choice.
A recent application is a customer-support agent that plans and executes routine domain operations, changing DNS records, setting up email, and initial site configuration. The agent validates preconditions, dry-runs plans via our Domains/Email MCP servers, executes where policy allows, and falls back to human approvals elsewhere. Actions are logged to a tamper-evident audit trail; early impact shows meaningful handle-time reductions on targeted flows, with scope widening as policies and metrics allow.
A pragmatic 30/60/90 you can adopt
0–30 days — Foundation first
- Stand up the data plane basics: sanitation, labeling, purpose-scoped indexes.
- Publish two MCP servers with plan/apply/rollback and least-privilege scopes.
- Ship Level-1 advisor flows for 3–5 high-volume intents (e.g., add TXT, fix SPF, enable SSL).
31–60 days — Ship to learn
- Promote top intents to Level-2 approve-to-execute with canaries and rollback.
- Launch KPI dashboards; wire RLHF/RLAIF loops and bandit tests across prompts/tools.
- Expand MCP coverage to adjacent actions (e.g., refunds with holdouts, simple merchandising changes).
61–90 days — Earned autonomy
- Graduate safe intents to Level-3 budgeted auto-execute; set and enforce cost ceilings.
- Add more surfaces (builder ADA/SEO linting, performance fixes, proactive support outreach).
- Publish quarterly agent contracts with target KPI lifts and budget bands.
What to measure (and show)
- Time-to-value: days from “intent defined” → “agent shipping.”
- Coverage: % of top intents addressed; % executed within policy without human approval.
- Business impact: time-to-publish, conversion/AOV, CSAT/FCR, deflection, stockout days; incremental revenue or cost/case delta.
- Safety & cost: incidents per 1k actions, rollback rate, cost/action vs. budget, tenant-isolation test passes.
These metrics make agents visible to executives and defensible to risk teams.
Bottom line: Agentic AI will transform web presence, but not through single, flashy assistants. Scale comes from the unglamorous discipline of LLM-powered knowledge operations, MCP-hardened tools, and KPI-first measurement—and from the willingness to ship in phases, listen to users, and let feedback tune the system. Embrace that operating model, and “from copilots to autonomous outcomes” becomes a sober, defensible path,not a slogan.



