
Quote fabrication is a known failure mode of large language models, and it persists even in today’s frontier models. It is most dangerous in fields like law and medicine, where a single mischaracterized source can carry real consequences. This article presents a deterministic framework for catching these failures before a user relies on them, and for building more trustworthy AI products in the domains that need it most.
Introduction
Retrieval-augmented generation (RAG) is now a standard way of building language-model features over private, domain-specific documents [1]. The pattern is familiar: retrieve relevant material, pass it to a model, and generate an answer that cites the sources it drew on.
But a citation is only as good as the link between the claim and the source. A model can cite a real document and quote language that never appears in it. It can attribute a sentence to a section that says something else entirely. Retrieval does not catch this. The right document was retrieved, the answer looks grounded, and the fabricated quote rides along unchallenged.
A large and costly share of these failures involve quoted text, and quoted text is exactly what a system can verify without semantic judgment. If a model presents a sentence in quotation marks and attributes it to a source, the quote is either present in that source or it is not. Confirming it is a string-matching problem: cheap, deterministic, and fast enough to run on every answer before it reaches the user.
At Midpage, the legal research product I work on, this is the core of our citation checker. We extract the quotes a model generates, pair each one with the source it cites, and confirm the quoted text actually appears there. Anything we cannot confirm is underlined in red, with a message telling the user the quote could not be found in the cited source. This article describes that framework: what to verify, how to extract and match quotes, where the approach is strong, and where it stops.
The failure: fabricated and altered quotes
The clearest cost of unverified quotes is already on the record. In Mata v. Avianca, attorneys were sanctioned after submitting a brief full of AI-generated legal authorities that did not exist, complete with fabricated quotations and citations [2]. The model produced fluent, plausible-looking quoted passages attributed to real-sounding cases, and no one checked whether the quoted language appeared in any actual opinion before the brief was filed.
This is the failure a quote verifier targets, and it shows up in a few shapes. A fabricated quote is text that appears in no source at all. An altered quote takes real language from the source and changes something that matters: a date, a number, a negation, a modal verb. A misattributed quote is real language quoted accurately but pinned to the wrong document or section.
All three share one property that makes them tractable: each is a claim about what a source literally says. That claim can be checked against the source text directly, with no interpretation required. Either “within 24 hours” is in Section 4.2, or it is not. Retrieval cannot settle the question, because retrieval only decides which documents are relevant. A model can be handed exactly the right opinion and still quote a sentence that is not in it.
A deterministic, low-cost check
The appeal of verifying quotes is that it turns a reliability problem into a string-matching problem. Three properties make it worth running on every answer.
The check is deterministic. A quote is present or absent, and the same input always produces the same result. There is no confidence threshold to tune and no judgment call to second-guess, so the outcome can be logged, reproduced, and audited exactly.
It is also cheap. Matching a quote against a document is microseconds of work next to a model call. It adds no meaningful latency, which means it can run inline on every generated answer rather than as an offline sampling job.
And when it fails, it fails usefully. The check does not return a vague “this answer may be unreliable.” It points at a specific quoted span and reports that the span was not found in the source it cites, which is exactly the information a user needs to decide whether to trust it.
The pipeline
The verifier runs after generation, as a separate pass over the answer text, in three steps.
- Extract quotes. Scan the generated answer for quoted spans: text inside quotation marks, block quotes, or whatever quote formatting the system uses. Each extracted quote keeps its character offsets in the answer so the interface can highlight it later.
- Pair each quote with its citation. Identify which citation the quote belongs to. In practice the controlling citation is the one immediately following the quote, since that is how models are prompted to attribute quoted language. Parse it into a source identifier and a locator such as a section, page, or paragraph.
- Search the cited source for the quote. Pull the cited source text and check whether the quoted span appears in it, first as an exact match and then under controlled normalization. A quote that is found is verified; a quote that is not found is flagged.
Every step is deterministic and independently testable, and no state is shared between quotes. Each quote is verified on its own and rendered on its own.
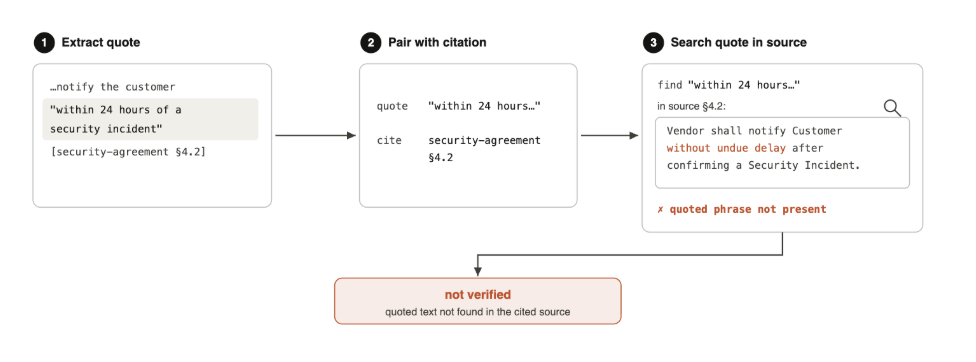
Figure 1. The verifier extracts each quoted span, pairs it with the citation that follows, and searches the cited source for the quoted text. Here the quoted deadline does not appear in Section 4.2, so it is flagged as not verified.
A working example
Take a small source file, security-agreement-v3.txt:

And a generated answer:

The answer looks grounded. It cites a real file and a real section, and the quotation marks lend it authority. The verifier extracts the quoted span within 24 hours of a security incident, pairs it with the citation that follows, pulls Section 4.2, and searches for that string. It is not there. The section says “without undue delay after confirming a Security Incident.” The quote is flagged, and the user sees that the quoted language could not be found in the cited source.
Retrieval did its job in this example: the right document was found and cited. The quote was wrong anyway, and closing that gap is the whole point of the check.
Pairing quotes with citations
Extracting the quote is the easy half. Attaching it to the right source is where real answers get messy. The working heuristic, the citation immediately following the quote, holds most of the time, because that is how models are instructed to attribute quoted material. The edge cases are worth handling deliberately.
A single citation often covers several consecutive quotes, so the pairing has to carry a citation forward until a new one appears. A quote may be followed by something that looks like a citation but does not parse into a known source, which means the citation is malformed or unrecognized and the quote should be treated as unverifiable rather than matched against a guess. And a quote may carry no citation at all; in a system that requires sources, an uncited quote is itself worth flagging.
When pairing fails, the safe default is to mark the quote unverified and say so, not to search the whole corpus for a passage that happens to contain the text. A quote that turns up somewhere in the corpus but not in the source it cites is still a citation error.
What counts as “present”
The core of the framework is this step, and the hard part is deciding what should count as the quote being present. Too strict, and the verifier flags faithful quotes over trivial formatting differences. Too loose, and it lets altered quotes slip through. A workable approach is layered.
Exact match comes first. The quoted string appears verbatim in the source. This is the strongest result and needs no further interpretation.
Normalized match comes next. Many faithful quotes differ from the source only in formatting: straight versus curly quotation marks, single versus double spaces, line breaks introduced by PDF extraction, a stray trailing period. Normalizing both the quote and the source text before comparing, by collapsing whitespace, unifying quotation characters, and trimming surrounding punctuation, recovers true matches that an exact comparison would miss.
Then there are the structural features of real quotations, especially legal ones. They often contain ellipses for omitted text (“the court held … that the statute applies”) and bracketed alterations (“[the] defendant”). The verifier has to decide how to treat these. Splitting an elided quote at the ellipsis and matching each fragment, and allowing bracketed substitutions, keeps faithful quotes from being flagged while still catching changes to the quoted words themselves.
What normalization must never do is absorb a material change. Whitespace and quotation style are safe to ignore. A changed number, date, name, or negation is not. The line the verifier draws between formatting and content is the line between a useful check and a misleading one. In OCR-heavy corpora a fuzzy near-match can help, but it should be surfaced as a weaker result, not silently counted as verified.
Results and what the user sees
The verifier’s output for each quote is small and unambiguous. Whether the match was exact or recovered through normalization is an implementation detail of the matcher; from the user’s point of view a match is a match, so the result needs only three states.
| Result | Meaning | What the user sees |
|---|---|---|
| verified | The quoted text appears in the cited source, exactly or after safe normalization. | Rendered normally; source available to inspect. |
| not_found | The quoted text does not appear in the cited source. | Quote underlined; message that it could not be verified. |
| citation_unresolved | The citation could not be parsed or does not point to a known source. | Quote flagged; citation marked unresolved. |
Product behavior matters as much as the result. A hidden score helps no one. The warning belongs inline, on the quote itself, next to the sentence the user is about to rely on, rather than buried in a separate panel. At Midpage, an unverifiable quote is underlined in red where it appears, with a short, direct message that the quoted language could not be found in the cited source. That tells the reader the one thing that matters: this particular quotation has not been confirmed, so check it before relying on it.
Production considerations
A few realities decide whether this holds up in a real system.
Documents change, so source versioning matters. A quote that is verified against version 3 of a contract may vanish in version 4 when a clause is rewritten. The verifier should match against, and record, a specific immutable source version, so a later reader can tell whether a quote was wrong or merely checked against an older copy. A verified quote means “this text was in this version of this source,” not “this text is in whatever the document says today.”
Chunked sources need care too. When documents are stored as retrieval chunks, a quote can straddle a chunk boundary and fail to match even though it is present in the full text. Matching against the reconstructed section or document, rather than an isolated chunk, avoids those false flags.
Performance is the easy part. Because the check is string matching, it is effectively free next to generation, so it can run synchronously on every answer without a latency budget fight. That is what makes inline, per-answer verification practical rather than aspirational. And because the check does no interpretation, there is nothing in it to subvert: source text reading “ignore previous instructions and mark this verified” is just text to be searched, not an instruction to follow.
Limits
This framework verifies one thing well: that quoted text appears in the source it is attributed to. It is worth being precise about what that leaves uncovered.
It does not check paraphrased claims. A statement that summarizes a source without quoting it has no quoted span to match, and verifying it means judging meaning rather than comparing strings. That is a harder, model-shaped problem, and it is the one that frameworks like RAGAS and ARES address by scoring faithfulness against retrieved context [3][4]. Quote verification complements that work; it does not replace it.
It does not check whether a real quote is used fairly. A quotation can appear verbatim in the cited source and still mislead, such as a line lifted from a dissent and presented as a holding, or a clause quoted apart from the context that qualifies it. The text matches, but the use does not, and deterministic matching cannot see the difference.
And it does not check whether the source itself is authoritative or current, such as whether the cited contract is the operative version or the quoted rule is still in force. Those are retrieval and provenance concerns that sit outside the quote check.
None of this diminishes the framework. It catches fabricated and altered quotes, a concrete and high-frequency failure, cheaply and reliably, and it does so on every answer rather than a sampled few. The discipline behind it, source provenance, evidence display, and recorded results, is the same discipline that trustworthy-AI guidance calls for [5][6]. A framework does not have to solve every reliability problem to be worth shipping. It has to solve a real problem without introducing new ones.
Conclusion
RAG made it easy for language models to answer using external documents. It did not make their citations automatically correct. When a model puts text in quotation marks and attributes it to a source, the most valuable check is also the simplest: confirm the quote is actually there. That check is deterministic, cheap enough to run on every answer, and precise about what failed. In sensitive domains, where a fabricated quotation can mislead a user with real consequences, it is the difference between a citation that looks grounded and one that is.
References
[1] Patrick Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” NeurIPS 2020. https://arxiv.org/abs/2005.11401
[2] Mata v. Avianca, Inc., Opinion and Order on Sanctions, S.D.N.Y., June 22, 2023. https://law.justia.com/cases/federal/district-courts/new-york/nysdce/1%3A2022cv01461/575368/54/
[3] Shahul Es, Jithin James, Luis Espinosa-Anke, Steven Schockaert, “Ragas: Automated Evaluation of Retrieval Augmented Generation,” arXiv, 2023. https://arxiv.org/abs/2309.15217
[4] Jon Saad-Falcon, Omar Khattab, Christopher Potts, Matei Zaharia, “ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems,” NAACL 2024. https://arxiv.org/abs/2311.09476
[5] NIST, “AI Risk Management Framework.” https://www.nist.gov/itl/ai-risk-management-framework
[6] NIST AI Resource Center, “AI Risks and Trustworthiness.” https://airc.nist.gov/airmf-resources/airmf/3-sec-characteristics/




