

Key takeaways
- Financial institutions cannot rely on generic LLM answers—AI systems must retrieve trusted financial data before generating insights.
- Retrieval-augmented generation (RAG) pipelines combine structured financial datasets and unstructured research content to produce context-aware analysis.
- Strong data engineering practices—including document ingestion, embedding pipelines, and retrieval governance—are essential for reliable AI-driven financial research.
- Explainability and traceability are critical in finance; RAG systems must expose sources, lineage, and document references used in AI responses.
- Successful financial RAG architectures treat knowledge retrieval as a data platform problem—not just an LLM integration.
The growing role of AI in financial research
Financial analysts today operate in an environment where information moves at extraordinary speed. Investment decisions depend on a constant flow of market data, company filings, macroeconomic indicators, research reports, and news updates. While large language models (LLMs) have demonstrated impressive capabilities in summarization and reasoning, they also present a critical challenge for financial institutions: reliability.
For example, an analyst might ask: “What changed in management’s tone on net interest margin this quarter, and how does it compare to the last two calls?” A well-built RAG assistant won’t guess. It retrieves the latest earnings-call transcript, pulls the prior two quarters’ prepared remarks and Q&A, and (if available) grabs the bank’s guidance slide or 10-Q excerpt. Then it generates a comparison with citations.
General-purpose LLMs generate responses based on patterns learned during training rather than real-time financial knowledge. This can lead to outdated information or hallucinated answers—issues that are unacceptable in environments where investment decisions and regulatory obligations depend on accurate information.
As a result, many financial institutions are now experimenting with retrieval-augmented architectures that combine large language models with proprietary financial data sources. Instead of relying solely on pretrained model knowledge, these systems retrieve internal research reports, regulatory filings, market data, and analyst notes at query time. This approach allows institutions to deploy AI assistants that remain grounded in trusted financial information while maintaining transparency and traceability for analysts and risk teams.
That’s where retrieval-augmented generation (RAG) earns its keep. In practice, teams pair an LLM with a retrieval layer that can pull the right filings, transcripts, research notes, and internal content at query time—then ask the model to answer from that material. The result is an assistant that stays anchored to what your institution actually knows, not whatever the model happened to learn during training.
The data challenge behind financial research
Financial research workflows rely on a diverse ecosystem of information sources. Analysts frequently consult multiple types of content, including:
- Company filings and regulatory disclosures
- Broker research reports
- Earnings transcripts
- Market and trading data
- Macroeconomic datasets
- Financial news feeds
Unlike structured market data feeds, much of this information exists as unstructured documents—PDF reports, HTML filings, research notes, and internal memos. These documents often contain valuable insights but are difficult to query using traditional data systems.
Historically, analysts relied on manual search across document repositories and research databases. While effective, this process is time-consuming and does not scale well as the volume of financial information continues to grow.
RAG pipelines address this challenge by transforming large collections of financial documents into searchable semantic knowledge bases that AI systems can query in real time.
In practice, several large financial institutions are already experimenting with RAG-based research assistants. Internal knowledge platforms increasingly combine earnings transcripts, internal research notes, and regulatory filings into searchable semantic indexes. Analysts can query these systems with questions such as “What changed in management guidance across the last three earnings calls?” or “Which research reports discussed liquidity risks in commercial real estate this quarter?” Instead of manually searching across multiple research systems, the RAG pipeline retrieves relevant documents and synthesizes the insights while preserving links to the underlying sources.
What is a RAG pipeline?
At a high level, a RAG pipeline has two moving parts:
- Retrieval systems that search relevant knowledge sources
• Language models that generate answers using retrieved context
Instead of hoping the model “remembers” the right fact, the system goes and fetches supporting passages—then hands them to the LLM as working context. The model’s job becomes synthesis, not invention.
In finance, that usually means the answer is grounded in today’s filings, research, and market context—not generic training data.
Architecture of a financial RAG pipeline
In most shops, the RAG architecture looks less like a single “AI feature” and more like a small data platform: ingestion, parsing, embeddings, retrieval, and guardrails that keep the answers auditable.
Figure 1. Reference architecture for a financial RAG pipeline
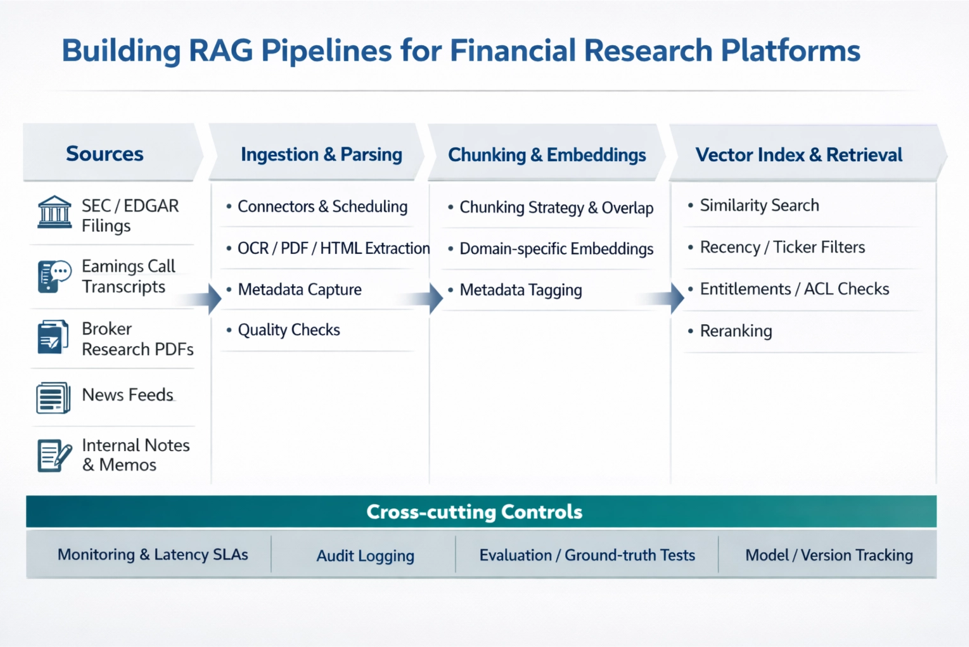
The architecture shown in Figure 1 illustrates the core components required to build a production-ready RAG pipeline for financial research platforms.
Document and data ingestion
The pipeline begins by ingesting research documents and financial datasets from multiple sources. These may include internal research repositories, regulatory filings, financial news feeds, and market data systems.
Document processing pipelines extract structured text from PDFs, HTML filings, and transcripts while preserving important metadata such as company identifiers, publication dates, and source attribution.
Maintaining this metadata is critical in financial applications, where analysts must verify the origin of every insight.
Document processing and embedding
After ingestion, documents are broken into smaller segments or “chunks.” Each chunk is converted into a numerical embedding using machine learning models designed for semantic similarity.
Embeddings allow systems to search documents based on meaning rather than simple keyword matching. For example, a query about “credit deterioration in commercial real estate” can retrieve research discussing loan performance or delinquency trends even if the exact phrase does not appear in the document.
This semantic retrieval capability is what enables RAG systems to function as intelligent financial knowledge platforms.
Vector search and retrieval
Embeddings are stored in a vector database that supports similarity search. When a user submits a question, the system converts the query into an embedding and retrieves the most relevant document segments.
For financial research platforms, retrieval pipelines must balance accuracy and latency. Analysts expect responses within seconds, but the system must also ensure that retrieved documents meet relevance and recency requirements.
Some organizations apply additional filtering during retrieval—such as restricting documents by asset class, company identifier, or publication date—to improve result quality.
Context construction and AI generation
The retrieved document segments are then assembled into a contextual prompt provided to the language model. The model generates a response using the retrieved content as reference material.
This approach significantly reduces hallucinations because the model is constrained by the supplied context. In financial applications, responses can also include source references that link directly to the underlying documents.
For example, an analyst asking about trends in mortgage-backed securities could receive a summary generated from recent research reports and market commentary while retaining direct links to the original sources.
Engineering challenges in financial RAG systems
While RAG architecture offers significant advantages, implementing them in financial institutions introduces several engineering challenges.
In many early deployments, teams discover that the biggest challenge is not the language model itself but the surrounding data infrastructure—document parsing quality, metadata management, and retrieval relevance often determine whether analysts trust the system’s answers.
Document quality and parsing
Financial documents often contain complex formatting, tables, footnotes, and embedded charts. Extracting high-quality text representations from these documents requires robust parsing pipelines.
Errors introduced during document extraction can propagate through the entire AI system, degrading retrieval quality.
If the text is messy, everything downstream is messy.
Data freshness
Financial markets evolve rapidly, and research insights can become outdated within days or even hours. RAG pipelines must support continuous ingestion of new documents and automated embedding updates to ensure that the knowledge base remains current.
Many organizations implement incremental ingestion pipelines that process new research reports and filings as they arrive.
Retrieval accuracy
Effective retrieval depends heavily on embedding quality and chunking strategies. Document segments that are too small may lose context, while segments that are too large may dilute semantic precision.
Balancing these factors is a critical design decision in financial RAG systems.
Governance and explainability
Governance is where most financial deployments get real. Risk, compliance, and audit teams will ask the same question your analysts should: “Where did this answer come from?”
RAG pipelines must therefore maintain:
- Document lineage and metadata
- Audit logs for retrieval and inference
- Source attribution in generated responses
With clear references and logs, analysts can click through, verify, and move on with confidence.
Emerging trends in financial AI knowledge systems
As teams move past pilots and into production, the focus shifts from “can we demo this?” to “can we run this safely every day?” A few patterns show up again and again.
One is blending structured datasets with document retrieval. When the assistant can pull both a paragraph from a credit memo and the latest exposure numbers or risk metrics, the output becomes more than a summary—it becomes analysis.
Another is using embedding models that speak “finance.” Teams find they get fewer irrelevant chunks back because the model understands things like covenant language, guidance ranges, and sector-specific terms.
Another important development is the integration of RAG pipelines with enterprise data and analytics platforms. When RAG sits next to your lakehouse/warehouse, entitlements, and monitoring, you can treat it like any other production system—with SLAs, controls, and observability.
Conclusion
AI can absolutely speed up financial research—especially the grunt work of finding, reading, and cross-referencing documents. But the value only shows up when the answers are reliable.
RAG is a practical way to get there. You let the system retrieve authoritative content—filings, transcripts, research, and internal notes—and you have the model write the answer using that context. Fewer hallucinations. More transparency.
For institutions that want to deploy AI responsibly, the hard part isn’t “hooking up an LLM.” The part that breaks first is usually data: ingestion quality, retrieval relevance, permissions, and auditability. Treat RAG like knowledge infrastructure, invest in those basics, and the assistant becomes something analysts can trust in daily workflow.
Author bio
Deepak Saxena is a data engineering and AI practitioner specializing in financial analytics platforms, distributed data systems, and AI infrastructure for financial intelligence systems. His work focuses on building scalable data pipelines, machine learning platforms, and knowledge systems that enable data-driven decision making in financial markets.
