
— For years, the AI industry operated under a brute-force consensus:more data equals a better model. Silicon Valley and global tech hubs raced to scrape, hoard, and process petabytes of raw internet text, pixels, and sensory outputs. But as the industry transitions from broad foundational models to specialized, domain-expert AI, that consensus is breaking.
Today, massive, noisy datasets are no longer a competitive advantage. They are an operational bottleneck, plagued by escalating costs, hallucinations, and diminishing returns. The future belongs to compact, highly optimized frontier models trained on high-fidelity, vertical data. At Alaya AI, we have built a closed-loop data production relationship engineered precisely for this shift. By unifying a proprietary AI Auto-Labeling Toolset with a deeply vetted, domain-expert In-House Team, we are redefining how premium enterprise AI datasets are born. Here is why high-fidelity vertical data is the new AI oil, and how a hybrid automated/in-house pipeline unlocks it.
1. Quality Over Quantity: The Math Behind Clean Data
When training specialized AI—whether a medical imaging diagnostic tool, an autonomous driving network, or a decentralized finance agent—a smaller, pristine dataset consistently outperforms a massive, uncurated bulk database.
Large, scraped datasets suffer from a high signal-to-noise ratio. They introduce conflicting labels, systemic biases, and corrupt file inputs that force engineers to waste computational power correcting training errors. Conversely, mathematically precise, verticalized datasets act as a superpower for neural networks:
• Lower Compute Costs: Models converge significantly faster when training on high-fidelity tokens, saving millions in GPU expenditures. • Higher Precision at Scale: Eliminating noise directly reduces the “hallucination threshold,” creating an enterprise-grade model that a bank, hospital, or legal firm can actually trust.
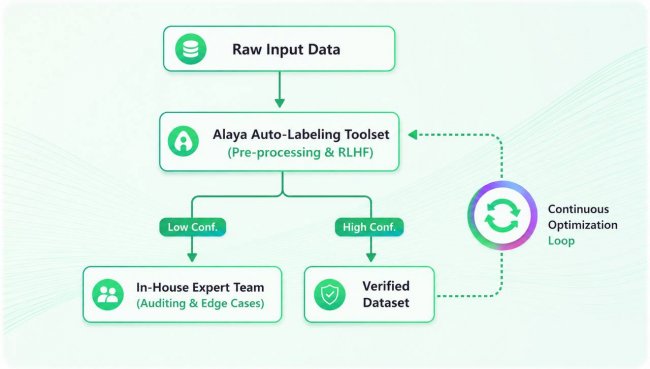
2. The Alaya AI Engine: Bridging Auto-Labeling Architecture and Human Intelligence
Achieving true high-fidelity data at scale requires a delicate technical balance. Pure manual labor is too slow and cost-prohibitive; pure algorithmic auto-labeling struggles with the nuance of highly specialized edge cases.
Alaya AI solves this through a robust, hybrid workflow that turns the data production relationship into an optimization loop:

Phase A: AI Auto-Labeling Acceleration
Our proprietary toolset utilizes multi-layer architecture to handle the heavy algorithmic lifting. It ingests complex multi-modal data and applies intelligent pre-processing—including automated data cleaning, deduplication, and zero-knowledge encryption (ZK-encryption) for secure processing.
By applying an advanced optimization mechanism based on Reinforcement Learning from Human Feedback (RLHF), our auto-labeling toolset instantly structures visual, text, and sensory data, achieving an automated verification rate of over 80%. This accelerates traditional manual workflows by 3 to 5 times.
Phase B: The In-House Guardrails for High-Fidelity Validation
What happens to the remaining 20%? This is where the long-tail demand of vertical AI becomes highly complex. Algorithms fail when confronting highly specialized, ambiguous, or never-before-seen edge cases.
Instead of relying on unvetted crowdsourcing for critical enterprise tasks, Alaya AI deploys its dedicated in-house labeling team. Composed of domain experts—ranging from technical engineers to language and visual specialists—our in-house team acts as the ultimate truth layer.
• Rather than clicking boxes from scratch, our internal team acts as expert verifiers and auditors, refining and correcting the automated outputs of our toolset. • They dissect micro-nuances, legal compliance anomalies, and domain-specific edge cases that automated models miss.
3. Real-World Complexity: Multimodal & Secure Infrastructure
High-fidelity data isn’t just clean; it is structurally complex. As AI agents become autonomous, developers require interconnected data pipelines—such as syncing telemetry data with real-time video feeds or auditing spatial data alongside complex financial transactions.
Through our unified architecture, Alaya AI ensures that every high-fidelity dataset is delivered with end-to-end cryptographic integrity. By anchoring our open Web3 data infrastructure with decentralized capabilities, we provide an immutable audit trail for enterprise clients. Data lineage is fully transparent, and privacy boundaries are rigidly maintained, meeting the most rigorous global compliance standards.
Conclusion: Refining the Future of AI
The race for digital supremacy is no longer about who can accumulate the largest pile of digital scrapings. It is about who can refine the purest, highest-yield digital fuel.
By marrying our high-throughput AI Auto-Labeling Toolset with the elite precision of our In-House Team, Alaya AI doesn’t just process data—we architect the clean foundational layers that next-generation autonomous intelligence requires. To explore our dynamic task allocation, open data platform, and technical architecture, read through our full documentation on our GitBook and join the ecosystem conversation on X (@Alaya_AI).

Contact Info:
Name: Alice
Email: Send Email
Organization: Aialaya
Website: https://www.aialaya.io/#/
Release ID: 89192589
If you detect any issues, problems, or errors in this press release content, kindly contact [email protected] to notify us (it is important to note that this email is the authorized channel for such matters, sending multiple emails to multiple addresses does not necessarily help expedite your request). We will respond and rectify the situation in the next 8 hours.
