

The semiconductor industry has long been guided by Moore’s Law, which observed that the number of transistors on a microchip doubled approximately every two years. This prediction shaped technological development for nearly six decades, driving the computing revolution from mainframes to smartphones.
Today, we’re witnessing a similar phenomenon in artificial intelligence. Three emerging “laws” are now shaping the trajectory of AI development, particularly for large language models (LLMs) and generative AI. Understanding these principles is important for anyone looking to navigate the AI landscape, whether you’re developing AI solutions or integrating them into your business strategy.
The Foundation: From Moore to More Parameters
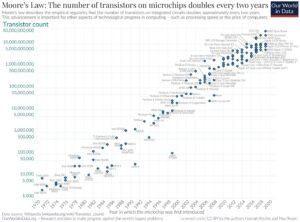
Gordon Moore’s simple observation in his 1965 paper “Cramming More Components onto Integrated Circuits” became the driving force behind the explosive growth of computing power. Today’s AI revolution builds on this foundation but follows its own evolutionary path.
In 2020, researchers at OpenAI published a seminal paper, “Scaling Laws for Neural Language Models”, which has become known as the Kaplan Scaling Laws. This research identified three key variables that determine AI language model performance:
- Number of parameters in the model
- Size of the training dataset
- Compute required for training
The Kaplan Scaling Laws suggested that for every parameter in a model, you need about 1.7 text tokens in your training data. This insight provided the roadmap for creating increasingly powerful language models and helped explain why larger models like GPT-3 demonstrated capabilities that seemed almost magical compared to their predecessors.

While parameter count initially dominated discussions about model capability, the industry has since evolved beyond this single metric. As reasoning capabilities have become central to model performance, the focus has shifted to more nuanced measures of AI capability rather than simply scaling up model size. This evolution reflects a maturing understanding of what truly drives AI performance.
Chinchilla’s Optimization: Quality Over Quantity
While Kaplan’s laws suggested that bigger was always better, researchers at DeepMind uncovered a more nuanced picture in 2022. Their paper, “Training Compute-Optimal Large Language Models”, introducing the Chinchilla model revealed that many existing models were actually “undertrained” – they had too many parameters relative to the amount of training data used.
The Chinchilla (or Hoffman) Scaling Laws suggested that for optimal performance, you should use about 20 tokens of training data per parameter – a significant increase from Kaplan’s 1.7 ratio. This insight changed the understanding of what makes language models effective.
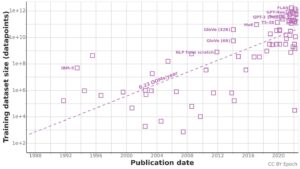
The practical implication was significant: a smaller model trained on more data could outperform a larger model trained on less data, even when using the same amount of compute resources. This finding challenged the assumption that only companies with the resources to build ever-larger models could compete in the AI race.
Mosaic’s Law: The Democratization of AI
Just when it seemed that AI development might become the exclusive domain of tech giants, a third trend emerged. Naveen Rao, former CEO of MosaicML (now VP of GenAI at Databricks), observed what he called “Mosaic’s Law”:
“A model of a certain capability will require 1/4 the [money] every year from [technological] advances. This means something that is $100m today goes to $25m next year goes to $6m in 2 years goes to $1.5m in 3 years.”
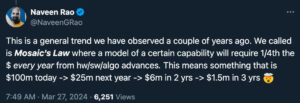
This observation is supported by research published in the paper “Algorithmic progress in language models,” which found that the compute required to reach a set performance threshold in language models has halved approximately every 8 months since 2012.
Mosaic’s Law suggests that while the cost of cutting-edge AI models may be skyrocketing, the cost of producing models with a given level of capability is rapidly decreasing. This trend could democratize AI development, allowing smaller players and open-source projects to remain competitive.
We’re now seeing this democratization in full effect. DeepSeek’s release of their R1 reasoning model as completely open source earlier this year demonstrated that impressive benchmark results can now be achieved at a fraction of the cost that would have been required just years earlier. Similarly, models like Qwen and Google’s Gemma have made high-capability AI accessible to a much wider community of developers and researchers.
These developments have shifted the conventional wisdom around model development. Just a few years ago, many believed companies needed to build their own proprietary models to remain competitive. Today, the abundance of powerful open-source options has dramatically reduced this pressure, allowing organizations to focus on innovative applications rather than expensive foundation model development.
Business Implications: What These Laws Mean for You
These three laws have implications for businesses navigating the AI landscape:
Strategic Planning
Companies need to carefully consider whether to invest in developing proprietary AI models or leveraging existing solutions. The Chinchilla Law suggests that focusing on better data may be more valuable than simply building larger models, while Mosaic’s Law indicates that waiting for technology to mature can significantly reduce costs.
Competitive Dynamics
The rapid democratization of AI capabilities means that competitive advantages from AI may be shorter-lived than expected. Today’s cutting-edge capabilities will be widely available within a matter of months or years, not decades.
Resource Allocation
Organizations should consider allocating resources to data quality and quantity rather than just computing power. The Chinchilla findings suggest that high-quality, diverse training data may be the most valuable asset in AI development.
Innovation Strategy
For smaller players, these laws provide a roadmap for innovation. Rather than competing on raw model size, companies can focus on specialized datasets, novel training approaches, or innovative applications of existing models.
The Future Landscape
As with Moore’s Law before them, these principles are not immutable laws of nature but rather observations of current trends. They may evolve or be superseded as the field advances. However, they provide valuable guideposts for navigating the rapidly evolving AI landscape.
The interplay between these three laws creates a dynamic ecosystem. While the largest companies push the boundaries with ever more powerful frontier models, these advancements quickly become accessible to smaller players and the open-source community.
This pattern of innovation and democratization promises to accelerate AI development across all sectors of the economy. Understanding these scaling laws isn’t just academic—it’s essential for making informed strategic decisions in a world increasingly shaped by artificial intelligence.


