AI systems have moved into mainstream business operations, with organizations now expecting tangible improvements in efficiency, risk control, and decision-making quality. Despite rising interest in computer vision and generative models, most enterprises struggle to move from pilot to production because of challenges with data integration, infrastructure, and reliability.
The true differentiator between research prototypes and enterprise-ready AI is the ability to handle real business data and workflows. Drawing from field deployments across large enterprises, I’ll share practical lessons that help teams deliver results at scale using vision and natural language processing (NLP) models.
Real-World Technical Challenges of Deploying AI at Enterprise Scale
AI adoption is rapidly becoming routine, but scaling these systems presents persistent technical and organizational hurdles. According to McKinsey’s 2024 survey, 65% of organizations now report regular use of generative AI, nearly double last year’s figure.
However, different business units maintain their own formats, policies, and tools. This creates friction when models need up-to-date, unified data. The same analysis reveals that 70% of high-performing organizations struggle to define governance, rapidly integrate new data, and obtain sufficient high-quality training data.
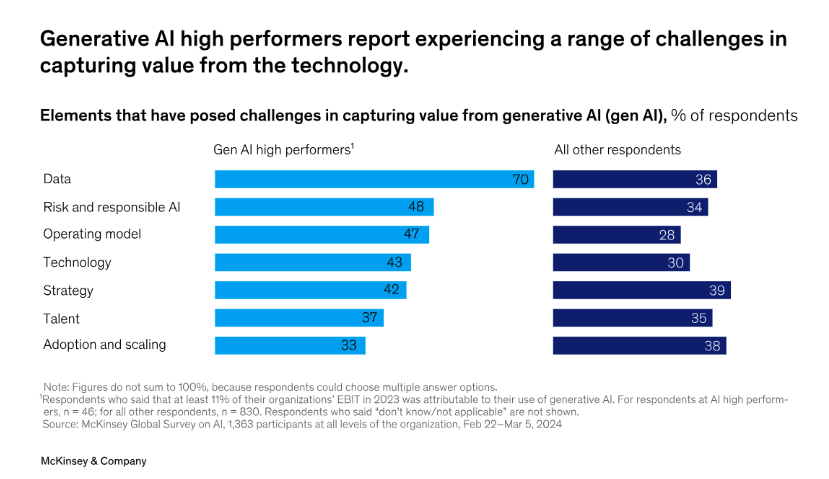
High performers have encountered other challenges in capturing value from GenAI.
Moving computer vision from lab to production goes well beyond technical upgrades. Embedding video analytics or multimodal models often requires redesigning ETL processes to handle continuous ingestion, error handling, and validation. In my experience, standardizing ETL with AWS Glue and Databricks improved latency and reduced data quality issues, even when incoming data was inconsistent.
Greater use of AI also raises the stakes for privacy, audit, and access control. Multi-tenant environments and regional regulations require organizations to establish clear policies regarding data usage and sharing. Developing and automating these controls takes sustained alignment across data science, IT, and compliance functions.
Evolution from Rule-Based Systems to Neural Architectures
Rule-based computer vision models use fixed rules, such as tracking certain colors or shapes. These rules quickly fail if conditions change. Neural networks, particularly those based on transformer models and convolutional structures, can adapt as conditions shift.
Modern models, such as YOLOv5, utilize efficient one-stage architectures for real-time detection, while advanced systems like CLIP and Vision Transformer for Open-World Localization (OWL-ViT) take things further. They match images with text, enabling rapid identification of new categories with minimal retraining. OWL-ViT’s vision transformer processes image patches, mapping each to potential objects and dynamically adapting to new tasks.
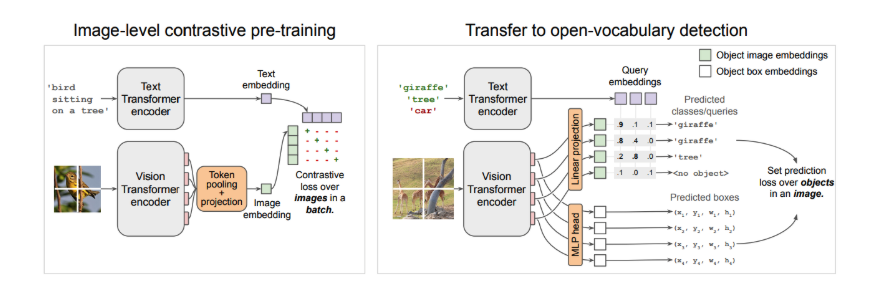
Overview of the OWL-ViT method
Source: Simple Open-Vocabulary Object Detection with Vision Transformers | Minderer et al.
These advances rely on a strong data infrastructure. Hybrid pipelines ensure computer vision and NLP systems remain accurate and responsive as requirements evolve, supporting model updates and scalability.
Infrastructure at Scale: From Feature Stores to Streaming Inference Pipelines
Deploying AI requires connecting models with relevant data and workflows. Infrastructure design matters as much as model performance. Feature stores manage model inputs, reducing the need for repeated data engineering work and supporting transparency. Tools like MLflow help teams document experiments, track model versions, and simplify governance.
For live use cases, streaming inference is critical. Data can be processed through AWS Lambda, with results stored in S3, or flow between services using Kafka, ensuring rapid responses to new events. These technologies enable AI to support operational decisions within seconds.
Rocket Companies’ migration to AWS serves as an example. Their architecture uses AWS Glue ETL for data refinement, SageMaker Studio for model development, and MLflow for cross-team deployment. Refined data is cataloged, secured via Lake Formation, and exposed for analytics and scoring in production. Automated triggers and CI/CD flows ensure that deployments are both responsive and reproducible.
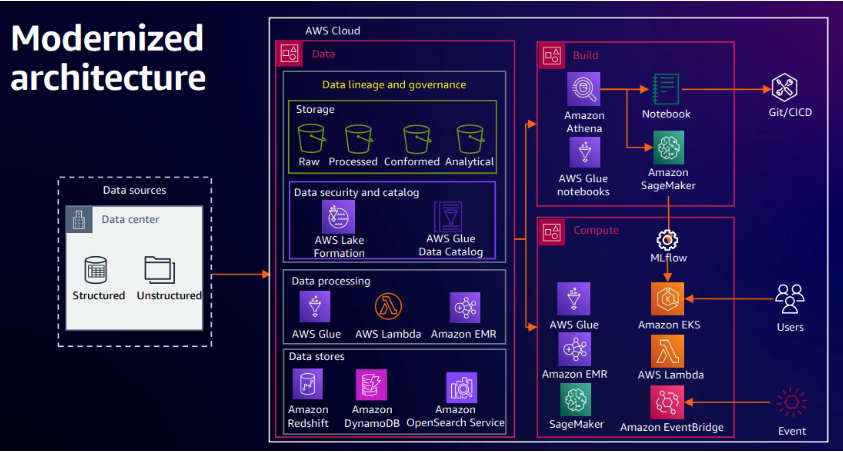
Rocket’s modernized data science solution architecture on AWS
Source: How Rocket Companies runs their data science platform on AWS | Amazon Web Services
Large organizations now favor hybrid stacks. Graph databases like Neptune handle complex relationships (like identity resolution), Snowflake simplifies data warehousing and sharing, and Databricks provides fast, flexible analytics. Using all three enables computer vision and language models to share data efficiently, process graph queries, and scale with demand.
Automating routine work, such as generating SQL in Snowflake, reduces manual errors and saves hours every week. This builds pipelines that adjust quickly to new business needs and track every step from data source to deployed model.
Balancing Accuracy, Latency & Maintainability in Production ML Systems
Reliable enterprise AI requires more than high accuracy scores. Speed, maintainability, and cost control are just as important. Delays in predictions can slow real-world workflows, such as live video monitoring or logistics routing. If a model drifts, unnoticed errors can accumulate in daily operations.
Model optimization turns complex systems into efficient tools. Several methods help manage resources and reliability:
- Distillation compresses large models into smaller ones, reducing resource demands.
- Quantization reduces the precision of model weights, such as when moving from floating-point to INT8. This accelerates predictions and supports edge deployment.
- Incremental learning allows models to adapt to new data without costly full retraining.
MLOps best practices tie these elements together. Airflow schedules retraining and batch jobs, while CI/CD systems automate deployment. Continuous monitoring via dashboards helps detect data shifts and anomalous outputs for timely review.
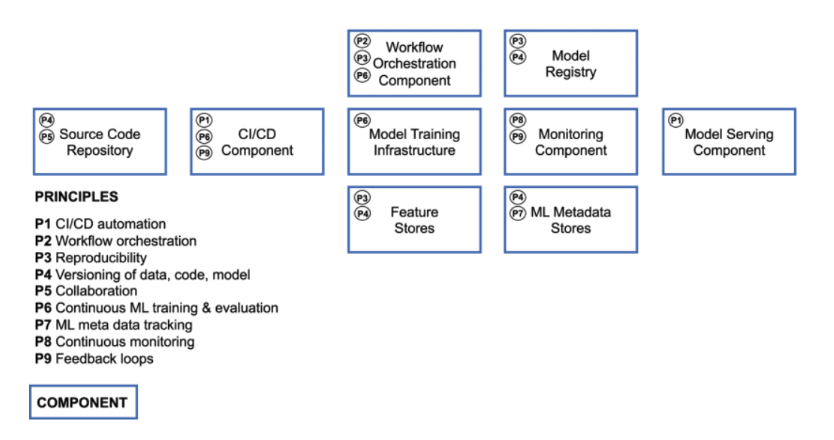
Implementation of principles within technical components
Source: Machine Learning Operations (MLOps): Overview, Definition, and Architecture | Kreuzberger et al.
Hyperparameter optimization is essential for production-grade systems. Search automation and experiment tracking help teams improve models quickly, with results that can be audited and reproduced.
Using discriminative models for anomaly flagging alongside generative models for explanation increases transparency in critical applications. This combination gives technical and business teams clearer insight into model behavior, especially for rare or changing events.
Data Privacy, Monitoring, and Human-in-the-Loop Feedback
Trustworthy AI starts with privacy controls. For video and multimodal workflows, each step, from collection to inference, needs clear data controls, regular review, and limits on data use. Ongoing monitoring for bias and model drift is necessary to limit risk and support regulatory review.
Human-in-the-loop (HITL) feedback adds another control layer. When a model is unsure, it refers cases to human reviewers. Each reviewed case then becomes new data for the pipeline, helping models learn from rare or shifting scenarios. This process builds a record of decision-making for compliance.
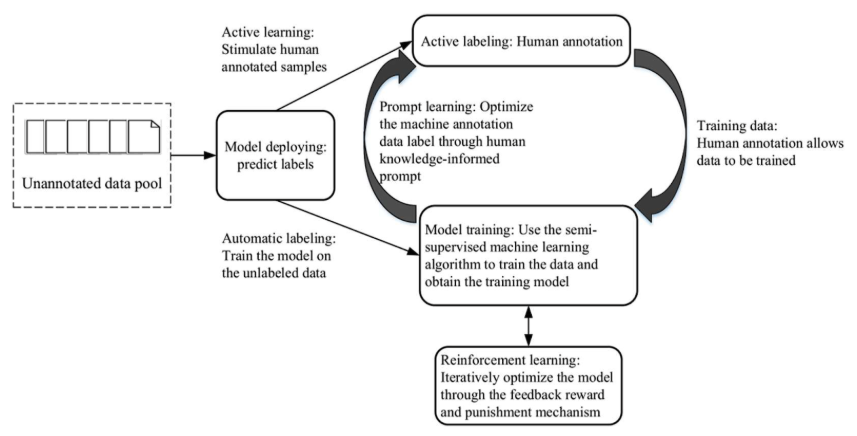
Human-in-the-Loop model for predicting data processing labels.
Source: Constructing Ethical AI Based on the “Human-in-the-Loop” System | Chen et al.
HITL systems typically involve scenario identification, annotation, reinforcement, and active learning. Teams identify key oversight cases, gather feedback, and combine human and model annotations. Models then learn from this combined input, with reinforcement and sampling targeting edge cases.
Clear governance frameworks and documented decision processes support risk management, compliance, and consistent monitoring. These controls are now a requirement for deploying AI at scale.
Future Outlook: Foundation Models & Multimodal Reasoning

Image: Multimodal Interaction with AI by Anderson P | Shutterstock
The adoption of foundation models is changing how enterprises approach decision support. Large vision-language models (VLMs) and retrieval-augmented generation (RAG) now handle images, text, video, and sensor data within the same workflow. This means teams can answer operational questions that draw on multiple data types, where older models struggled.
Multimodal reasoning allows a model to link patterns in video with written reports or sensor alerts. When AI connects text, visuals, and audio, organizations gain a clearer view of business activity. This delivers a more accurate and actionable picture of real-world events.
However, technical limitations remain. Large language models can handle broad visual tasks, such as sorting images or spotting general patterns, but often miss subtle details. Tasks like defect detection, image cleanup, or 3D reconstruction still rely on more specialized approaches.
Running these models requires significant resources, from hardware to ongoing oversight. The best results occur when foundation models are used for tasks that genuinely benefit from integrating different data types.
Final Thoughts: Building Lasting Value with AI
Scaling AI in enterprises requires more than larger models. Sustainable progress comes from clear data pipelines, reliable model operations, and strong connections between model builders and business users.
In my experience, the biggest improvements follow when companies invest in adaptable infrastructure and established MLOps processes. Reliable systems, hybrid pipelines, and effective human oversight help maintain compliance and trust as business demands evolve.
For organizations seeking tangible value, prioritize projects with direct links to business metrics and regularly review outcomes. When systems and workflows adapt along with the business, long-term value follows.
References:
- Singla, A., Sukharevsky, A., Yee, L., Chui, M., & Hall, B. (2024, May 30). The state of AI in early 2024: Gen AI adoption spikes and starts to generate value. McKinsey & Company. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai-2024
- Khanam, R., & Hussain, M. (2024, July 30). What is YOLOv5: A deep look into the internal features of the popular object detector. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2407.20892
- Minderer, M., Gritsenko, A., Stone, A., Neumann, M., Weissenborn, D., Dosovitskiy, A., . . . Houlsby, N. (2022, May 12). Simple Open-Vocabulary Object Detection with Vision Transformers. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2205.06230
- Tochukwu, N. (2023, March 14). Improve MLflow experiment tracking. MLOps Community. https://mlops.community/tracking-mlflow-experiments-historical-metrics/
- Xu, D., & Gupta, R. (2023, December 1). How Rocket Companies runs their data science platform on AWS. Amazon Web Services. https://d1.awsstatic.com/events/Summits/reinvent2023/ANT321_How-Rocket-Companies-run-their-data-science-platform-on-AWS.pdf
- Ozuysal, Y. (2024, July 15). Snowflake Copilot Now GA: A breakthrough AI-Powered SQL Assistant. Snowflake. https://www.snowflake.com/en/blog/copilot-ai-powered-sql-assistant/
- Mart, V. B., Kuzmin, A., Nair, S. S., Ren, Y., Mahurin, E., Patel, C., . . . Blankevoort, T. (2023, March 31). FP8 versus INT8 for efficient deep learning inference. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2303.17951
- Kreuzberger, D., Kühl, N., & Hirschl, S. (2023, March 27). Machine Learning Operations (MLOPs): Overview, definition, and architecture. IEEE Access, 11, 31866–31879. https://doi.org/10.1109/access.2023.3262138
- Chen, X., Wang, X., & Qu, Y. (2023, November 13). Constructing ethical AI based on the “Human-in-the-Loop” system. Systems, 11(11), 548. https://doi.org/10.3390/systems11110548
- Su, J., Jiang, C., Jin, X., Qiao, Y., Xiao, T., Ma, H., . . . Lin, J. (2024, February 15). Large Language Models for Forecasting and Anomaly Detection: A Systematic Literature Review. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2402.10350