Training large-scale models depends heavily on fast and reliable communication between GPU nodes. As workloads increase in scale, the performance of the underlying interconnect becomes just as crucial as the computing power itself. Transport protocols that enable Remote Direct Memory Access (RDMA) play a vital role in reducing latency, improving throughput, and ensuring efficient synchronization across systems.
The design of the interconnect fabric not only impacts throughput but also affects system reliability, the complexity of troubleshooting, and long-term scalability. Each design choice comes with trade-offs that influence how well the infrastructure can support demanding, distributed workloads.
Technology Overview
Each protocol enables RDMA over a distinct transport layer. Understanding their foundational differences helps clarify how they perform under load.
RoCEv2 (RDMA over Converged Ethernet v2)
RoCEv2 operates over routable Layer 3 Ethernet using the UDP/IP protocol. It enables low-latency communication in Ethernet-based networks, but requires a lossless fabric. This requires careful configuration of Priority Flow Control (PFC), Explicit Congestion Notification (ECN), and Datacenter Quantized Congestion Notification (DCQCN). When properly tuned, RoCEv2 can offer performance levels comparable to those of InfiniBand.
InfiniBand
InfiniBand was purpose-built for low-latency, high-throughput communication. It supports native RDMA, hardware-level flow control, and switch-based collective operations such as AllReduce through technologies like SHARP. InfiniBand operates on a dedicated fabric that uses its own topology and tooling. It provides consistent performance, although teams must maintain specialized infrastructure to achieve this level of performance.
iWARP
iWARP uses standard TCP/IP for RDMA transport. It relies on existing IP routing and implements IETF protocols such as RDMAP, DDP, and MPA. iWARP does not require a lossless network or any switch configuration. While simple to deploy, its reliance on TCP introduces higher latency and jitter, especially under network congestion or during retransmission events.
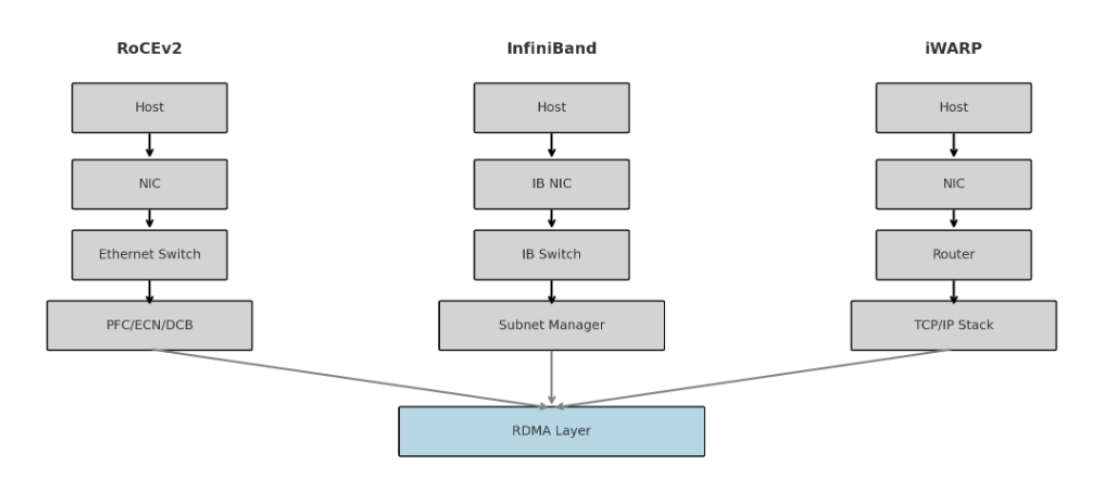
Image: Topology Diagram: RDMA Transport Architectures
Understanding the core design of each protocol helps clarify its trade-offs in real deployments. These architectural differences shape how each option performs under load, handles failures, and scales across infrastructure.
Protocol Comparison Table
The table below outlines the differences between RoCEv2, InfiniBand, and iWARP across key performance and operational dimensions relevant to AI infrastructure.
| Criteria | RoCEv2 | InfiniBand | iWARP |
| Latency and Jitter | Low latency with tuning. Jitter increases during congestion | Consistently low latency under load | Higher latency and jitter due to TCP stack |
| Congestion Control | Uses PFC, ECN, and DCQCN. HPCC is emerging | Hardware-level control with adaptive routing | TCP-based methods such as DCTCP or CUBIC |
| Collective Acceleration | Vendor extensions only. Not standardized | Supported via SHARP. Offloads collectives to switches | No hardware offload. Collectives run on CPU |
| Scalability | Scales with Ethernet. Complexity increases in large clusters | Built for scaling in dense fabrics | Scales over IP but performance drops with cluster size |
| Routing and WAN Support | Fully routable over Layer 3 UDP/IP. But need special consideration over existing WAN-TE when routing over WAN | Layer 2 native. Needs gateways for Layer 3 | Fully routable over TCP/IP. Suitable for WAN |
| Failure Recovery | Ethernet failover. Misconfigurations can spread faults | Hardware failover with isolated failure domains | TCP retries ensure delivery but increase latency under loss |
| Ecosystem Support | Broad OS and framework support. Requires tuning | Deep integration in high-performance compute stacks | Supported by OS. Limited support in model training frameworks |
| Operational Complexity | Moderate to high. Depends on tuning and monitoring | High. Requires specialized knowledge and management tools | Low. Fits easily into standard IP-based environments |
These differences directly influence deployment choices, especially when scaling, troubleshooting, or optimizing distributed training jobs.
Deployment Considerations
Beyond protocol specifications, practical deployment factors often determine success in production. The following sections highlight how each protocol behaves under real-world conditions, including configuration effort, performance consistency, and operational impact.
Network Configuration and Stability
RoCEv2 depends on precise network tuning. Incorrect ECN thresholds or misconfigured PFC can cause packet loss or head-of-line blocking. InfiniBand mitigates this risk by managing flow control in hardware, albeit at the expense of introducing a dedicated fabric layer. iWARP avoids switch-level configuration, offering resilience through TCP, but may see increased jitter or delays during retransmission.
Collective Operations
InfiniBand enables fast synchronization through switch-based collectives, reducing CPU usage. RoCEv2 provides partial support through vendor extensions but lacks a standardized solution. iWARP offers no hardware offload, and all collectives run on the host CPU. This limits performance at scale, especially for training workloads that involve frequent synchronization.
Failure Recovery
InfiniBand includes robust failover with fast path switching and isolated failure zones. RoCEv2 relies on standard Ethernet failover. Incorrect settings can cause congestion to spread across the network. iWARP maintains delivery through TCP retries, which ensures reliability but may delay recovery during high traffic or failure events.
Operational Complexity
InfiniBand introduces a distinct management layer with tools such as subnet managers and fabric monitoring systems. RoCEv2 utilizes standard Ethernet infrastructure but requires active management like PFC, ECN and DCQCN to maintain lossless behavior. iWARP is the most straightforward to operate and integrates well into environments that lack the resources for tuning or fabric management.
These considerations reflect the day-to-day realities of managing RDMA fabrics. A protocol’s value depends not just on performance, but also on how reliably and efficiently it operates in complex, scaled environments.
Ecosystem and Framework Integration
InfiniBand is widely supported across orchestration platforms and training frameworks. It integrates well with distributed training libraries and collective communication engines. Major frameworks also support RoCEv2 but may require tuning to optimize performance. iWARP works with most operating systems but receives limited optimization within distributed training ecosystems.
Evaluation Strategy
Protocol selection should be based on tested outcomes rather than vendor specifications. A structured evaluation process helps determine which protocol fits real-world workloads.
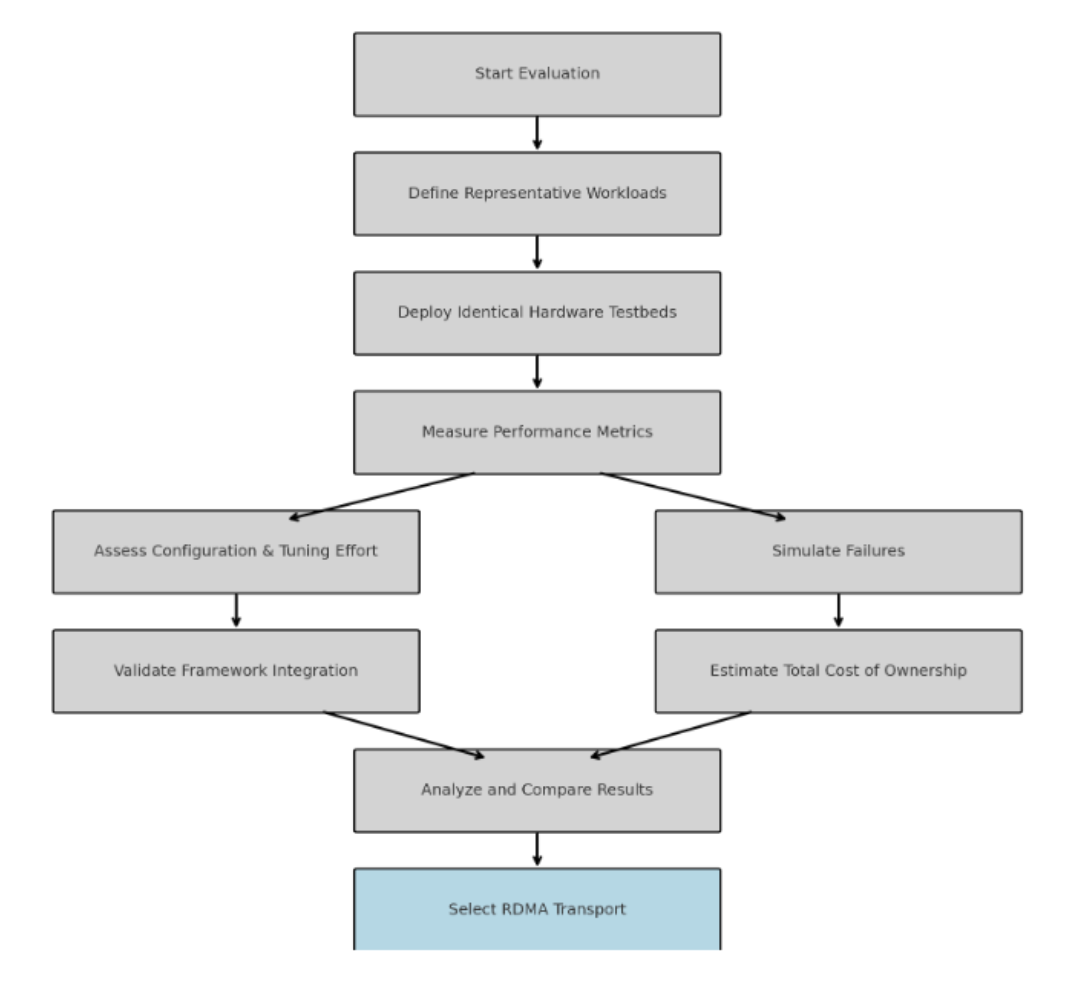
Image: Evaluation Strategy Decision Tree
- Define Representative Workloads: Include distributed training, image recognition, and tasks that require coordination and collaboration.
- Deploy Testbeds with Consistent Hardware: Use identical switches, NICs, and CPUs to ensure results reflect protocol behavior.
- Measure Key Metrics: Monitor latency, throughput, tail latency, jitter, and collective performance under load.
- Assess Configuration and Tuning Effort: Record setup time, troubleshooting steps, and required expertise for each protocol.
- Simulate Failure Events: Observe how each protocol handles link and node outages, as well as the speed of data path recovery.
- Validate Integration with Software Stack: Confirm support for orchestration platforms and training frameworks.
- Estimate Total Cost: Consider infrastructure costs, licensing, operational support, and training requirements.
A structured evaluation helps uncover limitations that are not visible in documentation. Real-world testing ensures the selected protocol meets both performance goals and operational expectations.
Deployment Guidance
This table summarizes which protocol aligns best with common infrastructure priorities and workload characteristics.
| Scenario | Recommended Protocol | Reasoning |
| Synchronized multi-node training | InfiniBand | Lowest latency and hardware collectives reduce iteration time |
| Ethernet-based infrastructure | RoCEv2 | Integrates with existing switching fabric and provides high throughput |
| WAN or distributed setups | iWARP | Fully routable and easy to deploy across geographically distributed nodes |
| Cost-sensitive or low-ops teams | RoCEv2 or iWARP | Reduces hardware and training overhead |
These guidelines should inform initial decisions, but hands-on validation remains essential before full-scale adoption.
Conclusion
Each protocol offers a different mix of performance, complexity, and integration effort. InfiniBand delivers reliable, low-latency communication with strong collective acceleration. It suits teams that need peak performance and are equipped to manage a separate fabric. RoCEv2 offers solid performance over Ethernet, provided teams can configure and maintain a lossless environment. iWARP focuses on ease of deployment and broad compatibility, but may not meet the performance needs of large-scale training clusters.
Final decisions should be made through structured evaluation under real-world workloads. Only actual testing reveals how each protocol performs under pressure and what it demands from operations teams. Benchmarks, failover testing, and tuning logs all contribute to a reliable decision-making process.