
About 750 million apps this year will use LLMs to automate about 50 percent of our work. But… deploying an LLM presents a number of engineering obstacles that can prevent it from reaching its potential: managing high-compute requirements; optimizing LLM inference costs; data pipeline scalability and latency concerns; and future-proofing infrastructure for next-gen models.
Managing high-compute requirements
GPUs for inference are typically underutilized by between 30 and 40 percent, despite the number of GPUs a company uses. This is primarily due to inefficient scheduling and workload distribution; poor monitoring and optimization tools; and underutilization of batch processing techniques.
Dynamic batching that supports GPU-level memory sharing and concurrent workloads can improve these metrics, thereby significantly improving utilization and increasing throughput. During peak traffic, dynamic batching could be beneficial to improving GPU utilization.
Optimizing LLM inference costs
Due to their model size, the time it takes for the infrastructure to initialize and allocate resources, LLMs can take several minutes to load on the initial request, leading to increased costs. One client we worked with saw a spike in latency from 15 seconds to two minutes during peak traffic, because their cold starts were not optimized, ultimately providing them with a poor user experience.
This time to first token (TTFT) is a crucial metric for evaluating LLM responsiveness, especially in interactive applications. Traditional model loading frameworks are not an effective fix; CPUs are not designed for heavy machine learning workloads, as they cannot handle large datasets or models. When tasked with workloads outside of their capabilities, CPUs generate high model load times. Additionally, moving model weights to CPU memory from the cloud or other storage mechanism to the GPU memory is cumbersome and a prolonged process.
Finally, it’s important to equip resources like GPU memory, download containers and establish conditions in scalable AI environments prior to the model being loaded. This process can add several minutes to startup times.
An effective fix is a built-from-scratch load balancing service optimized for GPU workloads. Working with providers like Amazon Web Services or Google Cloud can be particularly beneficial for companies that experience spiky workloads.
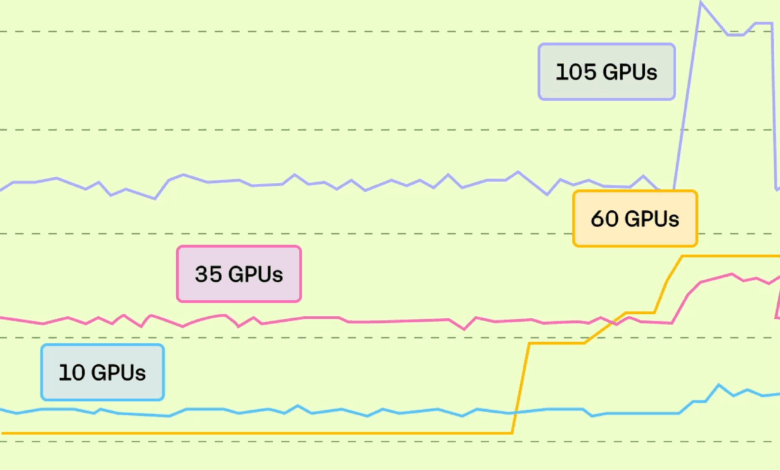
Above: a representation of how companies scale GPUs
Even when a business develops open source models, costs increase with scalability if tokens per second (TPS) isn’t optimized; if model optimization techniques are not leveraged; and if they have not projected budget for GPU needs.
Further compounding the issue is underutilization. Much of a system’s infrastructure remains idle waiting for traffic, especially with overprovisioning for worst-case latency. Quantization techniques can increase throughput by lowering the precision of the numbers used to represent the model’s parameters. But GPU hours remain unutilized when requests are spiky, an issue echoed by between 60 and 70 percent of the companies we’ve spoken with.
Batching helps, but it introduces latency tradeoffs. By waiting too long to batch, UX degrades, and the absence of batching burns compute for partial loads.
Finally, the model choice itself affects cost. GPT-4 or Llama-70B, for example, are used even when a small, customized model would suffice for 90 percent of the job. Replacing closed source models with fine-tuned Gemma can cut inference cost by ~18x with only a two to three percent dip in accuracy.
Latest models need more memory
Compounding the problem is that the latest open source models (e.g. Mixtral, DeepSeek-V2) often require 40 to 80GB of VRAM, while most inference systems were built for 7B/13B models.
As such, there is an increased need to serve 70B parameter models, but none of the traditional inference infrastructures built for 7B/13B can manage this easily.
The solution for deploying large models is to build an infrastructure around model sharding – dividing a large model into smaller, more manageable pieces and distributing these shards across multiple devices or machines – and model parallelism, which encompasses various strategies for distributing parts of a model across multiple devices to perform computations in parallel.
Data pipeline scalability and latency concerns
Before an AI model can actually “think” and provide a response, the raw input must be preprocessed to clean and prepare it. This includes, for example:
- Breaking a sentence into tokens (like splitting a sentence into words or word pieces)
- Filtering out extra noise, including unusual characters or empty spaces
- Formatting it into a structure the model understands
- Embedding it – turning it into numbers so the model can process it
This poses a problem, however. All of this happens before the model can start generating a response, and it is often done using Python code that runs step-by-step (serialized) and uses your CPU, not your GPU. What does this mean?
- It’s slow, especially if many users are sending requests at once.
- It can become a bottleneck, making the whole system feel laggy.
- Even if your model is super fast, you still have to wait for the preparation to complete.
Further compounding these issues is that Python language is single-threaded; it does only one thing at a time. It is not built for speed, and it uses more memory.
One team was spending more time cleaning and chunking docs than actually running inference, adding an average of about 600 milliseconds delay per request.
Additionally, infrastructure systems are not designed for scale; the technology works well at 10 to 20 queries per second, but when queries per second reach 10,000, issues arise. One startup built an internal search assistant using RAG and LangChain; it collapsed during a spike in demo day traffic, and the company had to re-architect everything.
Future-proofing infrastructure for next-gen models
How can businesses remain ahead of the curve when it comes to inference?
First, avoid designing an infrastructure that is closely tied to the model version. It can be difficult to switch models when new, improved ones are introduced. One team we worked with built everything assuming 4-bit Llama 2. When they tried to switch to Mixtral, they had to re-implement tokenizers, attention layers and even the basic scheduler, which cost them three weeks of additional work and thousands of dollars.
Systems like vLLM or NVIDIA Triton help decouple model logic from serving infrastructure, especially for streaming, batching or tensor parallelism.
Another way to futureproof scalability is to plan GPU architecture compatibility ahead of time; next-gen models may need FP8 or newer compute kernels (hello H100s, B100s), which can restrict usage if using A10s or T4s.
Finally, when models get bigger, token latency spikes, memory fragments and other issues arise. Without good tracing/logging on token throughput, GPU utilization and queue length, debugging becomes trial-and-error. Teams that add Prometheus/Grafana on top can future-proof the deployments. It behooves businesses to invest in observability from day one.
The bottom line
By managing their high-compute environments, optimizing inference costs, addressing concerns around scalability and latency and taking the appropriate steps to establish their infrastructure, businesses will be able to successfully deploy their LLMs and enable them to maximize their capabilities.



