
Published on 27.11.2025
If a data team spends every Monday morning fixing broken dashboards and missing files, the problem extends beyond a few buggy jobs. Each new source, schema change, or last-minute business request increases the likelihood of silent data issues, delayed reports, and last-minute firefighting. The traditional way of running pipelines simply does not keep pace with the volume, speed, and diversity of modern data flows.
Across industries and sectors, individual organizations already process tens of billions of records per day, with multi-petabyte monthly volumes becoming routine. Analytics and machine learning workloads move from overnight batches to near real-time decision support. Sources range from relational databases to event streams, document stores, and semi-structured APIs. Under that pressure, rule-based ETL stacks and hand-maintained scripts turn into brittle chains of dependencies. A single schema drift or malformed feed can cascade into outages across dashboards, models, and downstream services.
Many production environments combine commercial ETL platforms, workflow schedulers, SQL-based transformation layers, and both batch and streaming processing frameworks. Transformation logic resides in static mappings and procedural scripts accumulated over long periods. When a new source appears, a field changes type, or an upstream system alters its export formats, engineers adjust the transformation code, backfill historical data, rebuild analytical aggregates or feature stores, and document any incidents. Detection still often depends on downstream users noticing inconsistent numbers in dashboards. The mean time to resolution frequently spans hours or days, and engineering effort shifts from designing new functionality toward reactive incident handling.
A different pattern is now forming in practice: self-healing data pipelines. Instead of waiting for user-visible failures, pipelines monitor their own behaviour, detect anomalies in data and infrastructure, and automatically trigger remediation playbooks. Machine learning models track data quality and operational signals, distinguish normal variation from genuine incidents, and drive a blend of automated actions and guided interventions. The goal is not full autonomy, but instead controlled collaboration between humans and automation, where frequent, well-understood failures are resolved, allowing engineers to focus on developing new products and addressing high-risk changes.
The Technical Debt Spiral
The operational drag from fragile pipelines typically manifests in three areas.
First, detection happens late. Suppose the only monitoring consists of job success flags and a handful of high-level metrics. In that case, many issues surface only when downstream consumers compare independent reports or sanity checks and detect a discrepancy. By that point, dozens of processes may have already consumed corrupted data.
Second, remediation absorbs disproportionate effort. Engineers review logs, rerun jobs in a different order, and write one-off scripts to correct or delete affected records. Each new incident spawns another patch; very few lead to structural improvements across the platform.
Third, trust erodes. When numbers change without a clear explanation, teams begin to treat dashboards as advisory rather than authoritative. Data products lose influence, and the organization reverts to local extracts and spreadsheets, undermining the value of centralized platforms.
Self-healing architectures address these problems at their root by modifying how pipelines perceive themselves, interpret signals, and respond to failure.
Figure 1 schematically summarizes the main components of a self-healing data pipeline. Data sources feed an ingestion layer that writes into storage and analytical layers.
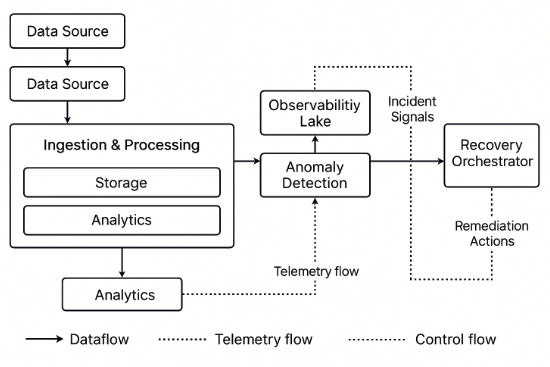
Figure 1. Self-Healing Data Pipeline Architecture Diagram
In parallel, the same jobs emit telemetry into an observability lake. An anomaly detection layer consumes this telemetry and produces incident signals, which are fed into a recovery orchestrator that executes parameterized remediation playbooks. The diagram distinguishes data flow, telemetry flow, and control flow.
Three Building Blocks Of A Self-Healing Architecture
Most practical self-healing designs incorporate three key elements: dense observability, intelligent detection, and controlled automation.
Figure 2 visualizes the interaction between dense observability, smart detection, and controlled automation as a feedback loop. Telemetry from data processing jobs feeds detection models, which emit incident classifications and confidence scores. These signals drive recovery actions whose outcomes are reported back into observability storage to refine detection logic and operational thresholds.
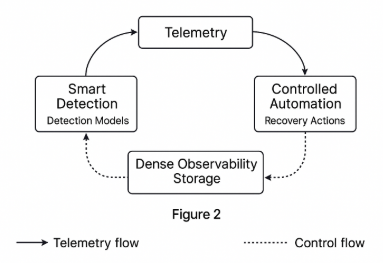
Figure 2. Diagram of the impact of self-healing on operational metrics
1. Dense Observability
Instead of sparse job logs, pipelines emit rich, structured telemetry. Alongside latency, throughput, and failure counts, they report:
- schema fingerprints and versions;
- record counts per partition and per source;
- distribution summaries for critical numeric fields;
- frequency profiles for categories;
- cross-system consistency checks.
All of this telemetry flows into an observability lake: a store of logs, metrics, and sampled data that later stages can consume in near real time.
2. Smart Detection
In addition to this telemetry, anomaly detection and drift detection models run continuously. Static thresholds give way to models that learn what normal behaviour looks like for a given pipeline, environment, or business cycle.
Several families of techniques are helpful in practice:
- unsupervised models that isolate unusual patterns in multivariate telemetry;
- autoencoders and reconstruction-error approaches that detect deviations from historical baselines;
- time-series forecasters that anticipate queue backlogs, latency spikes, or throughput drops;
- Data-quality detectors that watch missingness patterns, outliers, category shifts, and structural mismatches between incoming feeds and reference schemas.
When configured carefully, these detectors turn raw telemetry into actionable signals such as “unexpected duplication in jurisdiction X”, “schema drift in customer address fields”, or “anomalous error rate in a subset of serverless functions”.
3. Controlled Automation
Self-healing behaviour emerges once anomaly signals feed into the decision logic that chooses how to respond.
One common approach introduces a recovery orchestration layer. Detected patterns map to playbooks such as:
- replaying a specific partition with the corrected configuration;
- isolating corrupted batches and excluding them from downstream processing;
- switching read-only consumers to cached datasets while upstream sources recover;
- routing incidents between automated routines and human operators based on severity and confidence.
In serverless environments, monitoring events trigger lightweight functions that reconfigure retries, rebalance workloads, or change routing away from degraded services. In larger clusters, policies drive predictive scaling and redistribution of workloads before saturation hits.
A recurring design principle runs through these implementations: remediation actions are idempotent and reversible. Pipelines can apply them repeatedly without compounding damage, and every automated change leaves a trace in audit logs. That discipline makes it safe to gradually expand automation.
Self-Healing Beyond Data Quality
Early experiments in self-healing naturally gravitated toward data-quality use cases: detecting missing or inconsistent records, enforcing domain constraints, and reconciling duplicates. As telemetry improved and confidence grew, the same methods started to govern resource management and cost control.
Figure 3 shows a hypothetical comparison between manual and self-healing operation. The upper panel plots the mean time to detection and the mean time to recovery for recurrent incident types before and after the deployment of automated detectors and playbooks. The lower panel tracks incident volume over time as detection coverage improves and remediation workflows become more standardized.
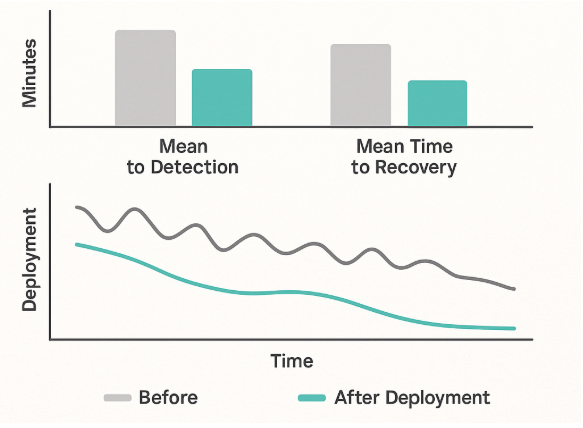
Figure 3. Comparison of Manual vs. Self-Healing Operation (Synthetic Data)
Autonomous data ecosystems on cloud platforms illustrate this progression. Telemetry at millisecond granularity feeds anomaly detectors that anticipate system degradation before dashboards slow down. Reinforcement learning agents explore alternative cluster configurations, partitioning strategies, and storage tiers, converging on setups that respect service-level agreements while shrinking infrastructure spend. In multi-tenant environments, AI-driven orchestrators determine when to scale up or down, when to shed non-critical workloads, and how to prioritize high-priority jobs during periods of increased activity.
In parallel, the convergence of MLOps and DataOps extends self-healing behaviour from model pipelines back into data pipelines. When data and model observability share a single fabric, drift in features or label quality not only triggers model retraining or rollback, but also impacts the overall model performance. It can also drive adjustments in ingestion rules, feature engineering stages, and validation layers so that training and production environments remain aligned.
A Step-by-Step Implementation Strategy
Adopting self-healing principles does not require a new vendor stack or a complete redesign from scratch. The transition works best as an incremental programme with clear boundaries and quick feedback.
A practical starting sequence looks as follows.
1. Map recent failures
Review the last few quarters of incidents and classify them by type: schema changes, late or missing data, infrastructure saturation, configuration errors, and upstream contract changes. This produces a prioritized list of failure modes that matter in the local environment, rather than an abstract catalogue copied from other organizations.
2. Instrument existing pipelines
For each high-impact failure mode, add specific telemetry to jobs that participate in it, including counts, schema signatures, checksums, distribution summaries, and domain rules. Collect these signals centrally with enough granularity to distinguish normal fluctuations from genuine problems. Do this before deploying machine learning; otherwise, anomaly detectors will simply have nothing reliable to work with.
3. Introduce simple detectors and alerts
Start with straightforward rules and basic anomaly detectors over the new telemetry. Focus on early detection of issues that previously reached users. Tune signals carefully to avoid alert fatigue. Treat this stage as a calibration phase where both humans and models learn which patterns truly predict trouble.
4. Automate safe, reversible actions
Once detection stabilizes, identify a handful of corrective actions that are low-risk and fully reversible. Typical candidates include replaying idempotent jobs, isolating suspect partitions, switching a subset of workloads to cached datasets, or temporarily downscaling non-critical tasks to protect vital flows. Wrap these actions in playbooks that the system can trigger under explicit conditions.
5. Expand scope and sophistication gradually
As confidence grows, widen coverage to more pipelines, richer detection methods, and more advanced automation, including resource optimization and agentic patterns where appropriate. Keep guardrails simple but explicit: clearly document which actions the system may take on its own, which require approval, and which remain firmly in human hands.
Over time, telemetry, detection, and automation reinforce one another. Pipelines learn to surface the correct information at the right moment, models improve at predicting genuine incidents, and playbooks evolve from scattered scripts into a coherent operating fabric. The result is not an autonomous black box, but an environment where data teams spend less energy on repeated firefighting and more on building reliable products that earn and keep the trust of their users.


