

The Model Context Protocol (MCP) provides a standardized, open way for language models to discover and invoke external tools, APIs, and data sources at runtime.[1] Released by Anthropic in November 2024, it reduces the need for custom integrations and improves interoperability across a growing ecosystem of tools and platforms (e.g., GitHub, Postgres, and custom agent frameworks).[1]
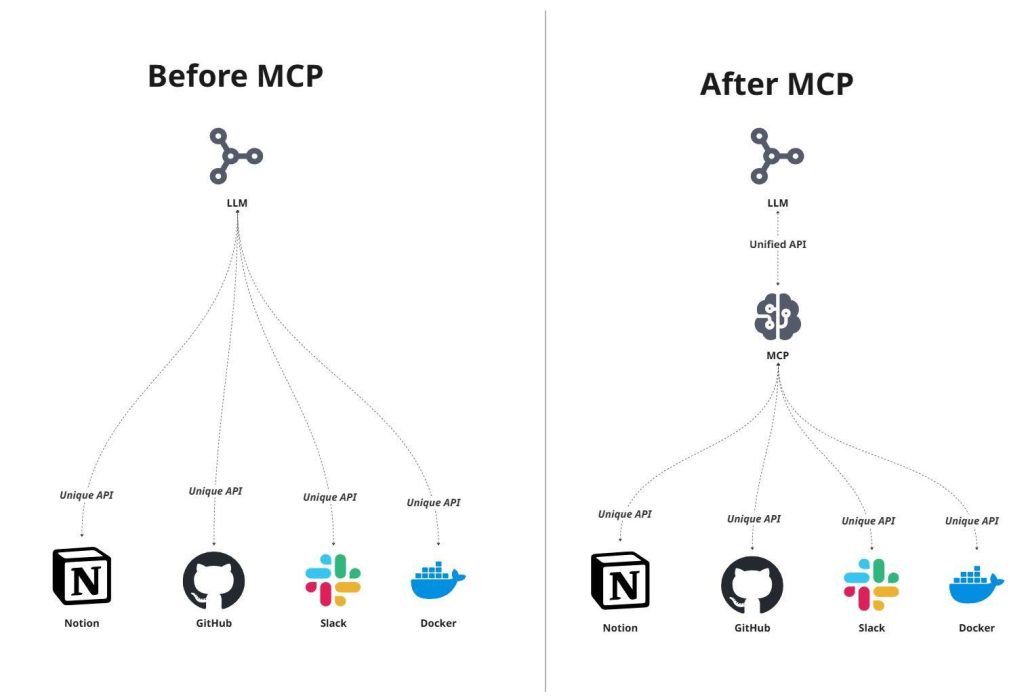
This centralization, however, may turn MCP servers into attractive targets. A single misconfiguration can expose sensitive data or enable large-scale automated abuse.[2] Strong governance and runtime safeguards therefore appear essential, especially in enterprise environments.
Why MCP Security Matters
MCP servers grant AI agents the ability to read files, issue network requests, or execute actions on behalf of users.[3] Compromise one endpoint and an attacker might exfiltrate proprietary data, disrupt operations, or trigger malicious workflows at scale.[2] A subtler risk involves “rug-pull” updates: a tool provider quietly modifies a manifest after integration, introducing behavior ranging from subtle leakage to outright destruction.[2] The MAESTRO threat model in the Enterprise-Grade Security paper suggests that defenses must span design, deployment, and operations.[3]
Frequent Pitfalls and Effective Countermeasures
-
Tool-Manifest Poisoning
Tampered manifests can mislead agents into executing harmful operations – leaking credentials or escalating privileges – simply because the metadata itself is trusted.[3][4]
Countermeasures
- Cryptographically sign manifests with certificates from a trusted PKI and pin exact versions.[3]
- Validate every manifest against a strict schema before use.[3]
- Maintain an allowlist of approved servers and scan regularly for homograph-style impersonation.[5]
- Test new tools in isolated sandboxes; supply-chain practices like SLSA help ensure immutability.[3]
-
Prompt Injection via Descriptors
Hidden instructions embedded in tool descriptions can bypass model safeguards, triggering the classic OWASP LLM01 vulnerability in autonomous settings.[6]
Countermeasures
- Sign and version-lock descriptors alongside manifests.[3]
- Store immutable copies for audit trails.[3]
- Run static linters that flag imperative language or URL patterns.[3]
- Deploy runtime anomaly detection to catch unexpected prompt deviations.[3]
-
Authentication and Authorization Gaps
Without per-request checks, any agent that knows an endpoint URL can act as a legitimate caller – a textbook confused-deputy scenario.[3][5]
Countermeasures
- Enforce short-lived, sender-constrained tokens or mutual TLS for every request.[3][7]
- Require step-up authentication for high-risk operations.[3]
- Layer simple behavioral rules: flag sudden spikes from new regions or unusual call patterns.[3][5]
-
Path Traversal and Confused-Deputy File Access
File-system tools often accept paths directly from the agent, inviting ../../ tricks that bypass intended boundaries.[3][5]
Countermeasures
- Canonicalize and validate paths server-side before resolution.[3]
- Restrict operations to explicit allowlisted directories.[5]
- Run tools in lightweight containers or chroot jails. Red Hat’s MCP guidance provides detailed recommendations for these controls.[5]
-
Command Injection and Server-Side Request Forgery (SSRF)
Unfiltered inputs passed to shells or internal HTTP clients remain a perennial weakness.[3]
Countermeasures
- Favor parameterized libraries over string concatenation.[3]
- Apply strict allowlists for outbound destinations.[8]
- Place a web application firewall and detailed egress logging in front of internal services.[8]
-
Denial-of-Service via Payload Expansion
Attackers can crash parsers with recursive entities (“Billion Laughs”) or flood endpoints with oversized requests.[3][9]
Countermeasures
- Enforce hard limits on payload size, recursion depth, and request rates.[3]
- Use hardened parsers that reject entity expansion by default.[9]
- Deploy circuit breakers to isolate misbehaving clients quickly.[3]
-
Data Exfiltration in Tool Outputs
Sensitive information can hide in otherwise legitimate responses – base64 blobs, stacked comments, or steganographic patterns.[3]
Countermeasures
- Route all outputs through a data-loss-prevention engine configured for redaction.[2]
- Retain tamper-proof logs of raw responses.[2]
- Avoid embedding secrets in configuration files that tools might echo back.[3]
Operational Visibility and Response
Even robust controls can be circumvented without observability. Capture every tool discovery, import, invocation, and response in structured logs, then forward them to your SIEM.[3] Platforms like Datadog’s LLM Observability module provide MCP-specific metrics – call volume, prompt anomaly scores, and performance metrics – that surface issues in real time.[2] Pre-written playbooks for manifest tampering, sudden DoS, or unauthorized escalation shorten mean-time-to-respond.[3]
Conclusion
MCP accelerates agent development, but it appears to concentrate risk in ways that demand deliberate engineering.[3] Layered mitigations – cryptographic signing, isolation, fine-grained authorization, input hardening, DLP, and continuous monitoring – can reduce the attack surface without sacrificing the protocol’s benefits.[3] The MAESTRO framework, combined with established guidance from OWASP and NIST, offers a practical roadmap.[3][6][8] Implementing these controls is less about inventing new techniques and more about applying proven practices consistently.
References
- Anthropic. (2024). Introducing the Model Context Protocol. https://www.anthropic.com/news/model-context-protocol
- Datadog. (2025). Understanding MCP security: Common risks to watch for. https://www.datadoghq.com/blog/monitor-mcp-servers/
- Narajala, V. S., & Habler, I. (2025). Enterprise-Grade Security for the Model Context Protocol (MCP): Frameworks and Mitigation Strategies. arXiv:2504.08623. https://arxiv.org/abs/2504.08623
- MindGuard: Tracking, Detecting, and Attributing MCP Tool Poisoning Attack. (2025). arXiv:2508.20412. https://arxiv.org/abs/2508.20412
- Red Hat. (2025). Model Context Protocol (MCP): Understanding security risks and controls. https://www.redhat.com/en/blog/model-context-protocol-mcp-understanding-security-risks-and-controls
- OWASP Foundation. (2025). LLM01:2025 Prompt Injection. https://genai.owasp.org/llmrisk/llm01-prompt-injection/
- Model Context Protocol Consortium. (2025). Authorization in MCP: OAuth 2.1 Best Practices. https://modelcontextprotocol.io/specification/2025-06-18/basic/authorization
- NIST. (2025). SP 800-228: Guidelines for API Protection for Cloud-Native Systems. https://csrc.nist.gov/pubs/sp/800/228/final
- OWASP Foundation. (2025). XML External Entity Prevention Cheat Sheet. https://cheatsheetseries.owasp.org/cheatsheets/XML_External_Entity_Prevention_Cheat_Sheet.html



