
As artificial intelligence continues to evolve, AI inference workloads are running into a critical infrastructure limitation: the memory wall. While the concept of a memory wall originated in traditional computing, its impact in AI is even more pronounced.
Inference tasks now involve large-scale models with hundreds of billions or even trillions of parameters, and they must deliver results in near real time. This growing demand creates significant challenges for memory capacity, bandwidth, and latency that current system architectures are not well equipped to handle.
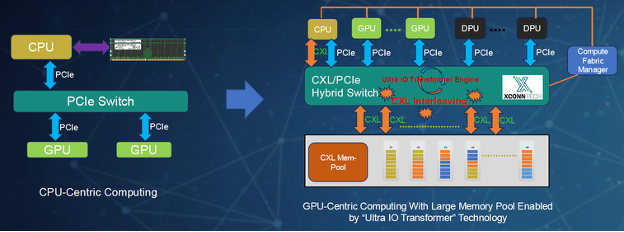
Ultra IO Transformer (UIOT) technology introduces a new approach to addressing this challenge by enabling GPUs to access large pools of memory more efficiently. This shift in architecture makes it possible to build more scalable, cost-effective, and responsive AI inference systems.
Understanding the Memory Wall in AI
Inference is rapidly becoming the dominant workload in AI infrastructure, outpacing training in both volume and real-time performance requirements. The scale and complexity of AI models are increasing, and with that comes the need for significantly more memory to support inference at speed.
Large models require not only high-capacity memory, but memory that is also low latency and high bandwidth. Conventional approaches rely heavily on high-bandwidth memory (HBM) built into GPUs, which typically provide around 100 GB per unit. While HBM is fast, its capacity is limited and expensive. Alternative approaches that use system memory routed through CPUs introduce latency and bandwidth bottlenecks due to inefficient data movement paths.
The result is a memory wall that limits scalability and creates cost and performance trade-offs. Organizations are often forced to choose between overinvesting in high-end GPUs just to get more memory, or accepting slower inference times. This is particularly problematic in real-time applications where users expect sub-second responses.
A New Architectural Approach
Ultra IO Transformer (UIOT) technology, developed by XConn, offers a new architectural model. It enables GPUs that support Peripheral Component Interconnect Express® (PCIe® )to access large-scale Compute Express Link![]() (CXL
(CXL![]() ) memory pools directly through a specialized switch fabric. This fabric acts as a bridge, dynamically converting PCIe to CXL and back, enabling seamless access to memory resources previously isolated from GPU workflows.
) memory pools directly through a specialized switch fabric. This fabric acts as a bridge, dynamically converting PCIe to CXL and back, enabling seamless access to memory resources previously isolated from GPU workflows.
This approach eliminates the need for GPUs to route memory requests through CPUs, which adds latency and inefficiency. By creating a more direct and streamlined connection between compute and memory, UIOT allows systems to scale without being bound by the limitations of onboard HBM or CPU-managed DRAM.
Rethinking the Stack: A Practical and Scalable Path Around the Memory Wall
To validate the impact of UIOT in real-world conditions, a comparative study was conducted using three common memory access architectures for AI inference. Each configuration represents a different strategy for managing the trade-offs between speed, capacity, and cost in delivering inference at scale.
These test environments were designed to reflect how organizations currently deploy AI infrastructure under different budget and performance constraints. The goal was to understand how each approach handles the growing memory demands of large AI models, especially when inference must occur in milliseconds across a high volume of concurrent users.
The three architectures tested were:
1. GPU-only, using onboard HBM. This setup reflects the high-performance end of the spectrum, relying on each GPU’s internal high-bandwidth memory (typically 80 to 100 GB). While fast, this memory is limited in size and expensive to scale.
2. GPU accessing system memory via CPU. In this conventional architecture, GPUs rely on CPUs to manage access to system DRAM. This offers greater capacity than HBM alone but introduces latency due to the multiple hops required for data access, making it less suitable for latency-sensitive inference.
3. GPU accessing CXL memory via UIOT. This configuration enables GPUs to directly access large pools of shared memory over CXL through the UIOT switch. It combines the performance of local memory with the flexibility and scale of disaggregated infrastructure.
In every dimension measured—latency, bandwidth, scalability, and cost-efficiency—the third configuration outperformed the others. The GPU-only setup was limited by memory capacity. The CPU-based approach introduced latency and resource contention. In contrast, UIOT enabled GPUs to tap directly into large, shared memory pools with minimal overhead.
The underlying architecture delivers several unique advantages:
• High-bandwidth access through memory interleaving. UIOT supports interleaved access across multiple CXL memory devices, allowing data to be streamed simultaneously from multiple sources. This raises aggregate bandwidth to levels that approach, and in some cases rival, HBM performance.
• Low-latency memory access. By eliminating the need to route memory requests through CPUs and multiple IO layers, UIOT shortens the data path. Latency is comparable to or better than that of high-performance GPU interconnects in existing inference clusters.
• Modular scalability. The UIOT switch architecture supports cascading and high port density, enabling multi-GPU configurations to access increasingly large memory pools. This makes it possible to decouple compute and memory planning in AI infrastructure, allowing both to scale independently.
Together, these benefits offer a more balanced and efficient architecture for AI inference, eliminating the need to overuse compute resources just to access additional memory. For organizations seeking to deploy large-scale AI services without sacrificing speed or budget, UIOT provides a practical and forward-looking solution.
Implications for Data Center Design and Efficiency
The architectural flexibility introduced by UIOT is especially important for future AI inference factories, where clusters of eight or more servers may serve as the base deployment unit. With memory and compute decoupled, data center designers can optimize resource provisioning for performance, energy efficiency, and cost.
Energy consumption is also reduced by avoiding overprovisioned compute nodes and eliminating unnecessary data movement across inefficient interconnects. This leads to a lower total cost of ownership (TCO) while maintaining or improving inference performance.
Preparing for Mass Deployment
UIOT represents a fundamental shift in how memory and compute can be organized for AI inference. It opens the door to more modular and efficient AI infrastructure that supports larger models, lower latency responses, and more cost-effective scaling.
As support for CXL continues to expand across the hardware ecosystem, technologies like UIOT will become critical components in the design of next-generation AI data centers. These solutions allow organizations to extend the capabilities of existing hardware, future-proof their infrastructure, and better serve the growing demands of AI at scale.
At a moment where performance, cost, and flexibility are all top priorities, rethinking memory architecture with approaches like UIOT may prove to be one of the most important enablers of the next wave of AI adoption.
About the Author
Jianping (JP) Jiang is the VP of Business, Operation and Product at Xconn Technologies, a Silicon Valley startup pioneering CXL switch IC. At Xconn, he is in charge of CXL ecosystem partner relationships, CXL product marketing, business development, corporate strategy and operations. Before joining Xconn, JP held various leadership positions at several large-scale semiconductor companies, focusing on product planning/roadmaps, product marketing and business development. In these roles, he developed competitive and differentiated product strategies, leading to successful product lines that generated over billions of dollars revenue. JP has a Ph.D degree in computer science from the Ohio State University.



