It is 8 p.m. and a licensed psychotherapist is still typing up session notes instead of reading her child a bedtime story. Administrative drag like this afflicts clinicians, loan officers, teachers, underwriters — anyone whose judgment must be documented. AI promises relief, but hard-won trust now hinges on proof, not pitch decks.
Recent flame-outs — from Theranos in diagnostics to IBM Watson in oncology — have made buyers, regulators and investors allergic to unverified claims. For mission-critical systems, two independent lines of evidence are now the minimum entry ticket. Below is a tiered validation playbook that companies can mix and match according to risk, regulatory exposure and stage of product maturity.
1. Lab-Grade Science
If you cannot beat the chance, you are still in the lab. Peer-reviewed randomised controlled trials (RCTs) and standardised benchmark challenges establish causal efficacy under transparent conditions.
When to use: Healthcare, education, public-sector safety — any domain where false positives carry human cost.
Implementation: typical budget – $150k–300k; timeline – 6–12 months.
Example: A 70-therapist RCT published in Psychology showed that an AI-powered assistant cut the doctors’ documentation time by 55 % (20 → 9 min) and produced a +0.18-point rise in client-progress scores on a 5-point scale.
2. Sandbox Reality
Validate safely before deployment. So-called “shadow-mode” or prospective trials run the model in parallel with human decision-makers. Errors surface quickly, but no end user is harmed.
When to use: Regulated settings where you cannot yet replace human judgment.
Implementation: typical budget – $50k–100k 3–6 months.
Example: JPMorgan’s COiN contract-analysis engine processed thousands of documents alongside lawyers for six months before the first production decision was handed over.
3. Live Market Split-Tests
Ship two versions, measure the delta. Large-scale A/B or feature-flag experiments expose real users to treatment and control variants under identical conditions, quantifying lift in operational or financial KPIs.
When to use: Consumer or SaaS products with rapid iteration cycles and low per-user risk.
Implementation: typical budget – $10k–50k; 2–8 weeks.
Example: Duolingo continuously runs more than 2 000 concurrent tests to tune its language-learning models and can attribute retention or learning-gain changes to a single line of model code.
4. Regulatory Clearances
Pass the audit, win the market. External certifications (FDA SaMD, CE, ISO/IEC 42001, SOC 2 + HIPAA) scrutinise process quality, data governance and post-market surveillance.
When to use: Medical, finance, aviation, energy — anywhere statutory oversight exists.
Implementation: typical budget – $200k–500k; 9–18 months.
Example: Viz.ai’s stroke-triage algorithm became the first AI tool to earn an FDA De Novo clearance, unlocking nationwide reimbursement and hospital adoption.
5. Radical Transparency
Open your data, invite scrutiny. Publishing model cards, dataset documentation, evaluation harnesses and red-team reports lets independent researchers replicate or criticise results — an accelerant for credibility.
When to use: When community trust and technical talent matter as much as immediate revenue.
Implementation: typical budget <$25k; 1–2 months.
Example: Meta’s Llama release included safety cards and public evaluation logs, enabling third parties to verify claims and identify gaps before deployment.
6. Long-Horizon Outcomes
Prove you survive drift and seasonality. Real-world evidence (RWE) studies and post-market registries track performance over quarters or years, detecting concept drift, demographic bias and unintended consequences.
When to use: High-impact systems already in circulation.
Implementation: typical budget – $100k+/year; ongoing.
Example: Epic’s sepsis-prediction algorithm was re-evaluated after three years across multiple sites, with peer-reviewed data showing sustained mortality reduction and manageable false-alert rates.
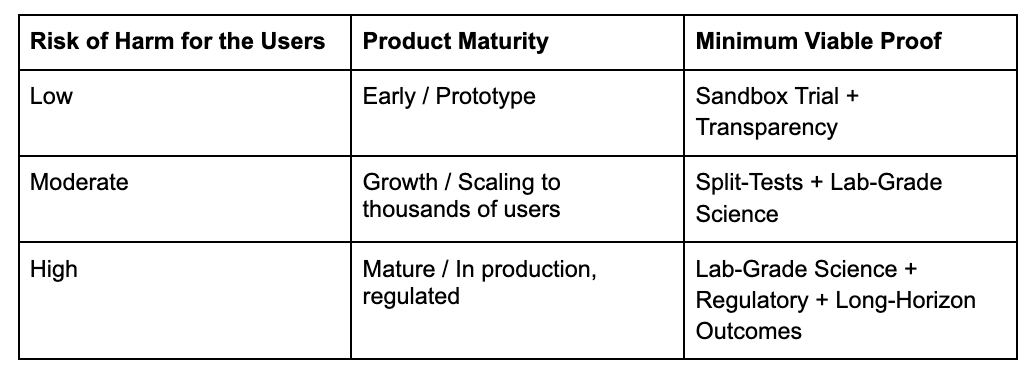
Strategic Matrix: Which Layers Do You Need?
Avoid the Zombie Metrics
Accuracy without base-rate context, vendor-sponsored surveys and single-site pilots are inadequate. Demand effect sizes, confidence intervals and independent oversight.
P.S. The 8 p.m. therapist now logs off at 6 p.m. because her notes write themselves in nine minutes, not twenty. Evidence did that — not hype, slideware or emojis. Whatever you build, select at least two evidence layers and publish your data, or risk being filed under “unvalidated AI marketing.”