As the complexity of AI and cloud infrastructure scales, resilience is no longer optional—it is foundational.
In this article, Principal Software Engineer Aditya Bhatia draws on over 15 years of experience at companies such as Apple, Yahoo!, and Splunk to share actionable strategies for designing fault-tolerant machine learning systems. From Kubernetes-native tooling to chaos engineering, he explores what it truly takes to build AI that does not merely function, but endures.
When I first started working on distributed systems, I was captivated by a simple but powerful question: How do you keep a system running when parts of it fail? This question has driven much of my work in building robust AI and cloud infrastructure over the past 15 years, from Fortune 500 companies like Apple and Yahoo! to my current role as a Principal Software Engineer at Splunk.
In this article, I want to share a set of foundational principles and real-world lessons I’ve learned while designing fault-tolerant machine learning systems. I hope to offer both engineers and tech leaders a practical lens for thinking about reliability, not as a reactive fix but as a proactive design philosophy that scales with your ambitions.
Why Fault Tolerance Matters Now More Than Ever
Today’s machine learning (ML) systems are no longer isolated training pipelines running on a developer’s local machine. They are dynamic, distributed, production-grade architectures spread across Kubernetes clusters, GPU nodes, and multi-cloud environments. In such systems, failure isn’t a possibility—it’s a certainty.
And yet, I often see organizations underestimate how quickly a small fault can cascade. A silent data inconsistency in one node might lead to skewed models, which then inform business-critical decisions. Or a failed GPU job can stall an entire pipeline during peak demand. The result? Downtime, lost trust, and massive opportunity cost. This is why fault tolerance has moved from a niche systems concern to a strategic necessity in ML and cloud-native AI applications.
For example, a 2023 report analyzing 2.4 billion containers found that organizations are increasingly leveraging GPU-based compute, with usage growing 58% year-over-year, highlighting the rising stakes of reliability at scale.
GPU Adoption Is Reshaping Infrastructure Demands
The rise of machine learning and generative AI has fueled an unprecedented demand for high-performance computing, mainly driven by GPUs. These processors are now central to training large models and running scalable inference across industries.
As organizations continue to scale AI capabilities, this demand is reflected in the broader infrastructure market. A recent report from Global Market Insights forecasts strong growth in both cloud-based and on-premises GPU deployments through 2032. This trend underscores a key point: the more we rely on GPUs, the higher the cost of failure becomes, and the more critical fault tolerance becomes at every layer of the stack.
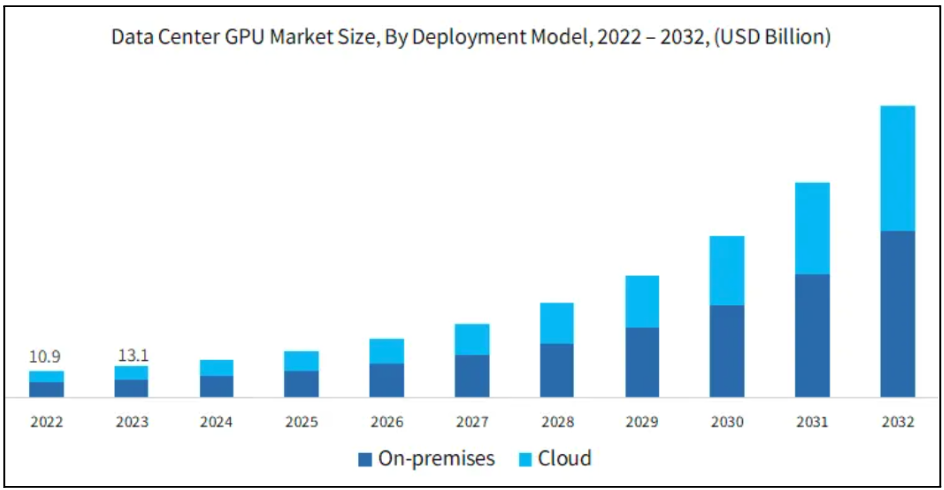 Source: Global Market Insights – Data Center GPU Market Report
Source: Global Market Insights – Data Center GPU Market Report
GPU workloads are no longer limited to research labs; they’re mission-critical for enterprises. Any disruption from a failed node or resource bottleneck can stall innovation and erode performance. In this context, fault tolerance isn’t just an engineering safeguard; it’s a strategic imperative.
Early Lessons: From Voice Models to Distributed Resilience
When I was at Apple working on Siri’s Text-to-Speech (TTS) evaluation systems, we had to process vast amounts of voice data and phonetics in a repeatable and highly available manner. I architected a distributed service for evaluating ML voice models, running them across high-performance clusters orchestrated with Kubernetes.
It was here that I realized the power of designing for failure up front. We implemented automated failovers, built reproducibility into our pipelines, and ensured every step had state checkpoints. The result was a 90% boost in service availability and a dramatic reduction in training cycle times.
These principles carry over to my current work at Splunk, where I lead a team developing distributed workflow orchestration systems. We manage cloud performance at scale for thousands of customers, where even a brief outage could impact critical observability for enterprises.
Pillars of Fault-Tolerant ML Systems
To demystify the concept, fault tolerance in distributed ML frameworks generally hinges on a few key pillars:
1. Redundancy by Design
In our Kubernetes-native orchestration system, redundancy isn’t an afterthought. We implement multi-zone deployments, replica sets for critical services, and automated backup checkpoints for ML pipelines. When a container or node fails, the system self-heals with minimal disruption.
Redundancy allows the system to withstand infrastructure hiccups without affecting downstream workflows. However, redundancy is costly, so part of the art is balancing failover capacity with efficiency.
2. Checkpointing and State Management
Imagine training a model for 12 hours and losing it in hour 11 due to a GPU crash. That’s unacceptable in production. We design pipelines with granular checkpoints, storing intermediate states using distributed storage like S3 or GCS. Whether it’s a training job or a transformation step, failure should only mean a minor restart, not a full rerun.
3. Intelligent Monitoring and Auto-Recovery
At Splunk, observability is our bread and butter. Our orchestration engine is instrumented with Prometheus and Grafana dashboards to detect anomalies in real-time. In fact, the 2023 Splunk State of Observability Report notes that organizations with mature observability practices are four times more likely to resolve outages within minutes, highlighting the direct link between robust monitoring and uptime.
4. Data Validation and Consistency
Fault tolerance isn’t just about code—it’s about data integrity. We apply validation logic at data ingress points to sanitize corrupt or malformed records before they poison the system. We also embed consistency checks in preprocessing steps for ML use cases to detect distribution shifts or feature anomalies.
5. Chaos Engineering
One of the most empowering practices we’ve adopted is chaos engineering. Inspired by Netflix’s “Chaos Monkey,” we regularly simulate failures—killing nodes, delaying network calls, and corrupting inputs—to observe how our system recovers. We’ve caught multiple latent bugs this way, long before they could become customer-impacting outages.
The Role of Kubernetes and Cloud-Native Tooling
Kubernetes has been a game changer in this space. Its declarative model allows us to define the desired state of an ML job, and its reconciliation loop ensures that the state is maintained, even in the face of failure. Tools like Argo Workflows, Kubeflow, and custom Kubernetes operators have enabled us to scale job orchestration, version control, and fault recovery.
However, tooling isn’t enough. It takes a deep cultural shift to design systems assuming that every component can fail. Building such systems requires thoughtful defaults, automated remediation, and cross-team alignment. And this is where leadership comes into play.
Leading Teams to Build Resilient Systems
As an engineering leader, I’ve always prioritized knowledge sharing and mentorship. When I built out the fault-tolerant infrastructure at Splunk, I made sure our architecture principles were documented, democratized, and embedded into every design review.
I also believe in empowering engineers to experiment. One of my team members proposed a retry-logic optimization for failed ML jobs that ended up saving us hundreds of compute hours per month. Good ideas can come from anywhere—but only if you foster a culture where resilience is everyone’s responsibility.
This leadership philosophy has paid dividends: several of my mentees have gone on to lead their own teams, and we’ve collectively contributed to millions in cloud cost savings through smarter resource management.
Challenges Ahead: Where Fault Tolerance Must Evolve
Despite our progress, there are emerging challenges we must address. To better visualize where the industry is heading, here’s a breakdown of three core challenges we face and how potential solutions are evolving:
| Challenge | Why It Matters | Directions for Solutions |
| GPU Scheduling Complexity | Shared GPUs cause interference and instability | Dynamic GPU partitioning and isolation frameworks |
| Real-Time Pipelines | Millisecond-level failover is hard with batch-focused tooling | Stream-native orchestration and event-driven retries |
| Cross-Cloud Resilience | Heterogeneous clouds increase recovery complexity | Unified observability and abstracted orchestration |
These challenges are what energize me. I see firsthand how the next generation of engineers is grappling with these issues. And I’m excited to continue contributing through research, mentorship, and system design.
Final Thoughts: Embrace Failure, Design for It
“Failure isn’t fatal, but failure to change might be.”
— John Wooden, Forbes
In the world of complex ML pipelines and distributed infrastructure, failure is not just probable—it’s inevitable. But resilience isn’t only about recovery; it’s about adapting. As John Wooden put it, that idea sits at the heart of fault-tolerant design.
Whether you’re building an AI-powered cloud service or a hybrid learning system, assume that something will break, and design with that in mind. Create systems that self-heal, empower teams to act proactively, and build feedback loops that treat disruption as a source of insight. From voice models at Apple to orchestrated workloads at Splunk, this mindset has shaped how I approach building and leading engineering teams.
Designing for fault tolerance isn’t just a technical goal—it’s a leadership practice that requires patience, iteration, and cultural buy-in. Looking ahead, scalable AI demands more than performance alone. Resilient design must become a foundational principle—embedded not only in our architecture, but in the way our teams collaborate, prioritize, and evolve.
If you’re working on distributed ML systems, scaling cloud-native infrastructure, or evolving your engineering culture around resilience, I’d welcome the opportunity to connect. Whether through mentorship, collaboration, or speaking engagements, I’m always eager to exchange ideas with peers, building the future of intelligent infrastructure. Together, we can shape an AI future that doesn’t just perform, but prevails.