

Large language models (LLMs) are shifting from experimental tools to production powerhouses. But deploying them at scale introduces real-world hurdles. Latency spikes, unpredictable costs, and brittle workflows can derail even the most promising AI projects.
The key lies in designing systems that balance speed, reliability, and adaptability. This article explores how to build LLM pipelines and agentic workflows that meet these demands. We will dissect architectural choices, optimization techniques, and the nuances of agentic AI. And we will address the trade-offs—because no system is perfect, but the right design can get close.
LLM Pipelines vs. AI Agents
LLM pipelines and AI agents serve distinct purposes in production AI systems. Understanding their differences is critical for choosing the right architecture.
LLM Pipelines are predefined, sequential workflows designed for deterministic tasks. They process inputs through fixed stages—such as data ingestion, preprocessing, model inference, and post-processing—with minimal deviation.
These pipelines excel at batch operations (e.g., document summarization) or real-time tasks (e.g., chatbot responses) where consistency and reproducibility matter. Their rigidity makes them easier to debug and scale, but they lack adaptability when faced with novel scenarios.
AI Agents, in contrast, are dynamic systems capable of autonomous decision-making. They integrate tools (e.g., APIs, databases), memory (e.g., conversation history), and logic (e.g., reinforcement learning) to handle open-ended tasks.
For example, an agent might research a topic by browsing the web, synthesizing findings, and adjusting its approach based on feedback. This flexibility comes at a cost: agents introduce complexity in orchestration, higher latency, and nondeterministic behavior.
When to Use Each Approach
- Choose pipelines for high-volume, repeatable tasks where speed and predictability are priorities.
- Choose agents for interactive, exploratory tasks requiring real-time adaptation.
The line blurs in hybrid systems. A customer support workflow might use a pipeline for intent classification but delegate complex queries to an agent. The decision hinges on your tolerance for variability versus your need for control.
 Building the Core Pipeline Architecture
Building the Core Pipeline Architecture
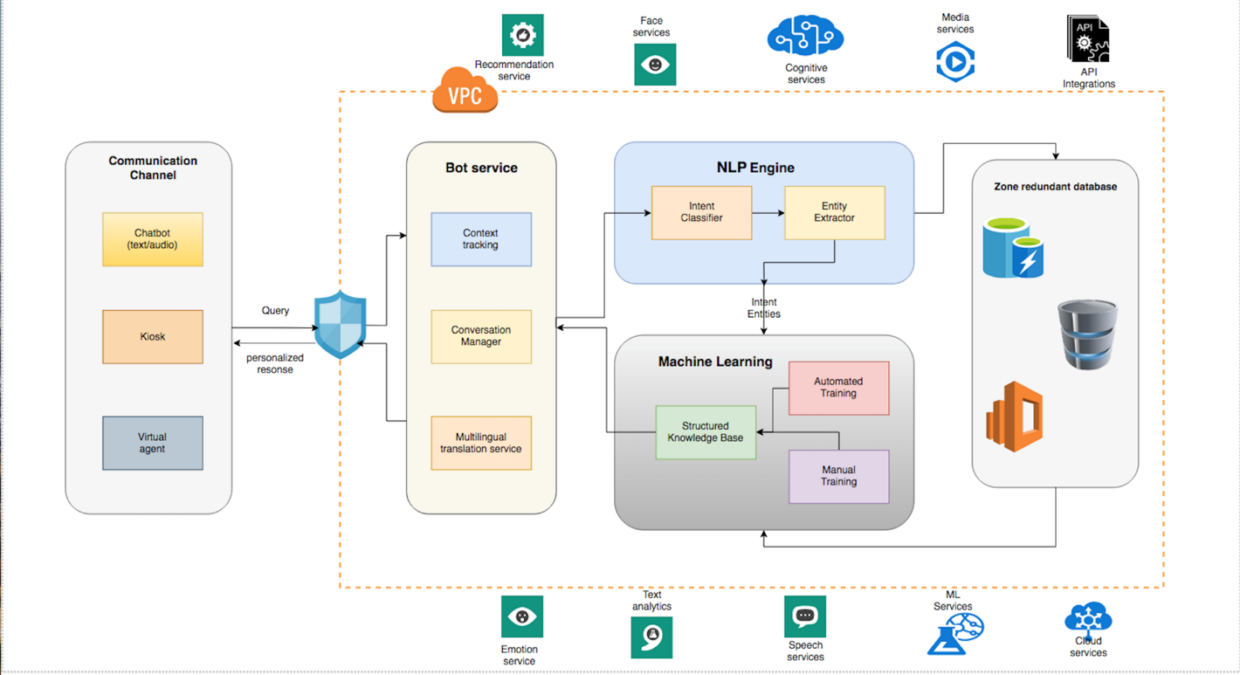 Building the Core Pipeline Architecture
Building the Core Pipeline ArchitectureOnce you have identified the right use case, the next step is constructing a robust LLM pipeline. This involves more than just loading a model—it requires careful design at every stage, from data preparation to deployment.
Below, we break down the key components of a scalable pipeline, including data optimization, model fine-tuning, inference engine selection, and infrastructure choices. Each decision impacts performance, cost, and maintainability, so let us examine them systematically.
How to prepare your data for LLM pipelines
Building effective LLM pipelines requires careful data preparation. Start with data ingestion, gathering inputs from databases, APIs, or unstructured sources while handling inconsistencies and rate limits.
Tools like Apache Kafka help, but the choice depends on latency and volume needs. Next, preprocessing cleans and standardizes data by removing noise, normalizing text, and chunking documents.
Finally, tokenization must balance granularity and context—using subword or sentence-level methods aligned with the model’s limits. Poor data processing often causes pipeline failures, so consistency is key.
How to fine-tune and optimize large language models
To customize LLMs, fine-tuning adjusts models for specific tasks, while PEFT methods (like LoRA) provide a resource-efficient alternative by updating only select parameters. For deployment optimization, distillation creates compact models that retain performance, and quantization reduces memory/processing needs by using lower-precision weights.
Choose PEFT for task adaptation, distillation for cost savings, and quantization for hardware efficiency—all while balancing performance trade-offs.
How to select and deploy inference engines
Key inference engines like vLLM (high-throughput batching), TensorRT-LLM (GPU-optimized low latency), and ONNX Runtime (hardware-agnostic) each excel in different scenarios—choose based on your latency and infrastructure needs.
Deployment options include:
- API-based for stateless tasks (e.g., chatbots)
- Streaming for real-time outputs (e.g., transcription)
- Token-level scheduling for efficient load management
The right engine-deployment pairing ensures scalable, cost-effective LLM performance.
How to ensure scalability with the right infrastructure
To handle variable LLM workloads effectively:
- Kubernetes enables robust container management with GPU-aware scheduling and automated recovery
- Intelligent auto-scaling should monitor LLM-specific metrics like GPU memory and token latency
- Microservices architecture breaks pipelines into independent, scalable components
Combining these approaches creates adaptable systems that maintain performance during demand spikes while optimizing costs. Event-driven designs and API gateways further enhance flexibility and prevent bottlenecks.
Integrating Agentic Workflows into Your AI Stack
 Agentic workflows introduce dynamic decision-making and adaptability to traditional AI systems, but integrating them requires careful planning. Unlike static pipelines, agents interact with tools, maintain memory, and adjust behavior in real time—capabilities that unlock complex use cases but also introduce new architectural considerations.
Agentic workflows introduce dynamic decision-making and adaptability to traditional AI systems, but integrating them requires careful planning. Unlike static pipelines, agents interact with tools, maintain memory, and adjust behavior in real time—capabilities that unlock complex use cases but also introduce new architectural considerations.
Below, we explore how to implement these workflows effectively, covering agent design, hybrid orchestration, and scalability patterns.
Now, let’s break down the key components:
- How to build scalable AI agents
- How to orchestrate hybrid workflows with agents
Each of these elements ensures your AI stack balances the flexibility of agents with the reliability of production-grade systems.
How to build scalable AI agents
AI agents go beyond static pipelines with dynamic decision-making, tool integration, and memory—enabling complex tasks like web-assisted research or adaptive customer support. Frameworks like LangGraph (graph-based workflows) and AutoGen (multi-agent teams) provide structured development approaches.
For scalability:
- Offload tasks to external tools to minimize LLM dependency
- Manage memory efficiently with vector databases and caching
- Implement decision guardrails including fallback protocols
The art lies in giving agents enough autonomy to solve problems while maintaining control over costs and behavior.
How to orchestrate hybrid workflows with agents
Hybrid systems combine pipelines and agents using event-driven architectures (e.g., Kafka/RabbitMQ) to dynamically route tasks—pipelines handle simple requests while agents manage complex cases.
The orchestrator/worker model adds structure by separating task delegation (orchestrator) from execution (specialized workers), enabling modular updates.
Multi-agent patterns like manager/worker or debate teams optimize collaboration, with clear protocols ensuring reliability. Start simple with event triggers, then incrementally introduce agents where needed to maintain scalability without over-engineering.
(Concisely covers: event backbone, orchestrator pattern, agent teamwork, and phased implementation—all in 2 sentences with key terms bolded.)
Monitoring, Governance, and Continuous Feedback
 Deploying LLMs in production is just the beginning—maintaining their performance, safety, and reliability requires robust oversight. Unlike traditional software, LLMs introduce unique challenges: unpredictable outputs, evolving data distributions, and complex failure modes.
Deploying LLMs in production is just the beginning—maintaining their performance, safety, and reliability requires robust oversight. Unlike traditional software, LLMs introduce unique challenges: unpredictable outputs, evolving data distributions, and complex failure modes.
This section covers the systems and practices needed to keep your models effective and accountable over time.
Here’s what we’ll examine:
- How to monitor and manage LLM performance
- How to ensure responsible and ethical AI deployment
Together, these components form a critical feedback loop—catching issues early, validating model behavior, and driving continuous improvement in real-world operation.
How to monitor and manage LLM performance
Effective LLM monitoring requires MLOps integration to track critical metrics like latency, throughput, and model drift. Implement version control for models and prompts to quickly roll back problematic updates, while latency tracking helps identify bottlenecks in real-time workflows.
For reliability, use observability tools (Prometheus, Grafana) to log errors, analyze failure patterns, and set alerts for anomalies. Structured logging of both input prompts and output quality ensures you can diagnose issues—whether from model hallucinations, API failures, or data pipeline errors.
Combine these with A/B testing frameworks to compare model versions, ensuring performance improvements are measurable before full deployment.
How to ensure responsible and ethical AI deployment
To build ethical AI systems:
- Detect and mitigate bias using specialized toolkits (e.g., Fairness 360) and techniques like adversarial debiasing
- Ensure transparency with explainability methods (LIME/SHAP) that clarify model decisions
- Maintain continuous improvement through feedback loops collecting user reports and error logs
These practices combine to create AI that is accountable (through bias checks), understandable (via explainability), and adaptable (via feedback systems) – balancing performance with ethical responsibility.
(Keeps all key elements in 3 concise points while preserving the original’s emphasis on tools, techniques and outcomes.)
Conclusion
Deploying production-grade LLM pipelines and agentic workflows requires balancing scalability, adaptability, and ethical responsibility. From architecting efficient data flows and inference engines to orchestrating hybrid agent-pipeline systems, each design choice impacts performance and maintainability. Remember:
- Start simple—Use pipelines for deterministic tasks and agents only where flexibility is critical.
- Optimize iteratively—Leverage PEFT, quantization, and observability tools to refine cost-performance trade-offs.
- Govern rigorously—Bias detection, explainability, and feedback loops ensure systems remain accountable.
The future of LLMs lies in systems that are not just powerful but also predictable and responsible. By applying these principles, you can build AI solutions that scale with your needs—without compromising on reliability or ethics. Now it’s your turn: experiment, measure, and adapt.



