
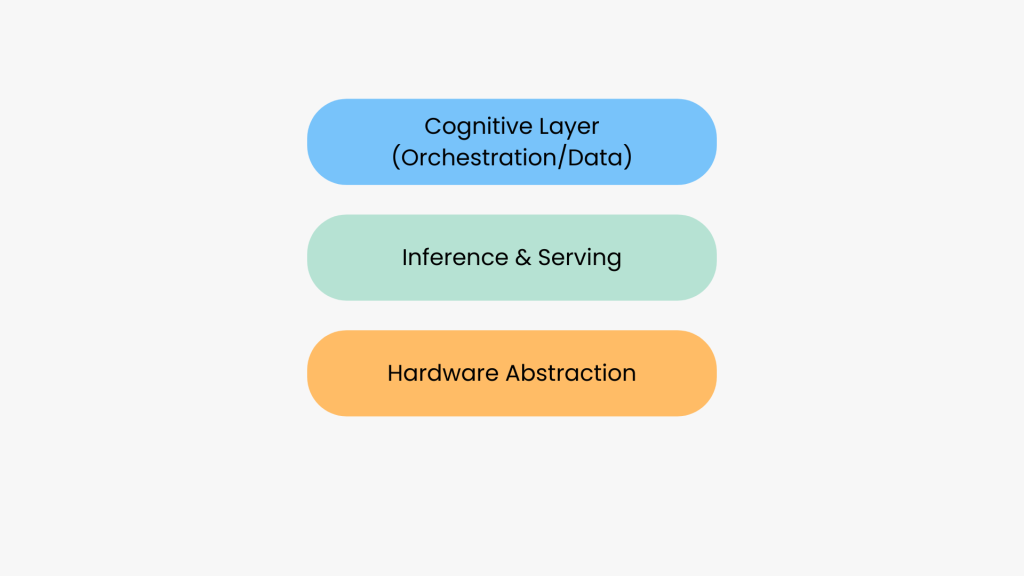
Forget the public “model wars.” The real conflict – the one for long-term control and value is a strategic battle being waged over the entire open-source AI stack.
This battle is not for a single model, it is a conflict for the three-layer stack that powers all models. The open-source software and hardware stack that underpins the entire AI ecosystem.
The entity or entities that successfully define this stack, as the “Linux of the AI age”, will wield immense influence, control the developer ecosystem, and capture the most durable economic value in the next phase of the AI revolution.
This article deconstructs this war into its three critical layers: hardware abstraction, inference serving and data orchestration.
Visuals credit – Parminder Singh
The Battle for Hardware Abstraction
At the base of the stack, where software meets silicon, Python’s long-standing incumbency as the “glue” for high-performance C++ and CUDA kernels is being challenged. Two new contenders, Apple’s MLX and Modular’s Mojo, represent fundamentally different strategies.
MLX is an array framework engineered by Apple to unlock the full potential of its own silicon. Its primary competitive advantage is its deep integration with Apple’s unified memory architecture.
In traditional systems, data must be explicitly and slowly copied between separate CPU and GPU memory pools. MLX eliminates this bottleneck; arrays live in a shared memory pool, allowing the CPU and GPU to operate on the same data without copies. Coupled with familiar NumPy-like APIs and lazy computation for optimization, MLX is not trying to replace PyTorch on all platforms. Instead, it is a classic, “deep but narrow” ecosystem play to make Apple’s hardware a first-class, high-performance environment for AI development.
|
Chip & Operation |
MLX – GPU | PyTorch – GPU | mlx_gpu/mps speedup |
|
M1 – MatMul |
26.38 | 47.87 | +81% |
| M2 Max – MatMul | 3.77 | 9.78 | +159% |
| M3 Pro – MatMul | 16.04 | 22.53 | +40% |
| M4 Max – MatMul | 4.12 | 6.36 | +54% |
| M3 Ultra – MatMul | 3.38 | 4.96 | +46% |
Comparative performance of matrix multiplication (MatMul) on Apple Silicon chips, highlighting Apple’s MLX GPU framework achieving consistently faster execution times (lower is faster/better) than PyTorch’s MPS GPU backend (Data from TristanBilot/mlx-benchmark)
Mojo is a far more ambitious gambit. It is a new systems programming language designed to solve the “two-language problem”, the inefficient workflow of prototyping in Python and then rewriting for production in C++.
Its strategy is twofold:
- Be a Superset of Python: This provides a gradual adoption path, allowing developers to use existing Python code while incrementally accelerating bottlenecks.
- First-Class MLIR Integration: Mojo is built on MLIR (Multi-Level Intermediate Representation). This allows a single source file to be compiled into highly optimized code for any target, CPUs, GPUs, and other AI accelerators, promising to break the vendor lock-in of proprietary ecosystems like NVIDIA’s CUDA. To achieve C-level performance, Mojo integrates systems-level features absent in Python, such as strong typing and a Rust-inspired ownership model for memory safety without a garbage collector.
The Engine Room: Scaling Inference from Cloud to Edge
Once a model is trained, the “engine room” is where it’s deployed for inference, and where performance directly translates to user experience and operational cost. This market is not converging; it is bifurcating into “scale-out” for the cloud and “scale-down” for the edge.
vLLM, The Throughput Maximizer From UC Berkeley, is designed for one goal: maximizing serving throughput. Its core innovation is PagedAttention, an algorithm inspired by virtual memory in operating systems.
In standard models, the Key-Value (KV) cache (which stores attention state) leads to massive memory waste, often 60-80%. PagedAttention partitions this cache into smaller, non-contiguous “blocks”, reducing memory waste to less than 4%. This near-optimal memory usage allows for significantly larger batch sizes and continuous batching, where new requests are added to the batch on the fly. This makes vLLM the unequivocal choice for high-concurrency, multi-tenant cloud services where cost-per-token is paramount.
At the other end of the spectrum, llama.cpp prioritizes portability and efficiency for consumer-grade hardware. It is a minimalist C/C++ implementation with zero external dependencies, making it easy to compile and run on virtually any platform, from laptops to Android phones.
Its power is inextricably linked to the GGUF file format. GGUF bundles the model and tokenizer into a single file and provides deep support for quantization, the process of reducing model weight precision. This drastically reduces memory footprint, allowing massive models to run on devices with limited RAM. While its simple queuing server doesn’t scale for concurrent users, it is the undisputed standard for local, on-device, and edge inference.
Hugging Face’s Text Generation Inference (TGI) is evolving from a monolithic engine into a production-ready platform. Its most pivotal strategic move is its multi-backend architecture. TGI now functions as a unified frontend that can route computation to swappable backends like vLLM, llama.cpp, or NVIDIA’s TensorRT-LLM. This is a classic platform play: TGI controls the developer API, abstracting away the underlying engine complexity. It positions Hugging Face as the essential control plane for LLM deployment.
The Cognitive Layer: Data, Orchestration, and the Rise of RAG
The cognitive layer is where AI applications gain the ability to reason, access external knowledge and execute complex tasks. This layer has been standardized by one critical architectural pattern: Retrieval-Augmented Generation (RAG).
RAG has solidified as the standard architecture for enterprise AI because it solves the two most significant limitations of LLMs:
- Stale Knowledge: RAG connects models to up-to-date information.
- Lack of Proprietary Context: It allows models to access and reason over private, domain-specific data without retraining.
This process “grounds” the model in verifiable facts, reducing hallucinations. Architecturally, this requires a symbiotic relationship between orchestration frameworks and open-source vector databases like Chroma and Weaviate, which store and search the external knowledge.
| Model | w/o RAG | w/ RAG |
| GPT-4-Turbo | 0.700 | 0.835 |
| GPT-3.5-Turbo | 0.669 | 0.804 |
| Mixtral-8×7B | 0.583 | 0.808 |
| Llama-2-70b | 0.609 | 0.760 |
Comparing vanilla models faithfulness vs RAG over the full billion dataset. RAG improves performance for all models (Data from Pinecone)
Frameworks like LangChain (the general-purpose orchestrator) and LlamaIndex (the RAG-specialist) have emerged as the dominant tools for building these RAG pipelines. A critical question has been whether they are temporary “glue” or a permanent part of the stack?
The evidence overwhelmingly suggests they are a permanent and essential fixture. While simply “chaining” API calls is becoming commoditized, the durable value is migrating to the management of complex, stateful agencies.
The evolution of tools like LangGraph, which moves beyond linear chains to enable stateful, multi-actor graphs with cycles, proves that the complexity of orchestration is increasing, not decreasing. This layer is evolving from the application’s “glue” to its “brain”.
The diagrams below illustrate the framework’s evolution from LangChain to LangGraph.

LangChain (the past) – Visuals credit – Parminder Singh
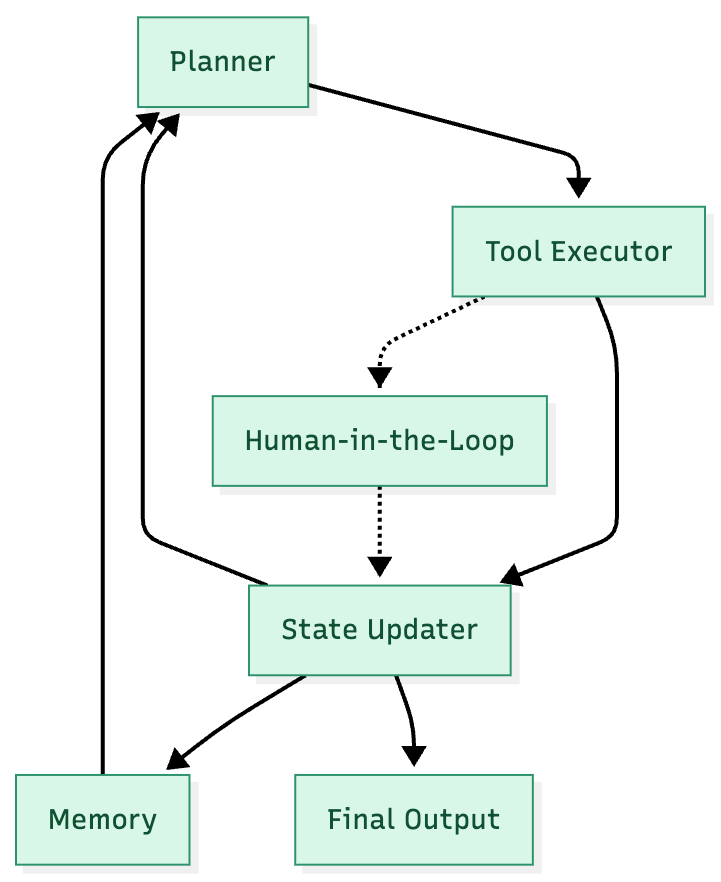
LangGraph (the future) – Visuals credit – Parminder Singh
The Strategic Landscape: Navigating the New AI Stack
These technical shifts create a new strategic landscape for developers, investors, and enterprises.
The most fundamental choice is building on closed APIs (like OpenAI) versus an open-source stack. Closed APIs offer unparalleled speed-to-market, ideal for prototyping.

Visuals credit – Parminder Singh
However, they introduce significant platform risk. The vendor has unilateral control to change pricing, deprecate models, or alter API behavior, which can break dependent applications without warning.
This risk is creating a “sovereignty premium”. Organizations are increasingly willing to pay the higher upfront cost of an open-source stack in exchange for long-term resilience, data privacy, and complete control over their strategic destiny.
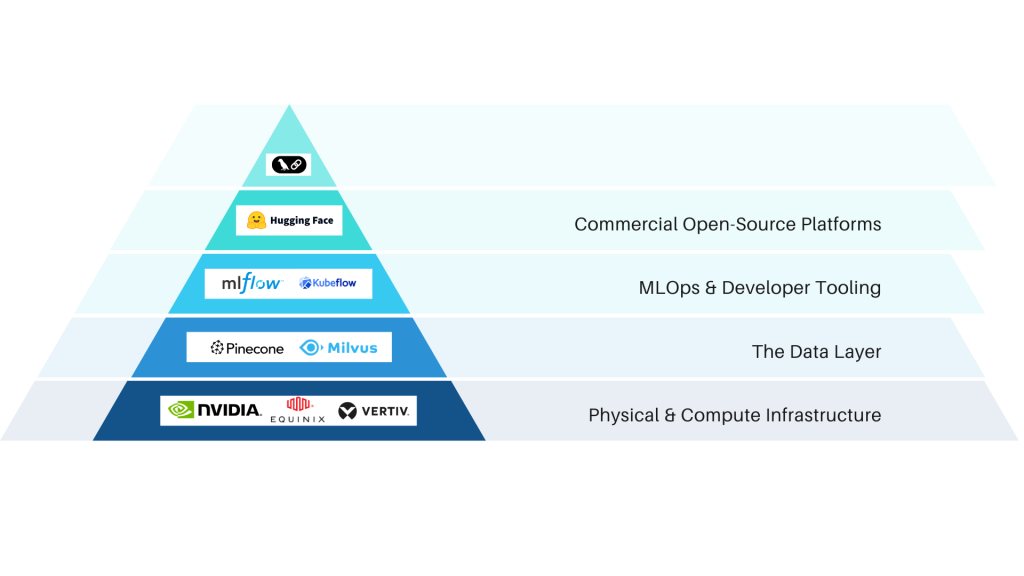
The most reliable fortunes in a gold rush are made by those selling the “picks and shovels”. In AI, this means investing in the foundational infrastructure that enables all development. Durable opportunities lie in:
- The Data Layer: Vector databases (Chroma, Weaviate) and data-labeling platforms.
- MLOps and Tooling: Platforms for experiment tracking, model versioning, and automated deployment.
- Commercial Open-Source: Companies built on the “Red Hat for AI” model, offering enterprise support for critical open-source components.
- Physical Infrastructure: The often-overlooked bottlenecks in power, data center capacity, and advanced cooling.
Visuals credit – Parminder Singh
The future AI stack will be modular, not monolithic. Based on current trajectories:
- Python’s dominance is secure. Its vast ecosystem and the sheer inertia of millions of developers create an “immense uphill battle” for any challenger like Mojo.
- The inference layer will remain bifurcated. vLLM is on track to become the standard for high-throughput cloud serving, while llama.cpp has already cemented its position as the standard for all local and edge inference.
- RAG is the standard orchestration pattern. The framework that wins this layer will be the one that provides the most robust environment for building the complex, stateful agentic workflows that are the clear next step for the industry.
The Dawn of the “Linux of AI”
The future will not be a single monolithic winner but a modular, interoperable ‘Linux of AI’, an ecosystem composed of distinct, best-in-class components that become standards at their respective layers.
The enduring power and economic value of the AI revolution are accumulating within the open-source stack that brings models to life. The companies and communities that build and control these key components will not only capture immense value but will also shape the very future of artificial intelligence.
The war for the stack is the real war for AI’s future.
Parminder Singh, Founder of Redscope.ai, has 15+ years building and scaling startups across the India–US corridor, including Hansel.io (acquired by NetcoreCloud.com) and Scaler.com’s US expansion. His work, recognized by Gartner, YourStory, and Nasscom, now continues at Redscope.ai, where he is redefining conversion rate optimization with agentic AI and real-time personalization.



