
Since the global acceleration of fascination with AGI development, the dominant philosophy of reaching it has been centred on traditional scaling laws. Increasing model size and data to drive AI performance has long been the accepted method. While it is undeniable that this approach has yielded remarkable, previously unthinkable breakthroughs, it is also becoming increasingly clear that it is not sustainable nor the right approach to reach the next frontier. Diminishing returns and skyrocketing compute costs are pushing the field towards more efficient and innovative scaling strategies. The next phase of AI has to shift from raw parameter growth to inference-time optimisation, multi-agent collaboration, and dynamic compute allocation. This evolution is crucial for ensuring AI’s scalability and accessibility at a local level whilst preserving the user’s right to privacy, enabling its integration into real-world applications where efficiency and adaptability are paramount.
The traditional scaling approach in AI development, exemplified by Kaplan Scaling Laws and Chinchilla Scaling, has shown that model performance improves predictably with more parameters and training data. But it’s not perfect. Compute constraints make training massive models brutally expensive, and diminishing returns are evident as performance gains slow down with larger models. The relationship between data volume and model performance follows a logarithmic curve, with improvements becoming sub-logarithmic as data volume expands.
To address the limitations of traditional AI scaling, researchers are focusing on inference-time optimisation, which would move away from fixed compute quotas to a more dynamic and efficient approach. At the moment, any massive model has to be trained on centralised compute first, but in the long run, a focus on eventual long-term pivoting away from centralised models has proven to be fruitful and efficient. Additionally, input-specific scaling dynamically adjusts compute usage based on input complexity.
For instance, a language model might quickly return a single, confident response for a simple factual query, while allocating more resources to generate multiple samples for a challenging maths problem. We employ various techniques to improve efficiency, such as quantisation & pruning, which offer significant efficiency gains by reducing the precision of model weights and removing redundant parameters. One additional technique to note is self-refinement and iterative processing, which enable models to iteratively refine their outputs, allowing for adaptive compute allocation based on task difficulty. This approach enhances accuracy while ensuring compute is used judiciously, focusing resources where they’re most needed.
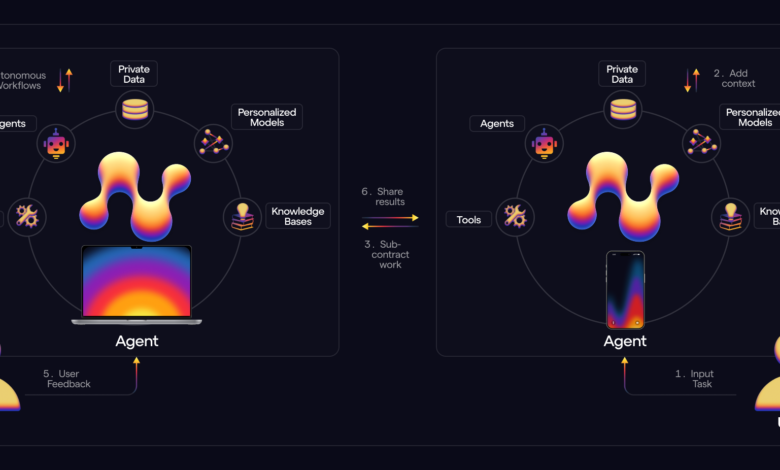
We have observed that multi-agent AI systems are emerging as a promising paradigm shift in AI development, offering several advantages over traditional single-agent models. This approach involves multiple specialised AI agents collaborating to solve complex tasks, addressing the limitations of monolithic models and enhancing overall system performance. Different agents can excel at specific sub-tasks, leading to improved overall performance. For instance, in a language processing system, one agent might focus on grammar, another on context, and a third on sentiment analysis. We are working at further increasing the distribution of compute across agents, which will further reduce overhead, making it easier to reach the industry goal of scaling agents. This scalability is particularly beneficial as it allows systems to handle complex tasks without the need to retrain entire models. Additionally, multi-agent systems can optimise resource utilisation, enhance adaptability, and improve robustness by ensuring that if one agent fails, others can continue functioning or take over tasks.
We have been working on two research programmes alongside our most recent launch. The first being systems of agents that perform red teaming on other agents, testing the strength of the system architecture and its jailbreaking defences. The second is another project with systems of researcher agents, akin to Google and ChatGPT Deep Research, that collaborate on tasks. Both of these projects have stemmed from grants we have delivered to independent researchers to support AI development – something we believe is pivotal for strong growth of the ecosystem from the ground up.
As we look forward, we see a future where AI scaling is not simply about making models bigger, but making them smarter. Those betting on the future of AGI development tools should expect a hybrid approach, combining inference-time optimisation, and multi-agent systems for real-world efficiency. The future of AI may not be monolithic, dominated by a single, massive model, but rather by intelligent systems that can efficiently coordinate multiple specialised agents to tackle complex real-world problems.


