In the age of AI, the difference between pioneers and laggards hinges on the robustness of their AI and data architecture. Frances Karamouzis, Distinguished VP Analyst at Gartner, has recently shined a light on the staggering $75 billion in sales of the AI software market, a testament to the sector’s vitality and growing business importance. While 2023 was a tentative dance with AI’s possibilities, 2024 heralds a period of action where 21% of organizations have already escalated their AI projects into full production.
This fact puts all organizations under pressure to deliver palpable outcomes and justify their increased investments. This transition is not without its perils, as heightened expectations meet a market bracing for upheaval and potential setback—what Gartner calls the ‘trough of disillusionment.’ It is for this reason a time for sobering recalibration, where only the fittest AI endeavors, backed by strategic insight and rigorous governance, thrive. The cornerstone of success for the vanguard is a deliberate approach to architecting AI solutions that delivers not just data-driven insights, but also real-world impact and innovation that aligns with the trajectory of growing business needs. So, what do successful organization do to architect AI Solutions that deliver real business value?
Set a Purpose + Align the Organization
In the crucible of market competition, it is imperative to have a deep understanding of the levers of value—not just where to look for value but how to harness it effectively. Increasingly, this is about leveraging AI to carve out competitive advantage by focusing on industry-specific applications. Karamouzis highlights a strategic triad for defining AI’s impact: defense of established markets, expansion of current offerings, and disruption of the status quo.
Yet, a telling statistic reveals a conservative tilt, with 80% of AI efforts aimed at defending and extending, favoring productivity as their linchpin versus real digital transformation. At the same time, it is important to note that customer engagement stands as the leading AI application, accounting for a significant 42% of initiatives, outstripping IT’s 31%, and indicating a trend where direct interaction takes precedence.
David De Cremer’s forthcoming book, “The AI Savvy Leader,” posits the conundrum leaders face: a dual mandate to adapt and simultaneously comprehend the very phenomena to which they’re adapting to. This calls for alignment between corporate purpose and AI comprehension. Failure to bridge this gap, as De Cremer underscores, means that AI projects may miss the mark.
Leaders must ensure initiatives resonate with their organization’s core value proposition and ask pertinent questions of the data models created. Echoing this sentiment, Eric Siegel in “The AI Playbook” contends that a well-articulated value proposition for data initiatives is non-negotiable. It’s about crystalizing the
predictive power of data, translating it into business-enhancing metrics such as reduced customer churn or precise cost reductions. This is not merely about setting targets but crafting a roadmap to achieve real commercial victories.
Creating AI-Ready Data
Data is without question the lifeblood of AI, yet its mere existence doesn’t equate to readiness for the analytical rigor AI demands. Siegel spotlights a common oversight: data may abound, yet it’s seldom primed for the discerning eyes of machine learning or generative AI algorithms. This echoes the sentiment in “Rewired,” where it’s stressed that a staggering 70% of AI development effort is devoted to the laborious tasks of data wrangling and harmonization. AI readiness involves refining data into a state of utility—clean, pertinent, and at the ready.
But AI-ready data doesn’t simply materialize—it is crafted with intention. Coined by Gartner, the term “AI Ready Data” implies a manufacturing process, industrialization of data, as Stephanie Woerner of MIT-CISR phrases it. What should the aspiration be? It should be to forge data into a single, trustworthy source of truth that empowers decision-making throughout an organization. This necessitates data that is not just accessible and usable but also adheres to stringent criteria of accuracy, timeliness, and security. For firms vying to be at the forefront of AI innovation, the quest is clear: create data repositories that are not just repositories but beacons of insight—data that both people and AI can rely upon with conviction.
AI-ready data is created by validating data accuracy, cross-referencing data entities, and unifying disparate data into a coherent stream. With this, organizations can harness their data management prowess to not only automate quality controls but also pinpoint and orchestrate data sources and flows. This dance includes the choreography of establishing standard definitions and metadata for prioritized organizational data fields.
Integrating and curating data then becomes a performance of harmonizing sources and standards, aligning and merging fields to create a seamless flow. This is about sculpting data with an artisan’s touch into a form that’s not just analyzable but meaningful and accessible to its intended audience. With this accomplished, data engineers and product managers can package all these efforts into consumable and functional data products. These products stand as testaments to an organization’s ability to transform raw data into a refined asset, ready for the discerning algorithms of AI to engage with effectively.
Putting the Pieces Together
In the quest to harness the transformative power of AI, it makes sense to envision an ‘AI factory’, a concept championed by the authors of “Competing in the Age of AI.” This factory is the nexus where data gathering, analytics, and decision-making processes are
streamlined into an assembly line of intelligence. The envisioned outcome is a self-reinforcing cycle: user interactions fuel data collection, feeding algorithms that yield predictions, which in turn refine and enhance further engagement and data quality.
Creating such a factory mandates the construction of three pillars: a robust data pipeline that ensures a ceaseless flow of information, an environment conducive to agile algorithm development, and a sturdy infrastructure to underpin the entire operation. This framework is not static but dynamic, shifting seamlessly from trial runs to full-fledged deployment. It’s a domain where traditional data modeling—spanning supervised, unsupervised, and reinforcement learning—converges with the cutting-edge realm of generative AI. The glue binding these elements is a modern data stack, capable of lifting an organization into the new era of AI-driven competition.
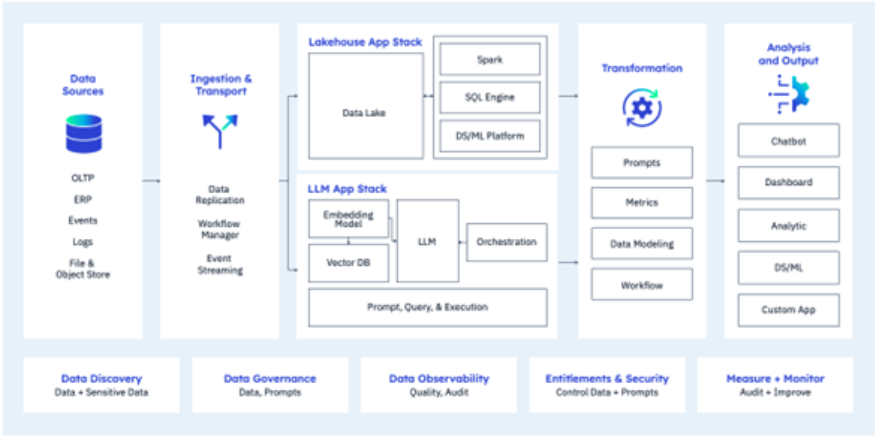
The evolution of data architecture is a tale of relentless innovation, culminating in the modern data stack—an integrated suite of systems that serves as the backbone of a contemporary data strategy. As outlined by Bornstein, Li, and Casado at Andreessen Horwitz, this stack transcends traditional boundaries, marrying data lakes and generative AI within a framework that operates both in concert and isolation. Please note that I have added to their original diagram. The composite diagram shown above represents an orchestra of technology playing a symphony of end-to-end processes: from source to ingestion, storage to query, and from transformation to the final crescendo of analysis and output.
This stack isn’t just about data flow; it’s about oversight and control. The additions above consider enhanced data discovery and a ‘measure and manage’ layer brings a new dimension of meticulousness to the stack, essential for DevOps and DataOps methodologies. With governance ensuring that prompts and data maintain integrity, and a focus on sensitive data within large language models, the stack becomes not just a tool,
but a guardian of quality and confidentiality. Around this should be an airtight seal of entitlements and security that should wrap around every data byte, whether it resides in lakes or vector databases. The compositive goal for a modern data stack is ensuring that from discovery to delivery, the data stack remains modern not just in name, but in its very essence.
Governing: Engendering Trust and Securing
In today’s era, trust is not merely a value—it’s a strategic asset, painstakingly cultivated through proven reliability and rigorous governance frameworks. Governance ensures data is not just useful for the moment but is a reusable asset aligned with risk and regulatory frameworks.
The bedrock of this process lies in robust definitions, unerring monitoring of data quality, and the impermeable bulwark of security and trust. This necessitates crafting expansive trust policies that govern data usage, analytics, and the technological substrate within which they operate, embedding control functions deep into the data’s lifecycle, and innovating with automated risk controls that activate in tandem with the creation of data products.
The strategic discourse of unified versus native controls is critical to have. This underscores the necessity for automated, integrated controls for seamless and secure data management. Systemic automation not only scales efficiency but also nurtures a superior architectural and governance fabric, propelling organizations toward a more unified and automated approach to data stewardship. In securing a lakehouse, policy, and control creation and sensitive metadata scanning across cloud ecosystems are imperative.
In contrast, generative AI demands securing training data and model inputs/outputs, alongside enforcing stringent privacy controls over vector databases. The convergence of comprehensive compliance monitoring with DataOps methodologies for both realms signifies a harmonious marriage between compliance and operational agility, shaping the future of secure data management in an increasingly complex digital landscape.
Parting Thoughts
Trust, governance, and security are essential for safeguarding and optimizing the burgeoning spheres of data lakes and generative AI. At the heart of engendering trust within a business lies a firm commitment to data governance, ensuring that data is not only reliable but also meets rigorous risk and regulatory requirements. This commitment is manifested through comprehensive data trust policies, control functions, and an emphasis on automated risk controls.
The debate on unified vs. native controls highlights the strategic necessity of integrated, comprehensive, and automated solutions to create a streamlined and secure data management ecosystem. Such systemic approaches not only bolster efficiency but also fortify the architecture and governance of digital enterprises. In this complex terrain,
securing data involves creating robust policies, especially for sensitive information, whether it’s housed in a data lakehouse or utilized within generative AI processes. The overarching aim is to establish a cohesive compliance monitoring system that marries the agility of DataOps approaches with the thoroughness of compliance requirements, thus ensuring data across all platforms is both protected and potent.